毫无疑问,机器学习是当前大数据分析中最热门的话题。这也是一些最令人兴奋的技术领域的基本概念,例如自动驾驶汽车和预测分析。百度上的机器学习搜索在2019年4月创历史新高,自此以来兴趣一直没有下降。
但是实际上学习机器学习可能很困难。您要么使用行为类似于“黑匣子”的预构建包,要么在其中传递数据,另一端则产生魔力,或者您必须处理高级数学和线性代数。每种方法都使学习机器学习充满挑战和威胁。
用Python搭建机器学习模型预测房租价格旨在向您介绍机器学习的基本概念。在继续学习时,您将从头开始构建第一个模型以进行预测,同时准确地了解模型的工作原理。
(用Python搭建机器学习模型预测房租价格基于我们的机器学习基础知识课程,它是我们的大数据分析学习路径的一部分。该课程涉及更多细节,使您可以交互地编写代码,以便边做边学。对掌握机器学习非常感兴趣,我们建议您选择该课程以及我们的大数据分析家课程中的其他机器学习课程。)
什么是机器学习?
简而言之,机器学习是构建系统(称为模型)的实践,可以使用数据对其进行训练,以找到可用于对新数据进行预测的模式。
与许多其他编程不同,机器学习模型不是基于规则的系统,在该系统中,使用一系列“如果/那么”语句来确定结果(例如,“如果学生错过了超过50%的课程,则自动使他们失败) ')。
取而代之的是,机器学习模型检查具有定义结果的数据集中数据点之间的统计关系,然后将所学到的关于这些关系的知识应用于分析和预测新数据集的结果。
机器学习的工作原理
为了更好地理解机器学习的基础,我们来看一个示例。假设我们要出售房屋,并且想确定合适的挂牌价格。我们可能会做的事情,以及房地产经纪人实际上会做的事情,就是看一看我们地区已经出售的可比房屋。用机器学习的术语来说,我们看的每座房子都称为观察。
对于每座房屋,我们将考虑以下因素,例如房屋的大小,房屋的卧室和浴室的数量,距杂货店等便利设施的距离等。在机器学习术语中,每个属性都称为特点。
一旦找到了许多类似的房屋,我们便可以查看它们的售价,对这些价格进行平均,然后得出关于我们房屋价值的相当合理的预测。
在此示例中,我们建立的“模型”是根据我们所在地区其他房屋的数据(观测值)进行训练的,然后用于对房屋价值进行预测。我们预测的值,即价格,被称为目标变量。
当然,这个例子并不是真正的“机器学习”,因为我们根据自己房屋的特点挑选了“观测”房屋进行研究。试图大规模地进行这种事情(例如,基于庞大的房地产数据集预测城市中任何房屋的价格)对人类来说将是非常困难的。观察和特征越多,用手进行这样的分析就越困难,并且越容易错过数据中的重要但非显而易见的模式。
这就是机器学习是在一个真正的机器学习模型可以做的非常相似于我们的小房子预测模型的东西很多规模较大的:
