“大数据分析”评为“ 21世纪最热门的工作” 以来,人们对机器学习的兴趣激增。但是,如果您刚刚开始学习机器学习,则可能很难入手。因此,AAA教育发布了广受欢迎的关于初学者的优秀机器学习算法的文章。
这篇文章是针对0基础初学者的。如果你有在数据科学和机器学习一些经验,你可能会更感兴趣的是做机器学习在Python这更深入的教程用scikit-learn,或在我们的机器学习课程,这从这里开始。如果您还不清楚“数据科学”和“机器学习”之间的区别,那么本文将为您提供一个很好的解释:机器学习和数据科学-两者有何不同?
机器学习算法是可以从数据中学习并从经验中改进而无需人工干预的程序。学习任务可能包括学习将输入映射到输出的功能,学习未标记数据中的隐藏结构;或“基于实例的学习”,其中通过将新实例(行)与训练数据中存储在内存中的实例进行比较,为新实例生成类标签。“基于实例的学习”不会从特定实例创建抽象。
机器学习算法的类型
机器学习(ML)算法有3种类型:
监督学习算法:
监督学习使用标记的训练数据来学习将输入变量(X)转换为输出变量(Y)的映射函数。换句话说,它在以下等式中求解f:
Y = f(X)
当给定新的输入时,这使我们能够准确地生成输出。
我们将讨论两种类型的监督学习:分类和回归。
分类被用于预测给定的样品的结果,当输出变量在类的形式。分类模型可能会查看输入数据并尝试预测“病”或“健康”等标签。
当输出变量为实数值形式时,将回归用于预测给定样本的结果。例如,回归模型可能会处理输入数据以预测降雨量,人的身高等。
我们在本博客中介绍的前5种算法-线性回归,逻辑回归,CART,朴素贝叶斯和K最近邻(KNN)-是监督学习的示例。
合奏是另一种监督学习。这意味着要组合多个各自较弱的机器学习模型的预测,以对新样本产生更准确的预测。本文的算法9和10(使用随机森林进行装袋,使用XGBoost进行增强)是集成技术的示例。
无监督学习算法:
当我们只有输入变量(X)而没有相应的输出变量时,将使用无监督学习模型。他们使用未标记的训练数据来建模数据的基础结构。
我们将讨论三种无监督学习:
关联用于发现集合中项目同时出现的可能性。它广泛用于市场分析。例如,可以使用关联模型来发现如果客户购买面包,则他/她也有80%可能也购买鸡蛋。
聚类用于对样本进行分组,以使同一聚类中的对象彼此之间的相似性大于与另一个聚类中的对象的相似性。
降维用于减少数据集的变量数量,同时确保仍传达重要信息。降维可以使用特征提取方法和特征选择方法来完成。“特征选择”选择原始变量的子集。特征提取执行从高维空间到低维空间的数据转换。示例:PCA算法是一种特征提取方法。
我们在这里介绍的算法6-8(Apriori,K-means,PCA)是无监督学习的示例。
强化学习:
强化学习是机器学习算法的一种,它允许代理通过学习使奖励最大化的行为来根据其当前状态决定最佳的下一步操作。
加固算法通常通过反复试验来学习最佳动作。例如,假设有一个视频游戏,其中玩家需要在特定时间移动到特定地点以赚取积分。玩该游戏的强化算法会从随机移动开始,但是随着时间的流逝,经过反复试验,它将学习需要在何时何地移动游戏中角色以最大化其总点数。
量化机器学习算法的流行度
这十种算法是从哪里得到的?任何此类列表本质上都是主观的。诸如此类的研究已经量化了10种最流行的数据挖掘算法,但是它们仍然依赖于调查反馈的主观响应,通常是高级学术从业人员。例如,在上面的研究中,受访者是ACM KDD创新奖,IEEE ICDM研究贡献奖的获得者;KDD '06,ICDM '06和SDM '06的计划委员会成员;ICDM '06的145位与会者。
这篇文章中列出的前10个算法是在考虑机器学习初学者的情况下选择的。它们是我在孟买大学计算机工程学士学位期间从“数据仓库和挖掘”(DWM)课程中学到的主要算法。我加入了最后两种算法(集成方法),尤其是因为它们经常被用来赢得Kaggle比赛。
没有更多的基础知识,面向初学者的十大机器学习算法:
1.线性回归
在机器学习中,我们有一组输入变量(x)用于确定输出变量(y)。输入变量和输出变量之间存在关系。ML的目标是量化这种关系。
