全力以赴地进入数据集是从事数据科学工作的任何人的使命之一。通常,这意味着要进行数字运算,但是当我们的数据集主要基于文本时,我们该怎么办?我们可以使用正则表达式。在本教程中,我们将仔细研究如何在Python中使用正则表达式(regex)。
正则表达式(regex)本质上是文本模式,可用于自动搜索和替换文本字符串中的元素。这可以使清理和使用基于文本的数据集变得更加容易,从而省去了手动搜索大量文本的麻烦。
正则表达式可以在多种编程语言中使用,并且已经存在很长时间了!
不过,在本教程中,我们将学习Python中的正则表达式,因此需要基本熟悉关键的Python概念,例如if-else语句,while和for循环等。在本教程结束时,您将熟悉Python regex的工作原理,并能够使用Python regex模块中的基本模式和功能re来分析文本字符串。您还将获得有关正则表达式如何与熊猫配合使用以处理大型文本语料库的介绍。
让我们深入研究有关每个人最不喜欢的电子邮件类型的一些数据:垃圾邮件和欺诈。
我们的任务:分析垃圾邮件
在本教程中,我们将使用Kaggle的欺诈电子邮件语料库。它包含1998年至2007年之间发送的数千种网络钓鱼电子邮件。它们非常有趣,易于阅读。
您可以在这里找到完整的语料库。但是,我们将从使用一些电子邮件学习基本的正则表达式命令开始。如果需要,您也可以使用我们的测试文件,也可以在完整的语料库中尝试使用。
介绍Python的Regex模块

首先,我们将通过打开测试文件,将其设置为只读并读取来准备数据集。我们还将其分配给变量fh(用于“文件句柄”)。
请注意,我们在目录路径之前加r。此技术将字符串转换为原始字符串,这有助于避免某些机器读取字符的方式引起的冲突,例如Windows上目录路径中的反斜杠。
现在,假设我们要找出电子邮件的来源。我们可以自己尝试使用原始Python:
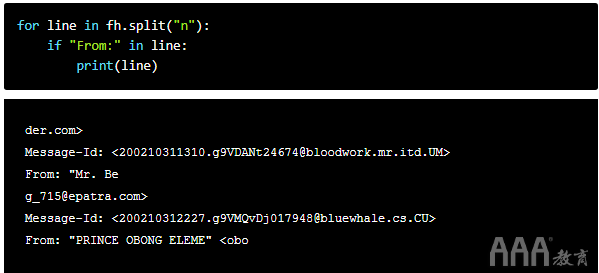
但这并没有给我们确切的需求。如果您看一下我们的测试文件,我们可以找出原因并修复它,但是,让我们使用Python的re模块并使用正则表达式来做吧!
我们将从导入Python的re模块开始。然后,我们将使用一个名为的函数re.findall(),该函数返回在正在查看的字符串中定义的模式的所有实例的列表。
外观如下:
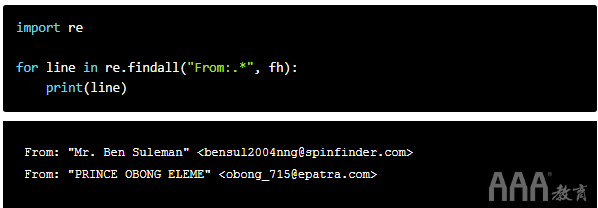
这与原始Python的长度基本相同,但这是因为这是一个非常简单的示例。您尝试做的越多,Python正则表达式就可以为您节省更多的精力。
在继续之前,让我们仔细看看re.findall()。此函数采用形式为的两个参数re.findall(pattern, string)。在这里,pattern代表我们要查找的子字符串,并string代表我们要在其中查找的主字符串。主字符串可以包含多行。在这种情况下,我们让它fh使用选定的电子邮件来搜索所有文件。
该.*是一个字符串模式的简写。正则表达式通过使用这些速记模式来查找文本中的特定模式而起作用,因此让我们看一下其他一些常见示例:
常见的Python正则表达式模式
我们re.findall()上面使用的模式包含一个完整拼写的字符串"From:"。当我们确切地知道我们要查找的内容(精确到实际字母以及它们是否为大写或小写)时,这很有用。如果我们不知道我们想要的字符串的确切格式,我们将会迷路。幸运的是,正则表达式具有解决此情况的基本模式。让我们看看在本教程中使用的那些:
1)w匹配字母数字字符,表示az,AZ和0-9。它还与下划线_和破折号-相匹配。
2)d 匹配数字,表示0-9。
3)s 匹配空白字符,包括制表符,换行符,回车符和空格字符。
4)S 匹配非空格字符。
5).匹配除换行符外的任何字符n。
掌握了这些正则表达式模式后,您将在继续进行解释的同时快速理解上面的代码。