1)检查过去房屋销售的大数据集(观察)
2)查找房屋的特征(特征)与其价格(目标变量)之间的模式和统计关系,包括查看数据的人可能看不到的模式
3)使用这些统计关系和模式来预测任何新房的价格,我们以此为基础提供数据。
我们将在用Python搭建机器学习模型预测房租价格中构建的模型与上面概述的模型相似。我们将使用Python构建一个简单的模型,以提出租房平台公寓的租金价格建议。
(本文假定您熟悉Python的pandas库-如果您需要学习pandas,我们建议您将pandas教程分为两部分,或者将Python和Pandas互动式学习。)
预测租房平台的租金价格
对于没有经验的人,租房平台是一个短期房屋和公寓出租的互联网市场。例如,它使您可以在外出时将房屋出租一周,或将备用卧室出租给旅行者。该公司本身已从2008年成立时迅速成长为估值接近400亿美元的公司,目前的市值超过全球任何一家连锁酒店。
租房平台房东面临的挑战之一是确定最佳的每晚租金价格。在许多地区,潜在的租户都会看到很多房源,并且可以按价格,卧室数量,房间类型等条件进行过滤。由于租房平台是一个市场,房东每晚收取的费用与市场的动态密切相关。这是租房平台上搜索体验的屏幕截图:
租房平台搜索结果
假设我们想在租房平台上租一个房间。作为房东,如果我们试图以高于市场价格的价格收费,那么租房者将选择更多负担得起的替代品,而我们不会赚钱。另一方面,如果我们将每晚租金设置得太低,我们将错过潜在的收入。
我们如何才能达到中间的“最佳位置”?我们可以使用的一种策略是:
1)找到一些与我们相似的列表,
2)平均与我们最相似的商品的标价,
3)并将我们的挂牌价设为此计算出的平均价格。
但是,一遍又一遍地手动执行操作将非常耗时,而且我们是大数据分析家!我们将使用称为k-nearest neighbors的技术来构建机器学习模型,以自动执行此过程,而不是手动进行操作。
我们将从查看将要使用的数据集开始。
我们的租房平台数据
租房平台不会在其市场上发布任何列表上的数据,而是一个名为Inside 租房平台的独立组织从网站上许多主要城市的列表样本中提取数据。在本文中,我们将使用2015年10月3日以来在美国首都华盛顿特区上市的数据集。这是该数据集的直接链接。
数据集中的每一行都是一个特定的清单,可供在华盛顿特区的租房平台上租用。用机器学习的术语来说,每一行都是一个观察。这些列描述了每个列表的不同特征(以机器学习术语为特征)。
为了减少使用数据集的麻烦,我们删除了原始数据集中的许多列,并将文件重命名为dc_租房平台.csv。
这是我们将要使用的一些更重要的列(功能),因为这些都是租房者可以用来评估他们将选择哪个清单的特征:
1)accommodates:租金可容纳的客人人数