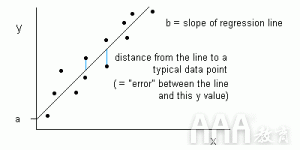
图1:线性回归以y = a + bx的形式表示为一条线
在线性回归中,输入变量(x)和输出变量(y)之间的关系表示为y = a + bx形式的方程。因此,线性回归的目标是找出系数a和b的值。在此,a是截距,b是直线的斜率。
图1显示了数据集的绘制的x和y值。目标是拟合最接近大多数点的线。这将减少数据点的y值与线之间的距离(“错误”)。
2. Logistic回归
线性回归预测是连续值(即,以厘米为单位的降雨),逻辑回归预测是在应用转换函数后的离散值(即,学生是否通过/未通过)。
Logistic回归最适合于二进制分类:y = 0或1的数据集,其中1表示默认类。例如,在预测事件是否会发生时,只有两种可能性:事件发生(我们将其表示为1)或事件不发生(0)。因此,如果我们要预测患者是否生病,我们将使用1数据集中的值标记患病的患者。
逻辑回归以其使用的转换函数命名,该函数称为逻辑函数h(x)= 1 /(1 + ex)。这形成了S形曲线。
在逻辑回归中,输出采用默认类别的概率形式(与线性回归不同,线性回归是直接产生输出的)。由于这是一个概率,因此输出在0-1的范围内。因此,例如,如果我们要预测患者是否生病,我们已经知道生病的患者表示为1,因此,如果我们的算法将0.98的得分分配给患者,则认为该患者很有可能生病了。
使用逻辑函数h(x)= 1 /(1 + e ^ -x)通过对x值进行对数转换来生成此输出(y值)。然后应用阈值以强制将此概率转换为二进制分类。
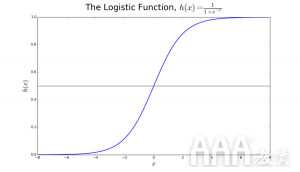
图2:逻辑回归确定肿瘤是恶性还是良性。如果概率h(x)> = 0.5,则分类为恶性
在图2中,要确定肿瘤是否为恶性,默认变量为y = 1(肿瘤=恶性)。x变量可以是肿瘤的量度,例如肿瘤的大小。如图所示,逻辑函数将数据集各种实例的x值转换为0到1的范围。如果概率超过阈值0.5(由水平线显示),则肿瘤为归类为恶性。
逻辑回归方程P(x)= e ^(b0 + b1x)/(1 + e(b0 + b1x))可以转换为ln(p(x)/ 1-p(x))= b0 + b1x。
Logistic回归的目标是使用训练数据来找到系数b0和b1的值,以使预测结果与实际结果之间的误差最小。使用最大似然估计技术估计这些系数。
3.购物车
分类和回归树(CART)是决策树的一种实现。
分类树和回归树的非终端节点是根节点和内部节点。终端节点是叶节点。每个非终端节点代表一个输入变量(x)和该变量的分割点;叶节点表示输出变量(y)。该模型按以下方式进行预测:遍历树的拆分以到达叶节点并输出在叶节点处存在的值。
下面图3中的决策树根据一个人的年龄和婚姻状况,对其是否购买跑车或小型货车进行了分类。如果此人已超过30岁且未结婚,我们将按照以下步骤进行操作:“超过30年?” ->是->“已婚?” ->不行 因此,模型输出一辆跑车。
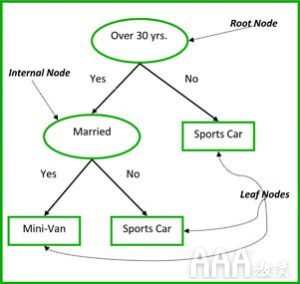
图3:决策树的各个部分
4.朴素贝叶斯
为了计算一个事件已经发生的可能性,我们使用贝叶斯定理。在给定我们的先验知识(d)的情况下,要计算假设(h)为真的概率,我们使用贝叶斯定理,如下所示:
P(h | d)=(P(d | h)P(h))/ P(d)
哪里:
1)P(h | d)=后验概率。给定数据d,假设h的概率为真,其中P(h | d)= P(d1 | h)P(d2 | h)….P(dn | h)P(d)
2)P(d | h)=似然。给定假设h为真,数据d的概率。
3)P(h)=班级先验概率。假设h为真的概率(与数据无关)
4)P(d)=预测器先验概率。数据的概率(与假设无关)
该算法之所以称为“朴素”,是因为它假设所有变量都彼此独立,这是在实际示例中做出的朴素假设。
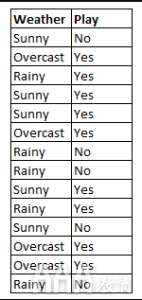
图4:使用天真贝叶斯通过变量“天气”预测“比赛”的状态
以图4为例,如果weather ='sunny',结果如何?