使用正则表达式模式
现在,我们可以.*在re.findall("From:.*", text)上面的行中解释的用法。让我们.先来看:
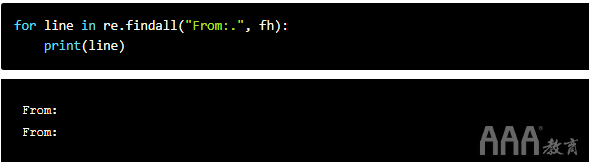
通过在.旁边添加一个From:,我们可以在其旁边查找另一个字符。因为.查找除以外的任何字符n,所以它捕获了我们看不到的空格字符。我们可以尝试更多的点来验证这一点。
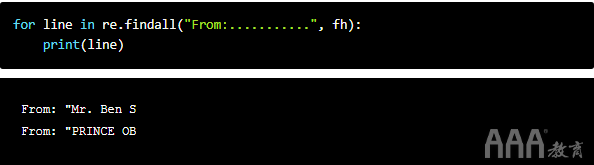
看起来加点确实为我们获得了线的其余部分。但是,这很繁琐,而且我们不知道要添加多少点。这是星号符号*出现的位置。
*匹配模式左侧的零个或多个实例。这意味着它将寻找重复模式。当我们寻找重复的模式时,我们说搜索是“贪婪的”。如果我们不寻找重复的模式,则可以将搜索称为“非贪婪”或“懒惰”。
让我们构建一个贪婪的搜索.用*。
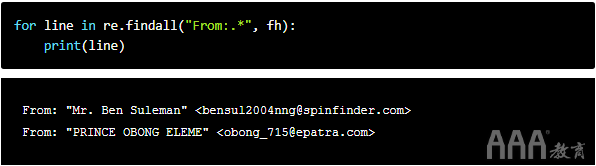
因为*匹配在其左侧指示的模式的零个或多个实例,并且.位于此处的左侧,所以我们能够获取From:字段中的所有字符,直到行尾。这将用精美简洁的代码打印出整行。
我们甚至可以更进一步,仅隔离名称。让我们使用它re.findall()来返回包含模式的行列表,"From:.*"就像之前一样。match为了整洁,我们将其分配给变量。接下来,我们将遍历列表。在每个循环中,我们将re.findall再次执行,匹配第一个引号以仅选择名称:

注意,我们在第一个引号旁边使用了反斜杠。反斜杠是一个特殊字符,用于转义其他特殊字符。例如,当我们想将引号用作字符串文字而不是特殊字符时,可以使用反斜杠将其转义,例如:\"。如果我们不使用反斜杠转义上面的模式,它将变为"".*"",Python解释器将其读取为两个空字符串之间的句点和星号。它将产生错误并破坏脚本。因此,至关重要的是我们在这里用反斜杠将引号引起来。
匹配第一个引号后,.*获取行中的所有字符,直到下一个引号也被转义为模式。这使我们得到的名称只是带引号的名称。该名称也打印在方括号中,因为re.findall返回的匹配项在列表中。
如果我们想要电子邮件地址怎么办?
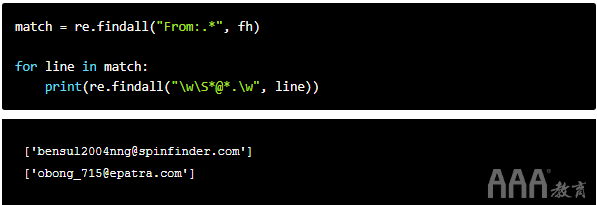
看起来很简单,不是吗?仅模式不同。让我们来看一看。
这是我们仅匹配电子邮件地址的前部分的方式:
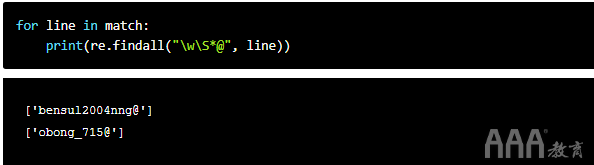
电子邮件总是包含一个@符号,因此我们从它开始。电子邮件中@符号前的部分可能包含字母数字字符,这w是必需的。但是,由于某些电子邮件包含句点或破折号,所以这还不够。我们添加S以查找非空白字符。但是,w\S只会得到两个字符。添加*以查找重复。因此,模式的前部如下所示:\w\S*@。
现在查看@符号后面的模式:
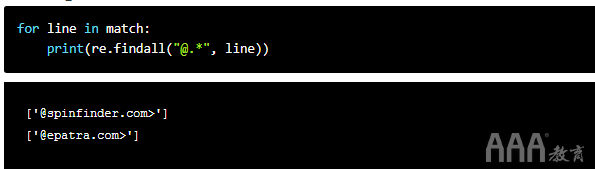
域名通常包含字母数字字符,句点和短划线,因此a .可以。为了使它更贪婪,我们使用扩展了搜索范围*。这使我们可以匹配任何字符,直到行尾。
如果我们仔细观察这条线,会发现每封电子邮件都封装在尖括号<和>中。我们的模式.*包括右括号>。让我们对其进行补救:
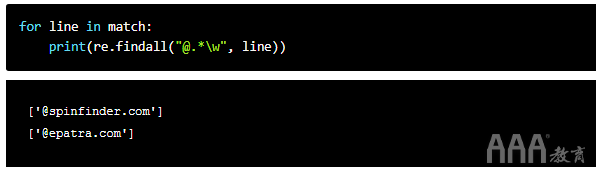
电子邮件地址以字母数字字符结尾,因此我们将模式设置为w。因此,在@符号后面有.*\w,这表示我们想要的模式是一组以字母数字字符结尾的任何类型的字符。不包括>。
因此,我们的完整电子邮件地址格式如下所示:\w\S*@.*\w。
!这需要花费很多时间。接下来,我们将介绍一些通用re功能,这些功能在开始重新组织语料库时将非常有用。
常用的Python正则表达式函数
