首页 >
热门文章 >
大数据分析 > 大数据分析面试题库—基本大数据Hadoop面试问题
大数据分析面试题库—基本大数据Hadoop面试问题
时间:2019-12-27来源:www.aaa-cg.com.cn点击量:次作者:Sissi
时间:2019-12-27点击量:次作者:Sissi
之前我分享过《大数据分析面试题库—基本的大数据分析面试问题》、《大数据分析面试题库-有经验的大数据分析面试问题》,《Hadoop在大数据分析中的意义和作用》、《大数据分析与Hadoop区别和联系》,Hadoop是最受欢迎的大数据分析框架之一,如果您打算进行Hadoop面试,请准备好这些有关大数据分析Hadoop的基本面试问题。无论您打算进行Hadoop开发人员还是Hadoop管理员面试,这些问题都会对您有所帮助。
21.解释Hadoop和RDBMS之间的区别。
答: Hadoop和RDBMS之间的区别如下
22. Hadoop中常见的输入格式是什么?
答:以下是Hadoop中的常见输入格式
文本输入格式– Hadoop中定义的默认输入格式是文本输入格式。
序列文件输入格式–要读取序列中的文件,请使用序列文件输入格式。
键值输入格式–用于纯文本文件(分成几行的文件)的输入格式是键值输入格式。
23.解释Hadoop的一些重要功能。
答: Hadoop支持大数据分析的存储和处理。它是应对大数据分析挑战的最佳解决方案。Hadoop的一些重要功能是–
开源– Hadoop是一个开源框架,这意味着它是免费提供的。同样,允许用户根据他们的要求更改源代码。
分布式处理– Hadoop支持数据的分布式处理,即更快的处理。Hadoop HDFS中的数据以分布式方式存储,而MapReduce负责数据的并行处理。
容错– Hadoop具有高度的容错能力。默认情况下,它将为每个块在不同节点上创建三个副本。该编号可以根据需要进行更改。因此,如果一个节点发生故障,我们可以从另一节点恢复数据。节点故障的检测和数据恢复是自动完成的。
可靠性– Hadoop以可靠的方式将数据存储在群集上,而与计算机无关。因此,存储在Hadoop环境中的数据不受计算机故障的影响。
可伸缩性– Hadoop的另一个重要功能是可伸缩性。它与其他硬件兼容,我们可以轻松地将新硬件装配到节点上。
高可用性–即使在硬件出现故障之后,也可以访问存储在Hadoop中的数据。如果发生硬件故障,可以从其他路径访问数据。
24.解释Hadoop运行的不同模式。
答: Apache Hadoop在以下三种模式下运行–
独立(本地)模式–默认情况下,Hadoop以本地模式运行,即在非分布式单节点上运行。此模式使用本地文件系统执行输入和输出操作。此模式不支持使用HDFS,因此用于调试。在这种模式下,配置文件不需要自定义配置。
伪分布式模式–在伪分布式模式下,Hadoop与独立模式一样在单个节点上运行。在这种模式下,每个守护程序都在单独的Java进程中运行。由于所有守护程序都在单个节点上运行,因此主节点和从节点都存在相同的节点。
完全分布式模式–在完全分布式模式下,所有守护程序都在单独的单个节点上运行,因此形成了多节点集群。主节点和从节点有不同的节点。
25.解释Hadoop的核心组件。
答: Hadoop是一个开源框架,旨在以分布式方式存储和处理大数据分析。Hadoop的核心组件是–
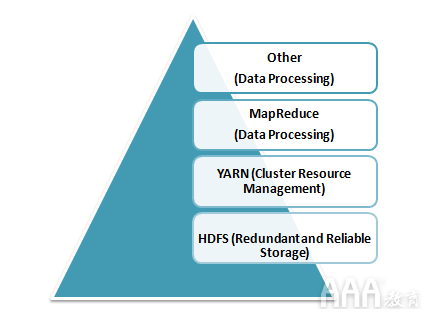
HDFS(Hadoop分布式文件系统)– HDFS是Hadoop的基本存储系统。在商用硬件群集上运行的大型数据文件存储在HDFS中。即使硬件出现故障,它也可以以可靠的方式存储数据。
Hadoop的核心组件
Hadoop MapReduce – MapReduce是负责数据处理的Hadoop层。它编写一个应用程序来处理存储在HDFS中的非结构化和结构化数据。通过将数据划分为独立的任务,它负责并行处理大量数据。该处理过程分为Map和Reduce两个阶段。映射是指定复杂逻辑代码的处理的第一阶段,而精简是指定轻量级操作的处理的第二阶段。
YARN – Hadoop中的处理框架是YARN。它用于资源管理,并提供多个数据处理引擎,即数据科学,实时流和批处理。
26.“ MapReduce”程序中的配置参数是什么?
“ MapReduce”框架中的主要配置参数为:
1)作业在分布式文件系统中的输入位置
2)作业在分布式文件系统中的输出位置
3)数据输入格式
4)数据输出格式
5)包含map函数的类
6)包含reduce函数的类
7)JAR文件,其中包含映射器,reducer和驱动程序类
27. HDFS中的块是什么,在Hadoop 1和Hadoop 2中其默认大小是多少?我们可以更改块大小吗?
块是硬盘中最小的连续数据存储。对于HDFS,块跨Hadoop群集存储。
Hadoop 1中的默认块大小为:64 MB
Hadoop 2中的默认块大小为:128 MB
是的,我们可以使用hdfs-site.xml文件中的参数dfs.block.size 更改块大小。
28.什么是MapReduce框架中的分布式缓存
分布式缓存是Hadoop MapReduce框架的一项功能,用于缓存应用程序的文件。Hadoop框架使缓存文件可用于数据节点上运行的每个映射/减少任务。因此,数据文件可以在指定作业中作为本地文件访问缓存文件。
29. Hadoop的三种运行模式是什么?
Hadoop的三种运行模式如下:
一世。独立或本地:这是默认模式,不需要任何配置。在这种模式下,Hadoop的以下所有组件均使用本地文件系统,并在单个JVM上运行:
1、名称节点
2、数据节点
3、资源管理器
4、节点管理器
伪分布式:在这种模式下,所有主和从Hadoop服务都在单个节点上部署和执行。
完全分布式:在这种模式下,Hadoop主服务和从服务在单独的节点上部署和执行。
30.在Hadoop中解释JobTracker
JobTracker是Hadoop中的JVM流程,用于提交和跟踪MapReduce作业。
JobTracker按顺序在Hadoop中执行以下活动–
JobTracker接收客户端应用程序提交给作业跟踪器的作业
JobTracker通知NameNode确定数据节点
JobTracker根据可用的插槽分配TaskTracker节点。
它在分配的TaskTracker节点上提交工作,
JobTracker监视TaskTracker节点。
任务失败时,将通知JobTracker并决定如何重新分配任务。


 热门推荐
热门推荐
 UI设计
UI设计
 产品经理
产品经理
 大数据分析
大数据分析
 原画设计
原画设计
 平面设计
平面设计
 新媒体运营
新媒体运营 