在给定变量天气=“晴天”的情况下,要确定结果游戏=“是”或“否”,请计算P(是|晴天)和P(否|晴天),并以较高的概率选择结果。
-> P(yes | sunny)=(P(sunny | yes)* P(yes))/ P(sunny)=(3/9 * 9/14)/(5/14)= 0.60
-> P(no | sunny)=(P(sunny | no)* P(no))/ P(sunny)=(2/5 * 5/14)/(5/14)= 0.40
因此,如果天气=“晴天”,则结果为游戏=“是”。
5. KNN
K最近邻居算法将整个数据集用作训练集,而不是将数据集分为训练集和测试集。
当新数据实例需要结果时,KNN算法遍历整个数据集以找到新实例的k个最近实例,或与新记录最相似的k个实例,然后输出均值结果(用于回归问题)或模式(最常见的课堂)的分类问题。k的值是用户指定的。
使用诸如欧几里得距离和汉明距离之类的度量来计算实例之间的相似度。
无监督学习算法
6.先验
事务数据库中使用Apriori算法来挖掘频繁的项目集,然后生成关联规则。它广泛用于市场购物篮分析中,在其中可以检查数据库中经常同时出现的产品组合。通常,我们将关联规则写为“如果某人购买了商品X,那么他购买了商品Y”为:X->Y。
示例:如果某人购买牛奶和糖,那么她可能会购买咖啡粉。这可以用关联规则的形式写成:{牛奶,糖}->咖啡粉。超过支持和信心的阈值后,将生成关联规则。
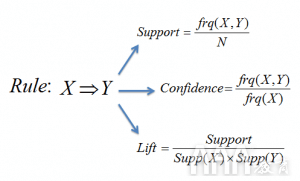
图5:关联规则X-> Y的支持度,置信度和提升度的公式
支持度量有助于减少频繁生成项目集时要考虑的候选项目集的数量。该支持措施遵循Apriori原则。Apriori原则指出,如果某个项目集很频繁,那么它的所有子集也必须很频繁。
7. K-均值
K-means是一种将相似数据分组为聚类的迭代算法,它计算k个聚类的质心,并为其质心与数据点之间的距离最小的聚类分配一个数据点。

图6:K-means算法的步骤
运作方式如下:
我们首先选择k的值。在这里,让我们说k =3。然后,我们将每个数据点随机分配给3个群集中的任何一个。计算每个群集的群集质心。红色,蓝色和绿色的星星分别代表3个星团的质心。
接下来,将每个点重新分配给最近的聚类质心。在上图中,高5点被分配给具有蓝色质心的聚类。遵循相同的过程将点分配给包含红色和绿色质心的聚类。
然后,计算新群集的质心。旧的质心是灰色的星星;新的质心是红色,绿色和蓝色的星星。
最后,重复步骤2-3,直到没有点从一个群集切换到另一个群集为止。一旦连续两个步骤都没有切换,请退出K-means算法。
8. PCA
主成分分析(PCA)用于通过减少变量数量使数据易于浏览和可视化。这是通过将数据中的最大方差捕获到具有称为“主要成分”的轴的新坐标系中来完成的。
每个分量都是原始变量的线性组合,并且彼此正交。分量之间的正交性指示这些分量之间的相关性为零。
第一个主成分捕获数据中最大可变性的方向。第二个主成分捕获数据中的剩余方差,但具有与第一个成分不相关的变量。同样,所有连续的主成分(PC3,PC4等)捕获剩余的差异,同时与前一个成分不相关。

图7:将3个原始变量(基因)简化为2个新变量,称为主成分(PC)
集合学习技巧:
汇总是指通过投票或取平均值,将多个学习者(分类器)的结果组合在一起,以提高结果。在分类期间使用投票,在回归期间使用平均。这个想法是全体学习者的表现要好于单个学习者。
共有3种组合算法:装袋,增强和堆叠。我们不会在这里讨论“堆叠”,但是如果您想对其进行详细的说明,那么这是Kaggle的可靠介绍。
9.随机森林套袋
套袋的第一步是使用Bootstrap Sampling方法创建的数据集创建多个模型。在Bootstrap抽样中,每个生成的训练集都由来自原始数据集的随机子样本组成。
