使用大型JSON数据集可能会很痛苦,尤其是当它们太大而无法容纳到内存中时。在这种情况下,命令行工具和Python的组合可以成为探索和分析数据的有效方法。在这篇专注于学习python编程的文章中,我们将研究如何利用Pandas之类的工具来探索和绘制马里兰州蒙哥马利县的警察活动。我们将首先查看JSON数据,然后使用Python探索和分析JSON。
当数据存储在SQL数据库中时,它倾向于遵循看起来像表的刚性结构。这是来自SQLite数据库的示例:

如您所见,数据由行和列组成,其中每一列都映射到已定义的属性,例如id或code。在上面的数据集中,每一行代表一个国家,每一列代表有关该国家的一些事实。
但是随着捕获数据量的增加,存储数据时我们通常不知道数据的确切结构。这称为非结构化数据。一个很好的例子是网站访问者的事件列表。这是发送到服务器的事件列表的示例:

如您所见,上面列出了三个单独的事件。每个事件都有不同的字段,并且某些字段嵌套在其他字段中。这种类型的数据很难存储在常规SQL数据库中。这种非结构化数据通常以称为JavaScript Object Notation(JSON)的格式存储。JSON是一种将列表和字典之类的数据结构编码为字符串的方法,以确保它们易于被机器读取。即使JSON以Javascript开头,实际上它只是一种格式,并且可以用任何语言读取。
Python具有强大的JSON支持,并带有json库。我们既可以将列表和字典转换为JSON,也可以将字符串转换为列表和字典。JSON数据看起来很像Python中的字典,其中存储了键和值。
在如何在Python中使用Pandas和JSON处理大型数据集中,我们将在命令行上浏览JSON文件,然后将其导入Python并使用Pandas进行处理。
数据集
我们将查看一个包含有关马里兰州蒙哥马利县交通违章信息的数据集。您可以在此处下载数据。数据包含有关违规发生地点,汽车类型,接收违规者的人口统计信息以及其他一些有趣信息。我们可以使用此数据集回答很多问题,包括:
1)哪些类型的汽车最有可能因超速而停车?
2)警察什么时候最活跃?
3)“速度陷阱”有多普遍?还是门票在地理位置上分布得相当均匀?
4)人们最常做的事情是什么?
不幸的是,我们不预先知道JSON文件的结构,因此我们需要做一些探索才能弄清楚。我们将使用Jupyter Notebook进行此探索。
探索JSON数据
即使JSON文件只有600MB,我们也会将其视为更大,因此我们可以探讨如何分析不适合内存的JSON文件。我们要做的第一件事是看md_traffic.json文件的前几行。JSON文件只是一个普通的文如何在Python中使用Pandas和JSON处理大型数据集件,因此我们可以使用所有标准命令行工具与之交互:

由此可见,JSON数据是一个字典,并且格式正确。meta是顶级键,缩进两个空格。我们可以使用grep命令来打印所有具有两个前导空格的行,从而获得所有顶级键:
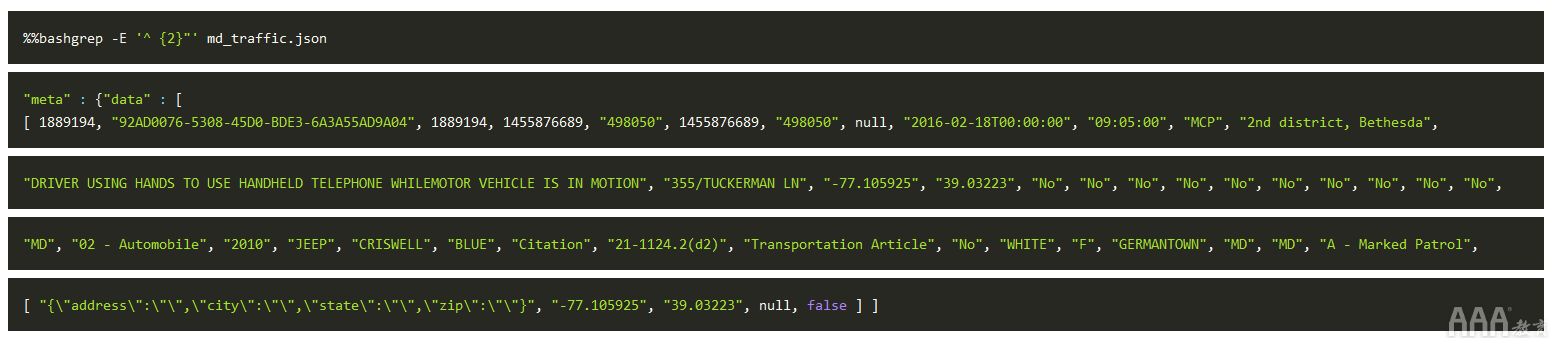
这向我们显示meta和data是md_traffic.json数据中的顶级键。一个名单列表似乎与有关data,而这有可能包含在我们的交通违法行为集中的每个记录。每个内部列表都是一个记录,第一个记录出现在grep命令的输出中。这与我们处理CSV文件或SQL表时使用的结构化数据非常相似。这是数据外观的截断视图:

这看起来很像我们用来处理的行和列。我们只是缺少告诉我们每一列含义的标题。我们可能可以在meta密钥下找到此信息。
meta通常指有关数据本身的信息。让我们深入研究一下meta,看看其中包含什么信息。从head命令,我们知道至少有3钥匙的水平,meta包含一键view,它包含了键id,name,averageRating和其他人。我们可以使用grep打印出任何带有2-6前导空格的行,从而打印出JSON文件的完整键结构:

这向我们显示了与关联的完整密钥结构md_traffic.json,并告诉我们JSON文件的哪些部分与我们相关。在这种情况下,columns键看起来很有趣,因为它可能包含键列表列表中各列的信息data。
提取列上的信息
现在我们知道哪个键包含列中的信息,我们需要读入这些信息。由于我们假设JSON文件不适合内存,因此我们不能仅使用json库直接读取它。相反,我们需要以一种内存有效的方式来迭代读取它。
我们可以使用ijson包完成此操作。ijson将迭代解析json文件,而不是一次读取所有内容。这比直接读取整个文件要慢,但是它使我们能够处理无法容纳在内存中的大文件。要使用ijson,我们指定要从中提取数据的文件,然后指定要提取的关键路径:
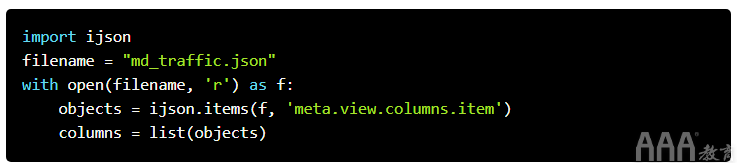
在上面的代码中,我们打开md_traffic.json文件,然后使用itemsijson中的方法从文件中提取列表。我们使用meta.view.columns符号指定列表的路径。回想一下这meta是一个顶级密钥,它包含view内部,columns内部也包含在内。然后meta.view.columns.item,我们指定表明我们应该提取meta.view.columns列表中的每个单独的项目。该items函数将返回一个生成器,因此我们使用list方法将生成器转换为Python列表。我们可以打印出列表中的第一项:

从上面的输出中,看起来其中的每个项目columns都是一个字典,其中包含有关每一列的信息。为了获得我们的标题,看起来fieldName是要提取的相关密钥。要获取我们的列名,我们只需fieldName从以下各项中提取键columns:
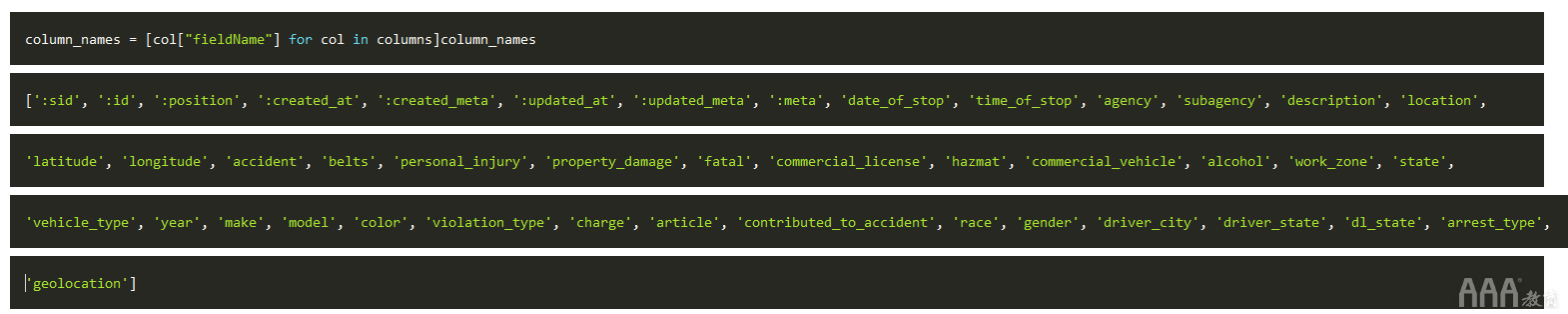
大!现在我们有了列名,接下来可以提取数据本身了。
提取数据
您可能还记得,数据已锁定在密钥内的列表列表中data。我们需要将这些数据读入内存以进行操作。幸运的是,我们可以使用刚刚提取的列名称来仅获取相关的列。这样可以节省大量空间。如果数据集更大,则可以迭代处理一批行。因此,请阅读第一10000000行,进行一些处理,然后阅读下一行10000000,依此类推。在这种情况下,我们可以定义我们关心的列,并再次用于ijson迭代处理JSON文件:
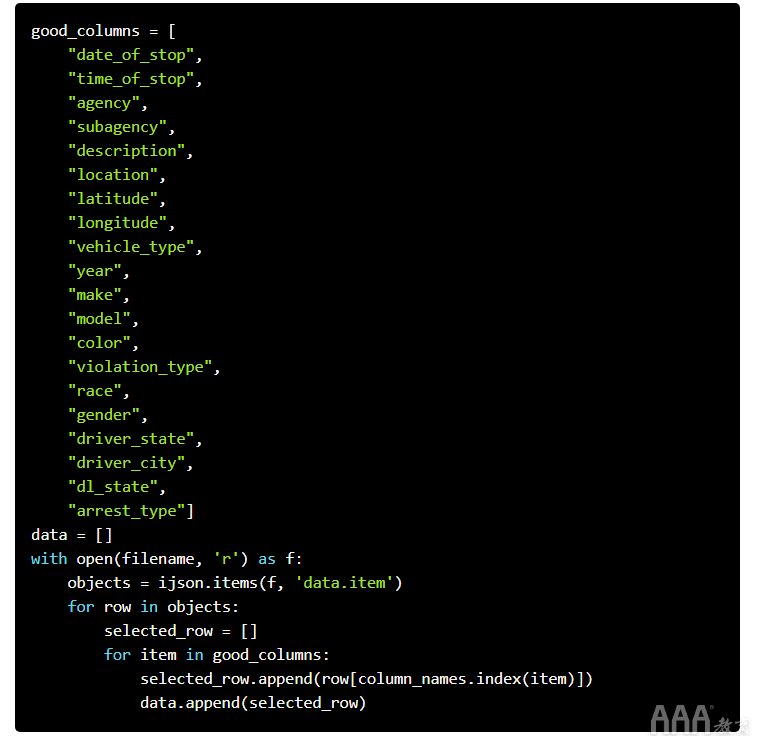
现在我们已经读完数据,我们可以打印出第一个项目data:

将数据读入熊猫
现在,我们将数据作为列表列表,并将列标题作为列表,我们可以创建Pandas Dataframe来分析数据。如果您不熟悉Pandas,则它是一个数据分析库,它使用高效的表格数据结构(称为数据框)来表示您的数据。Pandas允许您将列表列表转换为数据框,并分别指定列名称。