re.findall()无疑是有用的,但它不是我们可以使用的唯一内置函数re:
1)re.search()
2)re.split()
3)re.sub()
在使用它们为我们的数据集添加一些顺序之前,让我们一一看一下。
研究()
While re.findall()匹配字符串中某个模式的所有实例并在列表中返回它们,re.search()匹配字符串中一个模式的第一个实例,并将其作为re匹配对象返回。
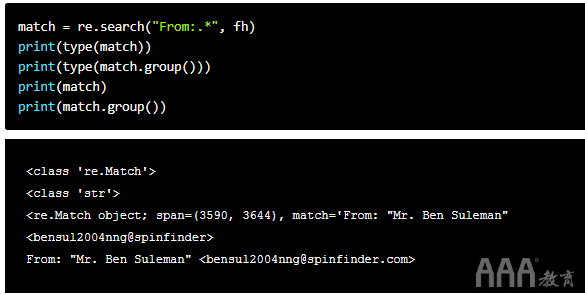
像一样re.findall(),re.search()也有两个参数。第一个是要匹配的模式,第二个是要在其中找到模式的字符串。在这里,我们将结果分配给match变量以保持整洁。
由于re.search()返回re匹配对象,因此无法通过直接打印来显示名称和电子邮件地址。相反,我们必须首先对该group()函数应用该函数。我们已经在上面的代码中打印了这两种类型。如我们所见,group()将match对象转换为字符串。
我们还可以看到,打印match显示的属性超出字符串本身,而打印match.group()仅显示字符串。
re.split()
假设我们需要一种快速的方法来获取电子邮件地址的域名。我们可以通过三个正则表达式操作来做到这一点,如下所示:
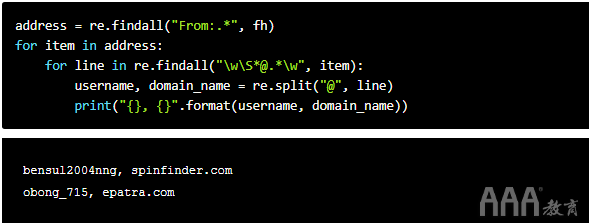
第一行很熟悉。我们返回一个字符串列表,每个字符串包含From:字段的内容,并将其分配给变量。接下来,我们遍历列表以查找电子邮件地址。同时,我们循环访问电子邮件地址,并使用该re模块的split()功能将每个地址切成两半,用@符号作为分隔符。最后,我们打印它。
re.sub()
另一个方便的re功能是re.sub()。就像函数名称所暗示的那样,它替换字符串的一部分。一个例子:
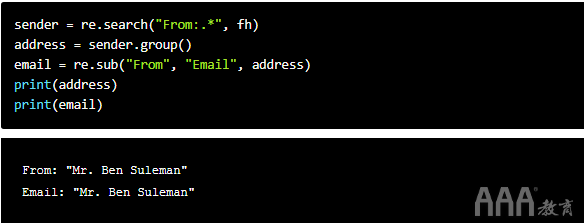
我们之前已经在第一行和第二行看到了任务。在第三行,我们re.sub()在上应用address,这是From:电子邮件标题中的完整字段。
re.sub()需要三个参数。第一个是要替换的子字符串,第二个是我们要替换的字符串,第三个是主字符串本身。
正则表达式与pandas
现在,我们掌握了Python正则表达式的基础知识。但是通常对于数据任务,我们实际上并没有使用原始的Python,而是使用了pandas库。现在,将我们的正则表达式技能带入熊猫工作流程,将其提升到一个新的水平。
如果您以前从未使用过熊猫,请不要担心。我们将逐步遍历代码,以免您迷路。但是,如果您想更详细地了解熊猫,请查看我们的熊猫教程或我们提供的有关numpy和熊猫的完全交互式课程。
使用Python Regex和Pandas对电子邮件进行排序
我们的语料库是一个包含数千封电子邮件的单个文本文件(不过,同样,在本教程中,我们使用的是一个只有两个电子邮件的较小文件,因为在整个语料库上打印正则表达式工作的结果会使这篇文章过长)。
我们将使用正则表达式和熊猫将每封电子邮件的各个部分分类为适当的类别,以便可以更轻松地阅读或分析语料库。
我们将每封电子邮件分为以下类别:
1)sender_name
2)sender_address
3)recipient_address
4)recipient_name
5)date_sent
6)subject
7)email_body
这些类别中的每一个都将成为我们的熊猫数据框(即我们的表格)中的一列。这将使我们更轻松地分别处理和分析每个列。
我们将继续处理我们的小样本,但是值得重申的是,正则表达式使我们可以编写更简洁的代码。简洁的代码减少了我们的机器必须执行的操作数量,从而加快了我们的分析过程。使用我们的两封电子邮件的小文件,并没有太大的区别,但是,如果您尝试使用和不使用正则表达式来处理整个语料库,您将开始看到其优势!