这些训练集的每一个都具有与原始数据集相同的大小,但是有些记录会重复多次,而有些记录根本不会出现。然后,将整个原始数据集用作测试集。因此,如果原始数据集的大小为N,则每个生成的训练集的大小也为N,唯一记录的数量约为(2N / 3);测试集的大小也为N。
套袋的第二步是在不同的生成的训练集上使用相同的算法来创建多个模型。
这是随机森林进入的地方。与决策树不同,在决策树中,每个节点都在最大特征上进行分割,以最大程度地减少错误,在随机森林中,我们选择特征的随机选择以构建最佳分裂。随机性的原因是:即使套袋,当决策树选择最佳分割特征时,它们最终也会具有相似的结构和相关的预测。但是,对特征的随机子集进行分割后的装袋意味着子树的预测之间的相关性较小。
在每个分割点要搜索的特征数量被指定为“随机森林”算法的参数。
因此,在使用“随机森林”进行装袋时,每棵树都是使用记录的随机样本构建的,而每个拆分都是使用随机变量的预测变量构建的。
10.使用AdaBoost提升
Adaboost代表自适应增强。套袋是一个并行的集合,因为每个模型都是独立构建的。另一方面,boosting是一个顺序集合,其中每个模型都是基于纠正先前模型的错误分类而构建的。
套袋主要涉及“简单投票”,其中每个分类器投票以获得最终结果,该结果由大多数并行模型确定;增强涉及“加权投票”,其中每个分类器投票以获得由多数决定的最终结果,但是顺序模型是通过为先前模型的错误分类实例分配更大的权重来构建的。
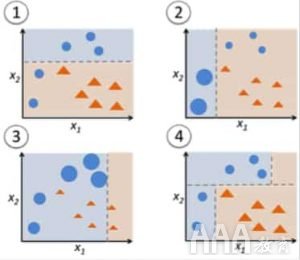
图8:决策树的Adaboost
在图8中,步骤1、2、3涉及一个称为决策树的弱学习者(一个仅基于1个输入要素的值进行预测的1层决策树;其根立即连接到其叶子的决策树) 。
构造弱学习者的过程一直持续到构造了用户定义数量的弱学习者或直到训练期间没有进一步的改进为止。步骤4合并了先前模型的3个决策树桩(因此在决策树中具有3个拆分规则)。
首先,从一个决策树桩开始,对一个输入变量进行决策。
数据点的大小表明,我们已应用相等的权重将其分类为圆形或三角形。决策树桩已在上半部分生成一条水平线以对这些点进行分类。我们可以看到有两个圆被错误地预测为三角形。因此,我们将为这两个圈子分配更高的权重,并应用另一个决策树桩。
其次,转到另一个决策树树桩,对另一个输入变量进行决策。
我们观察到上一步中两个错误分类的圆圈的大小大于其余点。现在,第二个决策树桩将尝试正确预测这两个圆。
分配较高的权重后,这两个圆已通过左侧的垂直线正确分类。但这现在导致对顶部三个圆圈的分类错误。因此,我们将为顶部的这三个圆圈分配更高的权重,并应用另一个决策树桩。
第三,训练另一个决策树树桩,以对另一个输入变量进行决策。
上一步中的三个错误分类的圆圈大于其余数据点。现在,已生成右侧的垂直线以对圆形和三角形进行分类。
第四,结合决策树桩。
我们结合了先前3个模型的分隔符,并观察到与任何单个弱学习者相比,该模型的复杂规则正确地对数据点进行了分类。
回顾一下,我们介绍了一些最重要的数据科学机器学习算法:
a)5种监督学习技术-线性回归,逻辑回归,CART,朴素贝叶斯,KNN。
b)3种无监督学习技术-Apriori,K-means,PCA。
c)2种合奏技术-用随机森林装袋,用XGBoost增强。
填写下面表单即可预约申请免费试听!怕钱不够?可先就业挣钱后再付学费! 怕学不会?助教全程陪读,随时解惑!担心就业?一地学习,可推荐就业!
©2007-2022/ www.aaa-cg.com.cn 北京漫动者数字科技有限公司 备案号: 京ICP备12034770号 监督电话:010-53672995 邮箱:bjaaa@aaaedu.cc

 热门推荐
热门推荐
 UI设计
UI设计
 产品经理
产品经理
 大数据分析
大数据分析
 原画设计
原画设计
 平面设计
平面设计
 新媒体运营
新媒体运营 