现在我们将数据存储在一个数据框中,我们可以进行一些有趣的分析。下表列出了按汽车颜色划分的停靠点数:
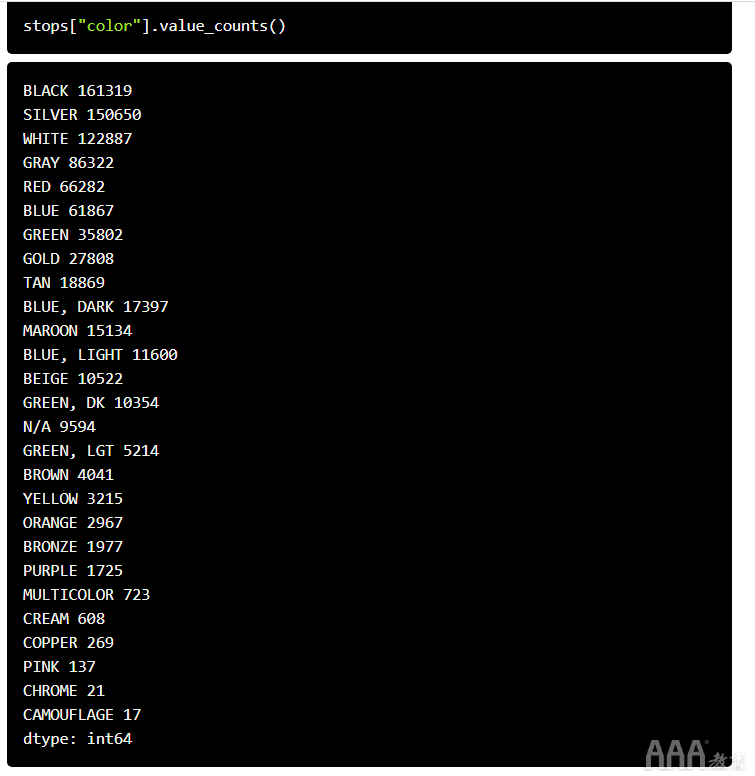
伪装似乎是一种非常流行的汽车颜色。下表列出了创建该引用的警察部门:
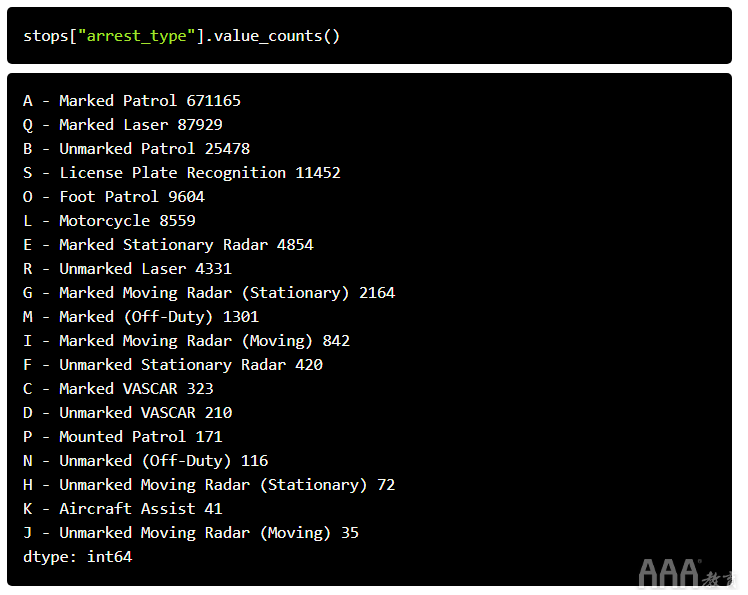
随着红光摄像机和高速激光仪的兴起,有趣的是,巡逻车仍是迄今为止引证的主要来源。
转换列
我们现在几乎可以做一些时间和基于位置的分析,但我们需要的转换longitude,latitude以及date列从字符串第一个浮动。我们可以使用下面的代码来转换latitude和longitude:
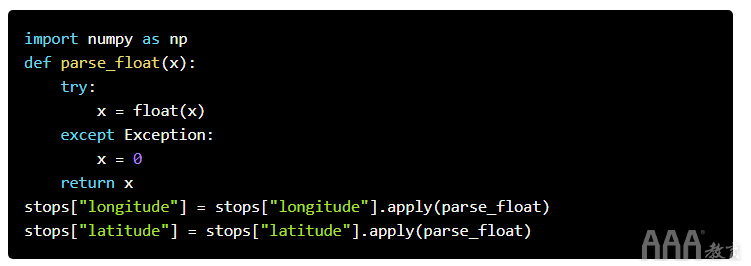
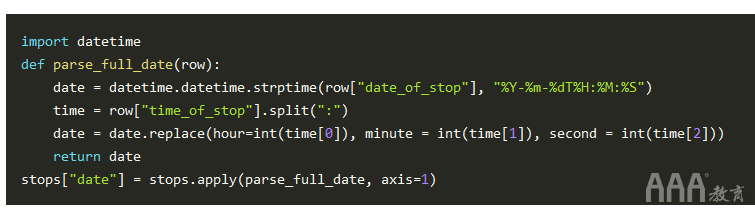
奇怪的是,一天中的时间和停止日期存储在两个单独的列中time_of_stop,和date_of_stop。我们将同时解析它们,并将它们转换为单个datetime列:
现在,我们可以绘制出哪些天导致流量最多的停止:

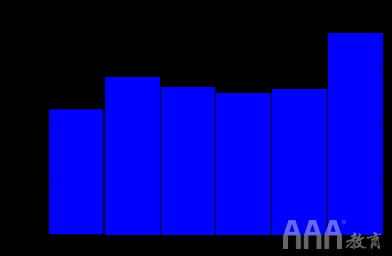
在此情节中,星期一为0,星期日为6。看起来周日停靠最多,而周一停靠最少。这也可能是数据质量问题,由于某些原因,无效日期导致了星期日。您必须更深入地研究该date_of_stop列才能确定其含义(这超出了如何在Python中使用Pandas和JSON处理大型数据集的范围)。
我们还可以列出最常见的交通停止时间:

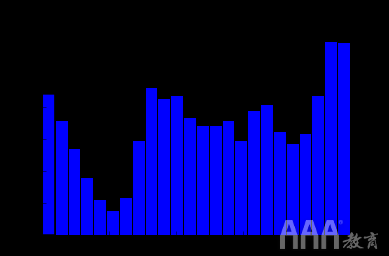
看来最多的停靠点是在午夜左右,而最少的停靠点是在凌晨5点左右。这可能是有道理的,因为人们在深夜从酒吧和晚餐开车回家,并且可能会受到伤害。这也可能是一个数据质量问题,time_of_stop因此有必要仔细阅读专栏以获取完整的答案。
细分止损
现在,我们已经转换了位置和日期列,我们可以绘制出交通站点的地图。因为映射在CPU资源和内存方面非常密集,所以我们需要从头stops开始过滤掉我们使用的行:

在上面的代码中,我们选择了过去一年中的所有行。我们可以进一步缩小范围,仅选择在高峰时段(每个人都在工作的早晨)发生的行:

使用出色的大叶包,我们现在可以可视化所有停靠点的发生位置。Folium允许您利用传单轻松地在Python中创建交互式地图。为了保持性能,我们将仅可视化的第一1000行morning_rush:
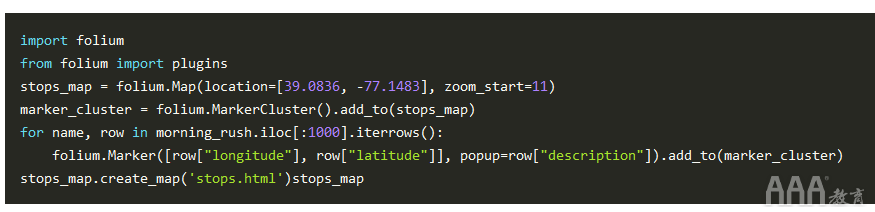

这表明许多交通站点都集中在县的右下角。我们可以通过热图进一步扩展我们的分析:

下一步
在这篇专注于学习python编程的文章中,我们学习了如何使用Python通过命令行工具,ijson,Pandas,matplotlib和folium从原始JSON数据转换为功能齐全的地图。如果您想了解有关这些工具的更多信息,请查看有关AAA教育的数据分析,数据可视化和命令行课程。
填写下面表单即可预约申请免费试听!怕钱不够?可先就业挣钱后再付学费! 怕学不会?助教全程陪读,随时解惑!担心就业?一地学习,可推荐就业!
©2007-2022/ www.aaa-cg.com.cn 北京漫动者数字科技有限公司 备案号: 京ICP备12034770号 监督电话:010-53672995 邮箱:bjaaa@aaaedu.cc

 热门推荐
热门推荐
 UI设计
UI设计
 产品经理
产品经理
 大数据分析
大数据分析
 原画设计
原画设计
 平面设计
平面设计
 新媒体运营
新媒体运营 