准备脚本
首先,让我们导入所需的库,然后再次打开文件。
除了re和之外pandas,我们email还将导入Python的软件包,这将有助于电子邮件的正文。仅使用正则表达式时,电子邮件的主体相当复杂。它甚至可能需要足够的清理才能保证有自己的教程。因此,我们将使用完善的email软件包来节省一些时间,让我们专注于学习正则表达式。
我们还创建了一个空列表emails,用于存储字典。每本词典将包含每封电子邮件的详细信息。
现在,让我们开始应用正则表达式!
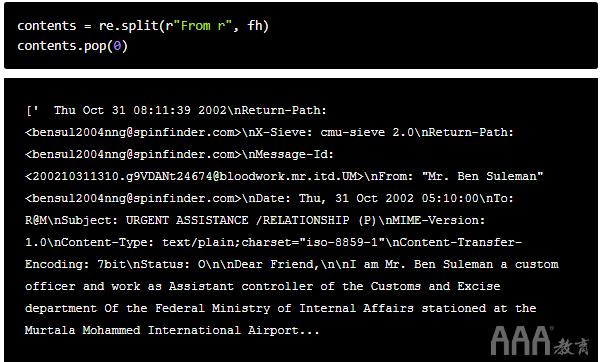
注意:为简洁起见,我们剪裁了上面的打印输出。如果您在自己的机器上打印此文件,它将显示其中包含的所有内容,contents而不是...像上面那样结束。
我们使用re模块的split函数将整个文本块分割fh为单独的电子邮件列表,然后将其分配给变量contents。这很重要,因为我们希望通过使用for循环遍历列表来逐一处理电子邮件。但是,我们如何知道按字符串分割"From r"?
我们之所以知道这一点,是因为在编写脚本之前我们已经查看了文件。我们不必细读其中的数千封电子邮件。只是前几个,看看数据的结构是什么样子。只要有可能,最好在开始使用代码之前先关注实际数据,因为您经常会发现诸如此类的有用功能。
我们已经截取了原始文本文件的屏幕截图:
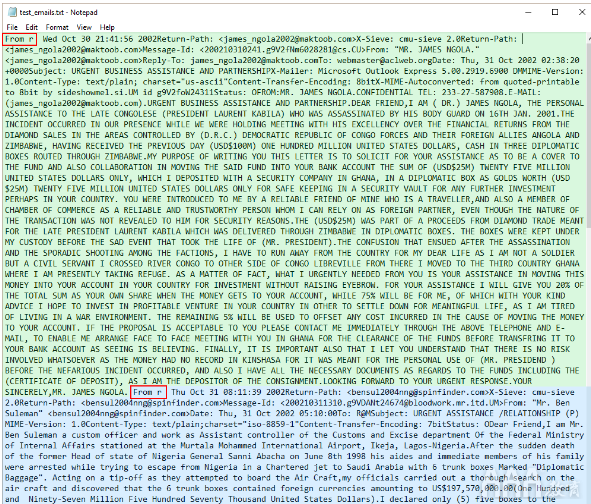
电子邮件以“ From r”开头
绿色方框是第一封电子邮件。蓝色方框是第二封电子邮件。如我们所见,这两封电子邮件均以开头"From r",并以红色框突出显示。
我们在本教程中使用欺诈电子邮件语料库的原因之一是,当数据杂乱无章,不熟悉且没有文档时,我们不能仅仅依靠代码来整理数据。这将需要一双人眼。正如我们刚刚显示的,我们必须研究语料库本身以研究其结构。
像这样杂乱无章的数据可能需要大量清理。例如,即使我们使用本教程将要构建的完整脚本来计算此集合中的3977封电子邮件,但实际上还有更多。某些电子邮件实际上并不以开头"From r",因此不会单独计算。(不过,为了简洁起见,我们将继续处理该问题,并用分隔所有电子邮件"From r"。)
还要注意,我们contents.pop(0)用来摆脱列表中的第一个元素。这是因为"From r"字符串在第一封电子邮件之前。拆分该字符串后,它将在索引0处生成一个空字符串。我们将要编写的脚本是为电子邮件设计的。如果我们尝试在空字符串上使用它,则可能会引发错误。摆脱空字符串可以使我们避免破坏脚本。
使用For循环获取每个名称和地址
接下来,我们将使用contents列表中的电子邮件。

在上面的代码中,我们使用for循环来遍历,contents因此我们可以依次处理每封电子邮件。我们创建了一个词典,emails_dict其中包含每封电子邮件的所有详细信息,例如发件人的地址和姓名。实际上,这些是我们发现的第一批物品。
这是一个三步过程。首先从寻找From:领域开始。
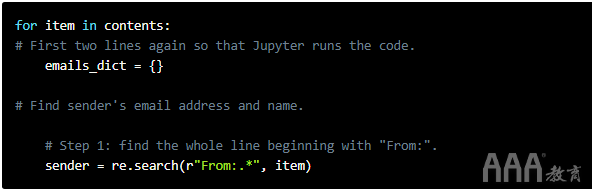
在第1步中,我们From:使用re.search()函数查找整个字段。该.装置除了任何字符n,并且*其延伸到行的结尾。然后,我们将其分配给变量sender。
但是,数据并不总是那么简单。它可能包含惊喜。例如,如果没有From:字段怎么办?该脚本将引发错误并中断。我们在步骤2中避免了这种情况下的错误。