2)bedrooms:租金中包含的卧室数量
3)bathrooms:租金中包含的浴室数量
4)beds:租金中包含的床位数
5)price:每晚租金
6)minimum_nights:客人可以租用的最少住宿天数
7)maximum_nights:客人可以租用的最大住宿天数
8)number_of_reviews:先前访客留下的评论数
我们将从将清理后的数据集读入pandas开始,打印其大小并查看前几行。(如果您不确定如何自己从原始数据集中删除多余的列,请查看我们的一些pandas和数据清理课程)。
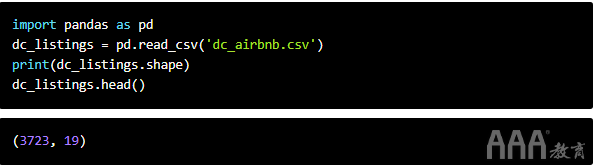

这看起来不错!现在,让我们继续我们将用于机器学习模型的算法。
K近邻算法
K最近邻(KNN)算法的工作方式与我们之前概述的三步过程类似,可以将我们的列表与类似列表进行比较,并取平均价格。让我们更详细地看一下:
首先,我们选择k要比较的相似列表的数量。
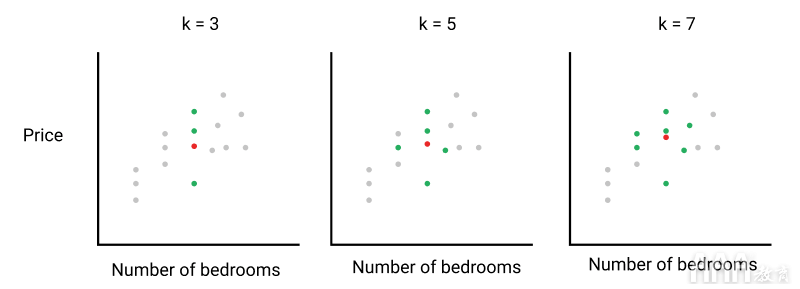
其次,我们需要使用相似度指标来计算每个列表与我们的相似度。

第三,我们使用相似性指标对每个列表进行排名,然后选择第一个k列表。
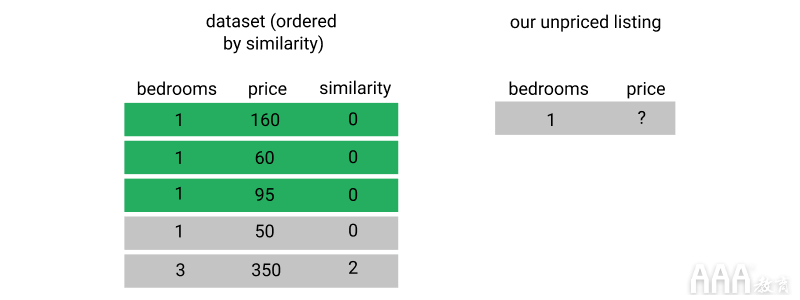
最后,我们计算k相似商品的平均价格,并将其用作我们的标价。
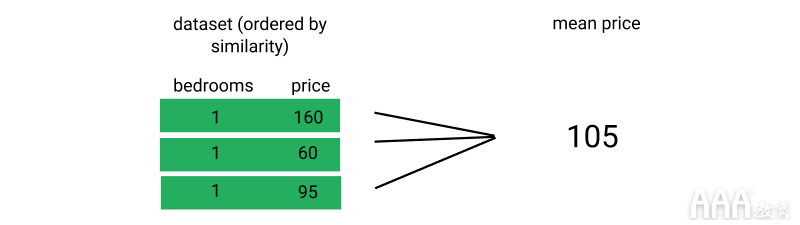
尽管为简单起见,上面的图像每个观察仅使用两个功能(卧室和价格)与我们的清单进行比较,但机器学习的好处在于,通过为每个观察评估更多的功能,我们可以进行更复杂的比较。
让我们开始通过定义我们将要使用的相似性度量来构建真实模型。然后,我们将实现k最近邻居算法,并使用该算法为新列表建议价格。出于用Python搭建机器学习模型预测房租价格的目的,我们将使用的固定k值5,但是一旦您熟悉算法的工作流程,就可以尝试使用该值来查看使用较低或较高的k值可获得更好的结果。
欧氏距离
尝试预测价格等连续值时,使用的主要相似性度量是欧几里德距离。这是欧几里得距离的一般公式:
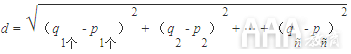
哪里 q1个 至 qñ 代表一个观测值的特征值 p1个 至 pñ 代表其他观察的特征值。
如果您的头部刚刚爆炸,请放心!我们将把它分解成小块。我们将从...开始
建立基本的KNN模型

让我们首先分解一下内容,然后仅查看数据集中的一列。这是仅一个功能的公式:
用语言表达,我们想要找到观测值与我们要为所使用功能预测的数据点之间的差的绝对值。
就目前的目的而言,假设我们要租用的居住空间可容纳三个人。