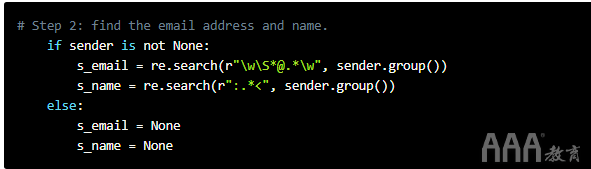
为了避免由于缺少From:字段而导致的错误,我们使用一条if语句来检查sendernot None。如果是,我们分配s_email和s_name的值,None以便脚本可以继续运行而不是意外中断。
如果您在自己的文件中使用本教程,则可能已经意识到使用正则表达式会变得混乱。例如,这些if-else语句是在编写主体时对主体使用反复试验的结果。编写代码是一个反复的过程。值得注意的是,即使本教程看起来很简单,实际实践也需要进行更多的实验。
在第2步中,我们使用之前的regex模式\w\S*@.*\w,该模式与电子邮件地址匹配。
我们将对名称使用其他策略。每个名称都由左侧:子字符串的冒号()"From:"和<右侧电子邮件地址的左尖括号()界定。因此,我们使用它:.*<来查找名称。我们摆脱:并<从每个结果的时刻。
现在,让我们打印出代码的结果以查看它们的外观。
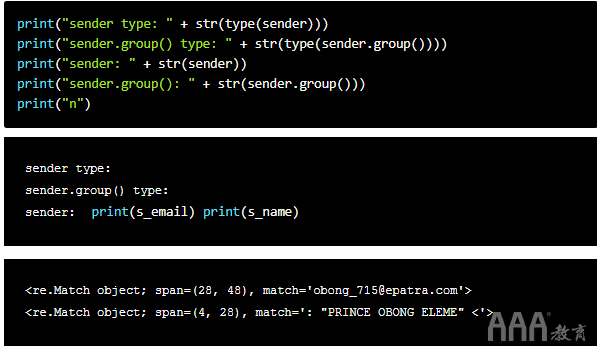
同样,我们有匹配对象。每次我们将re.search()字符串应用于字符串时,都会生成匹配对象。我们必须将它们变成字符串对象。
我们这样做之前,记得,如果没有From:现场,sender将具有的价值None,因此也将s_email和s_name。因此,我们必须再次检查这种情况,以便脚本不会意外中断。让我们看看如何首先构建代码s_email。
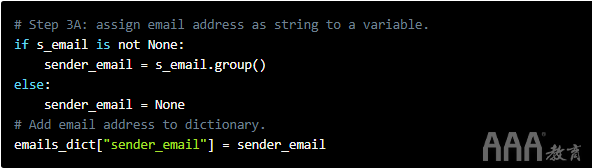
在步骤3A中,我们使用一条if语句检查s_emailnot None,否则它将引发错误并破坏脚本。
然后,我们只需将s_emailmatch对象转换为字符串并将其分配给sender_email变量。我们将其添加到emails_dict字典中,这将使我们日后将细节转换为pandas数据框变得异常容易。
我们s_name在步骤3B中所做的几乎完全相同。
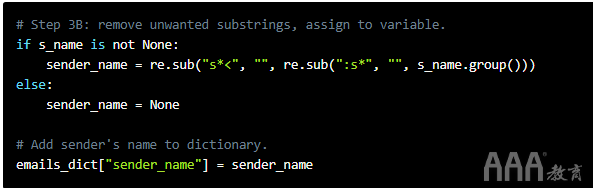
正如我们以前那样,我们首先检查s_name是不是None在步骤3B。
然后,在将字符串分配给变量之前,我们两次使用re模块的re.sub()函数。首先,我们删除冒号和它与名称之间的所有空白字符。我们:s*用一个空字符串代替""。然后,我们删除空格字符和名称另一边的尖括号,再次用空字符串替换它。最后,在将字符串分配给之后sender_name,我们将其添加到字典中。
让我们检查一下结果。

完善。我们已经隔离了电子邮件地址和发件人的姓名。我们还将它们添加到字典中,该字典将很快投入使用。
现在我们已经找到了发件人的电子邮件地址和名称,我们将执行完全相同的步骤来获取字典的收件人的电子邮件地址和名称。
首先,我们找到To:领域。

接下来,我们抢先在场景recipient是None。
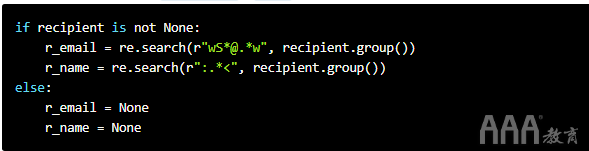
如果recipient不是None,则用于re.search()查找包含电子邮件地址和收件人姓名的匹配对象。否则,我们传递r_email和r_name的值None。
然后,将匹配对象转换为字符串并将其添加到字典中。
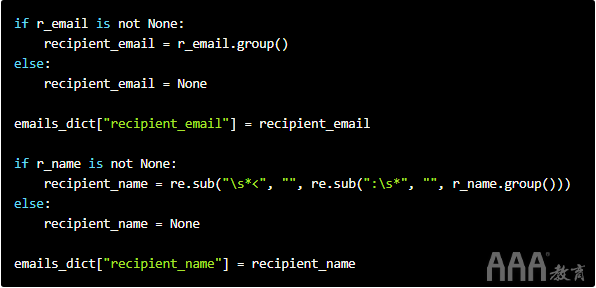
由于From:和To:字段的结构相同,因此我们可以对两者使用相同的代码。我们需要为其他字段定制略有不同的代码。
获取电子邮件的日期
现在确定发送电子邮件的日期。
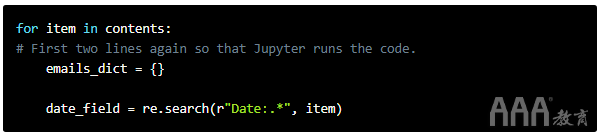
我们Date:为From:和To:字段获取具有相同代码的字段。
并且,就像我们对这两个字段所做的一样,我们检查Date:分配给date_field变量的字段是否不是None。
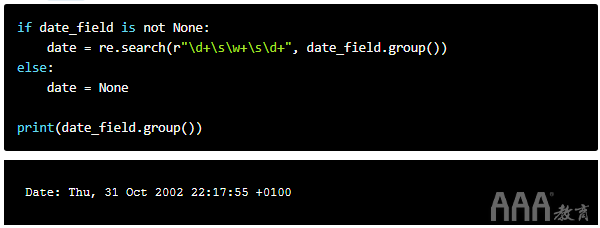
我们已经打印了出来,date_field.group()以便我们可以更清楚地看到字符串的结构。它包括日期,DD MMM YYYY格式的日期和时间。我们只想要日期。日期的代码与姓名和电子邮件地址基本相同,但更为简单。也许唯一令人困惑的是正则表达式模式\d+\s\w+\s\d+。
日期以数字开头。因此,我们用d它来解释它。但是,作为日期的DD部分,它可以是一位或两位数字。在这里+变得重要。在Python正则表达式中,+匹配其左侧1个或多个模式实例。d+因此,无论日期是DD还是一两位数字,它都将与日期的DD部分匹配。
在那之后,有一个空间。这是由占的s,它查找空白字符。因此,该月由三个字母组成w+。然后它撞到另一个空间s。年份由数字组成,因此我们d+再次使用。
完整模式\d+\s\w+\s\d+起作用的原因是它是一个精确的模式,在两侧均以空格字符为界。
接下来,我们None像以前一样检查值。
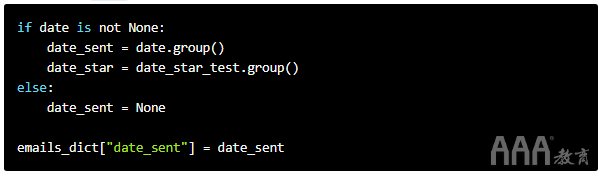
如果date不是None,则将其从匹配对象转换为字符串,并将其分配给变量date_sent。然后,将其插入字典中。
在继续之前,我们应该注意一个关键点。+并且*看起来相似,但它们可以产生非常不同的结果。让我们以日期字符串为例。
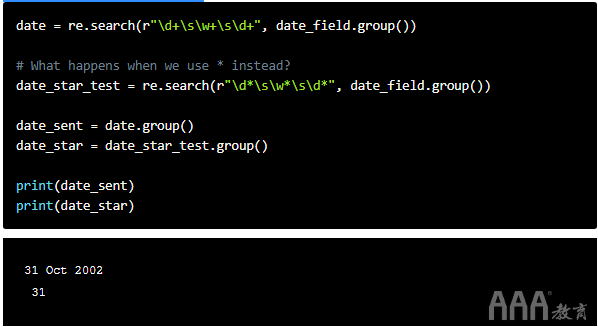
如果使用*,则将匹配零个或多个匹配项。+匹配一个或多个事件。我们已经打印了两种情况的结果。有很大的不同。如您所见,+获取完整日期,而*获取空格和数字31。
接下来,是电子邮件的主题行。
获取电子邮件主题
和以前一样,我们使用相同的代码和代码结构来获取所需的信息。
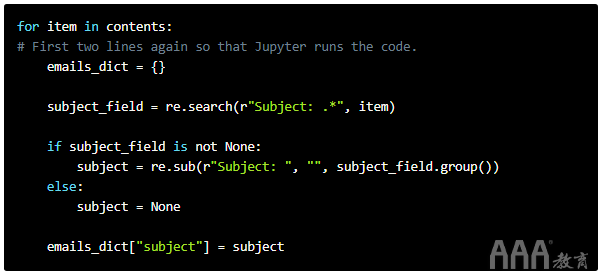
现在我们对Python正则表达式的使用越来越熟悉了,不是吗?它与以前的代码大致相同,不同之处在于,我们"Subject: "用空字符串代替仅获取主题本身。
获取电子邮件的正文
要插入字典的最后一项是电子邮件的正文。

将标头与电子邮件正文分开是一项非常复杂的任务,尤其是当许多标头以一种或另一种方式不同时。在原始的无组织数据中很少发现一致性。对我们来说幸运的是,这项工作已经完成。Python的email软件包非常擅长此任务。
请记住,我们已经较早导入了该软件包。现在,我们将其message_from_string()功能应用于item,以将完整的电子邮件转换为emailMessage对象。Message对象由标头和有效负载组成,它们分别对应于电子邮件的标头和正文。
接下来,我们将其get_payload()功能应用于Message对象。此功能隔离电子邮件的正文。我们将其分配给变量body,然后将其插入到emails_dict键下的字典中"email_body"。
为什么使用电子邮件软件包而不是正文
您可能会问,为什么使用emailPython软件包而不是regex?这是因为目前还没有很好的方法来处理Python正则表达式,而这不需要大量的清理工作。这意味着可能需要另外一份教程。
值得检查一下我们如何做出这样的决定。但是,我们需要先了解[ ]正则表达式中的方括号,然后才能这样做。
[ ]匹配放置在其中的任何字符。例如,如果我们要查找"a","b"或"c"字符串,则可以将其[abc]用作模式。我们上面讨论的模式也适用。[\w\s]会找到字母数字或空格字符。例外是.,它成为方括号内的文字周期。
现在,我们可以更好地了解我们是如何决定使用电子邮件软件包的。
窥视数据集可发现电子邮件标题在字符串"Status: 0"或处停止"Status: R0",并"From r"在下一封电子邮件的字符串前结束。因此,我们可以Status:\s*\w*\n*[\s\S]*From\sr*用来仅获取电子邮件正文。[\s\S]*适用于大块的文本,数字和标点符号,因为它可以搜索空白或非空白字符。
不幸的是,有些电子邮件包含多个"Status:"字符串,而另一些则不包含"From r",这意味着我们会将电子邮件拆分成多于或少于电子邮件列表中词典的数量。它们与我们已经拥有的其他类别不匹配。使用熊猫时,这会产生问题。因此,我们决定利用该email软件包。
创建词典列表
最后,将字典追加emails_dict到emails列表中:

我们可能要emails在此时打印列表以查看其外观。如果您只是一直在使用我们的小样本文件,那么这将是反高潮的,但是在整个语料库中,您将看到正则表达式的强大功能!
我们还可以print(len(emails_dict))查看列表中有多少个词典,因此还有电子邮件。如前所述,整个语料库包含3977。
这是完整的代码:
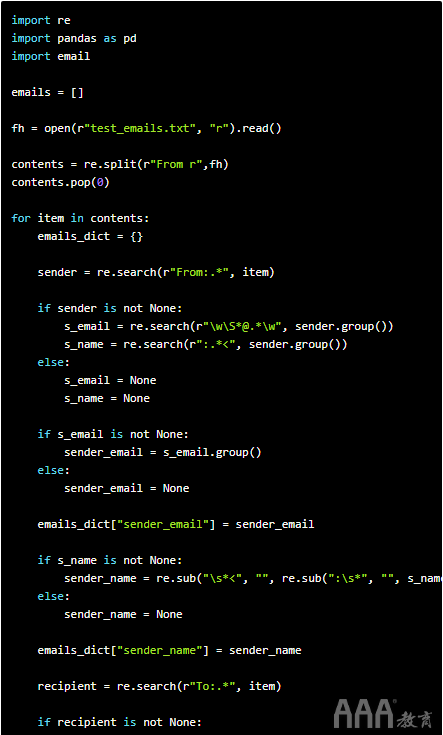
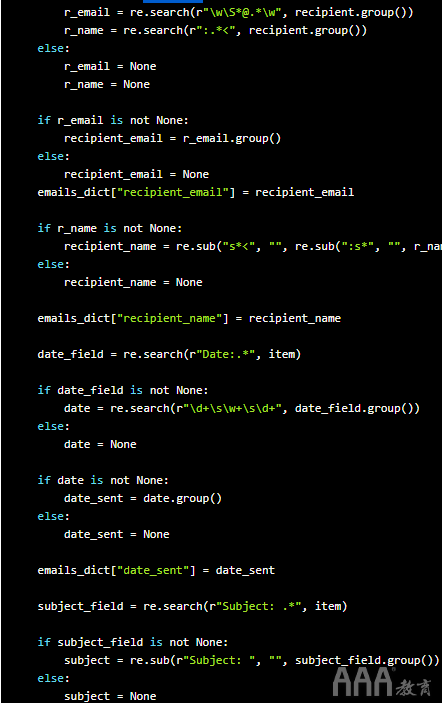
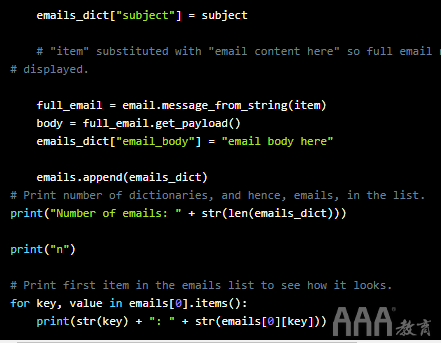
如果使用我们的示例文本文件运行它,将会得到以下结果:
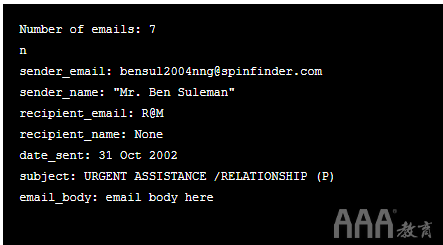
我们已经打印出emails列表中的第一项,它显然是带有键和值对的字典。因为我们使用了for循环,所以每个字典都具有相同的键但值不同。
我们已替换为item,"email content here"以便我们不会打印出电子邮件的全部内容并阻塞屏幕。如果您要使用实际数据集在家打印此文件,则会看到整个电子邮件。
用熊猫处理数据
有了列表中的词典,我们使熊猫图书馆的工作变得无比轻松。每个键将成为列标题,每个值将成为该列中的一行。
我们要做的就是应用以下代码:

通过这一行,我们emails使用pandas DataFrame()函数将字典列表转换为数据框。我们也将其分配给变量。
而已。现在,我们有了一个复杂的熊猫数据框。这实际上是一个整洁的表格,其中包含我们从电子邮件中提取的所有信息。
让我们看一下前几行。

该dataframe.head()函数仅显示前几行,而不显示整个数据集。这需要一个论点。一个可选参数允许我们指定要显示多少行。在这里,n=3让我们查看三行。
我们还可以精确地找到我们想要的东西。例如,我们可以找到从特定域名发送的所有电子邮件。但是,让我们学习一种新的正则表达式模式,以提高找到所需项目的精度。
管道符号会|在其任一侧寻找字符。例如,a|b寻找a或b。
|可能看起来与相同[ ],但是它们确实有所不同。假设我们要匹配要么"crab","lobster"或"isopod"。使用crab|lobster|isopod会比有意义[crablobsterisopod],不是吗?前者将寻找每个单词,而后者将寻找每个字母。
现在,我们|来查找从一个或另一个域名发送的所有电子邮件。

我们在这里使用了相当长的代码。让我们从内而外开始。
emails_df['sender_email']选择标记为的列sender_email。接下来,str.contains(epatra|spinfinder)返回True是否在该列中找到子字符串"epatra"或"spinfinder"。最后,外部emails_df[]返回行的视图,其中该sender_email列包含目标子字符串。好漂亮!
我们也可以查看来自各个单元的电子邮件。为此,我们经历了四个步骤。在步骤1中,我们找到"sender_email"列包含字符串的行的索引"@spinfinder"。注意我们如何使用正则表达式来执行此操作。

在步骤2中,我们使用索引查找电子邮件地址,该loc[]方法作为具有多个不同属性的Series对象返回该电子邮件地址。我们在下面将其打印出来以查看其外观。
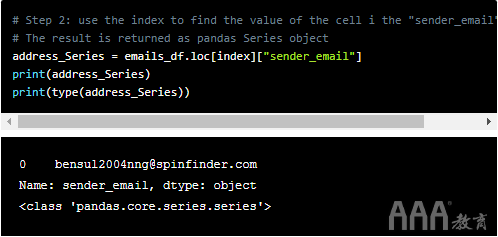
在第3步中,我们从系列对象中提取电子邮件地址,就像从列表中提取项目一样。您可以看到它的类型现在是class。
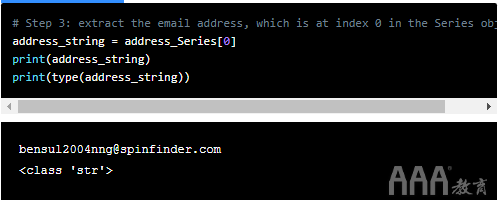
步骤4是提取电子邮件正文的位置。
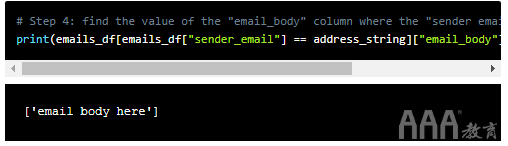
在步骤4中,emails_df['sender_email'] == "bensul2004nng@spinfinder.com"找到该sender_email列包含value 的行"bensul2004nng@spinfinder.com"。接下来,['email_body'].values查找email_body同一行中的列的值。最后,我们打印出该值。
如您所见,我们可以通过多种方式使用正则表达式,它也可以与大熊猫一起使用!如果您的正则表达式工作包含大量的反复试验,请不要气,,尤其是在您刚刚入门时!
其他资源
自从几年前正则表达式从生物学跃升为工程学以来,正则表达式已取得了巨大的发展。如今,正则表达式已在不同的编程语言中使用,其中除了其基本模式之外还有一些变体。我们已经学习了很多Python正则表达式,并且如果您想将它提高到一个新的水平,那么我们的Python数据清理高级课程可能是一个不错的选择。
您还可以在官方参考资料中找到一些帮助,例如Python 有关其模块的文档re。Google有更快的参考资料。
如果您愿意,也可以开始探索Python regex与其他形式的regex Stack Overflow帖子之间的区别。
如果您需要数据集进行试验,则Kaggle和StatsModels很有用。
最后,这是我们制作的Regex速查表,它也非常有用。
填写下面表单即可预约申请免费试听!怕钱不够?可先就业挣钱后再付学费! 怕学不会?助教全程陪读,随时解惑!担心就业?一地学习,可推荐就业!
©2007-2022/ www.aaa-cg.com.cn 北京漫动者数字科技有限公司 备案号: 京ICP备12034770号 监督电话:010-53672995 邮箱:bjaaa@aaaedu.cc

 热门推荐
热门推荐
 UI设计
UI设计
 产品经理
产品经理
 大数据分析
大数据分析
 原画设计
原画设计
 平面设计
平面设计
 新媒体运营
新媒体运营 