我们将首先仅使用accommodates要素来计算数据集中第一个居住空间与我们自己之间的距离。我们可以使用NumPy函数np.abs()获取绝对值。
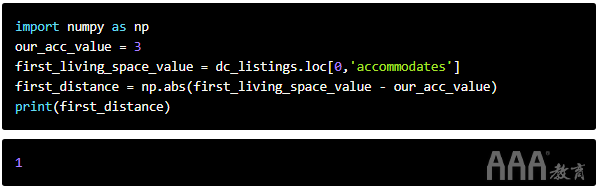
欧几里得距离的最小可能值为零,这意味着我们正在比较的观测值与我们的观测值相同,因此我们在这里得到的结果是有意义的。但是,孤立地讲,该值的意义并不大,除非我们知道它与其他值的比较方式。让我们为数据集中的每个观测值计算欧几里得距离,并查看使用的值范围pd.value_counts()。
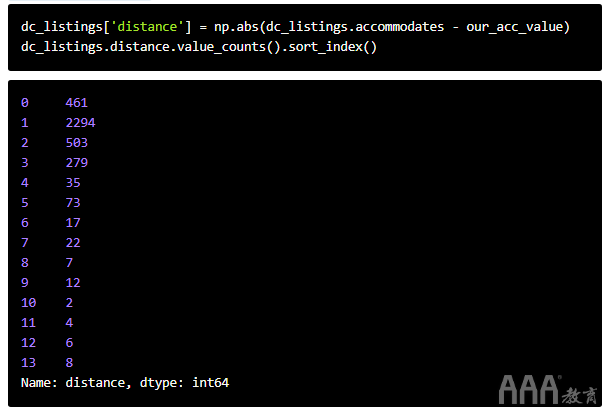
有461条距离为的列表,0因此可容纳与我们列表相同的人数。这些列表可能是一个不错的起点。
如果仅使用距离为的前五个值0,则我们的预测将偏向于数据集的现有排序。相反,我们将随机化观测值的顺序,然后选择距离为的前五行0。我们将用于DataFrame.sample()随机化行。此方法通常用于选择DataFrame的随机部分,但是我们将告诉它随机选择100%,这将为我们随机地洗排行。
我们还将使用random_state仅给我们可重现的随机顺序的参数,以便任何人都可以遵循并获得完全相同的结果。
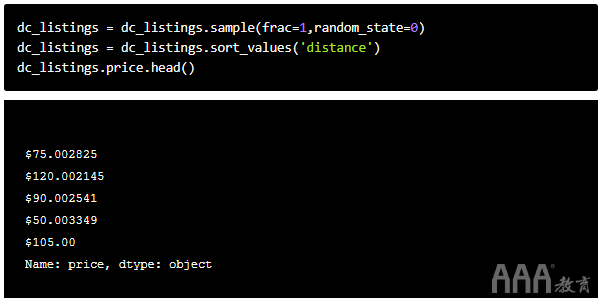
在我们取平均价格之前,您会注意到我们的价格列具有object类型,这是因为价格具有美元符号和逗号(我们上面的示例未显示逗号,因为所有值都较小超过$ 1000)。
float在计算前五个值的平均值之前,让我们通过删除这些字符并将其转换为类型来清理此列。我们将使用pandas Series.str.replace()删除流浪字符并传递\$|,与$或匹配的正则表达式,。
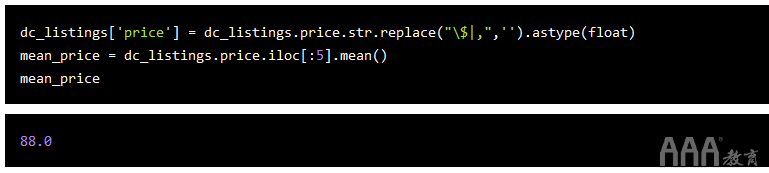
现在,我们已经做出了第一个预测-我们的KNN模型告诉我们,当我们仅使用该accommodates功能时,为三人房列表找到合适的价格,我们应该以$ 88.00的价格列出我们的公寓。
这是一个好的开始!问题是,我们没有任何方法可以知道此模型的准确性,因此无法进行优化和改进。遵循任何机器学习模型的预测而不评估其准确性不是一个好主意!
评估我们的模型
测试模型质量的一种简单方法是:
a)将数据集分为2个分区:
1)一个训练集:包含了大多数的行(75%)
2)甲测试集:包含行的其余少数(25%)
b)使用训练集中的行来预测price测试集中的行的值
c)将预测值与price测试集中的实际值进行比较,以查看预测值的准确性。
我们要按照这个方法和3,723行我们的数据集分为两个部分:train_df和test_df在75%-25%分割。
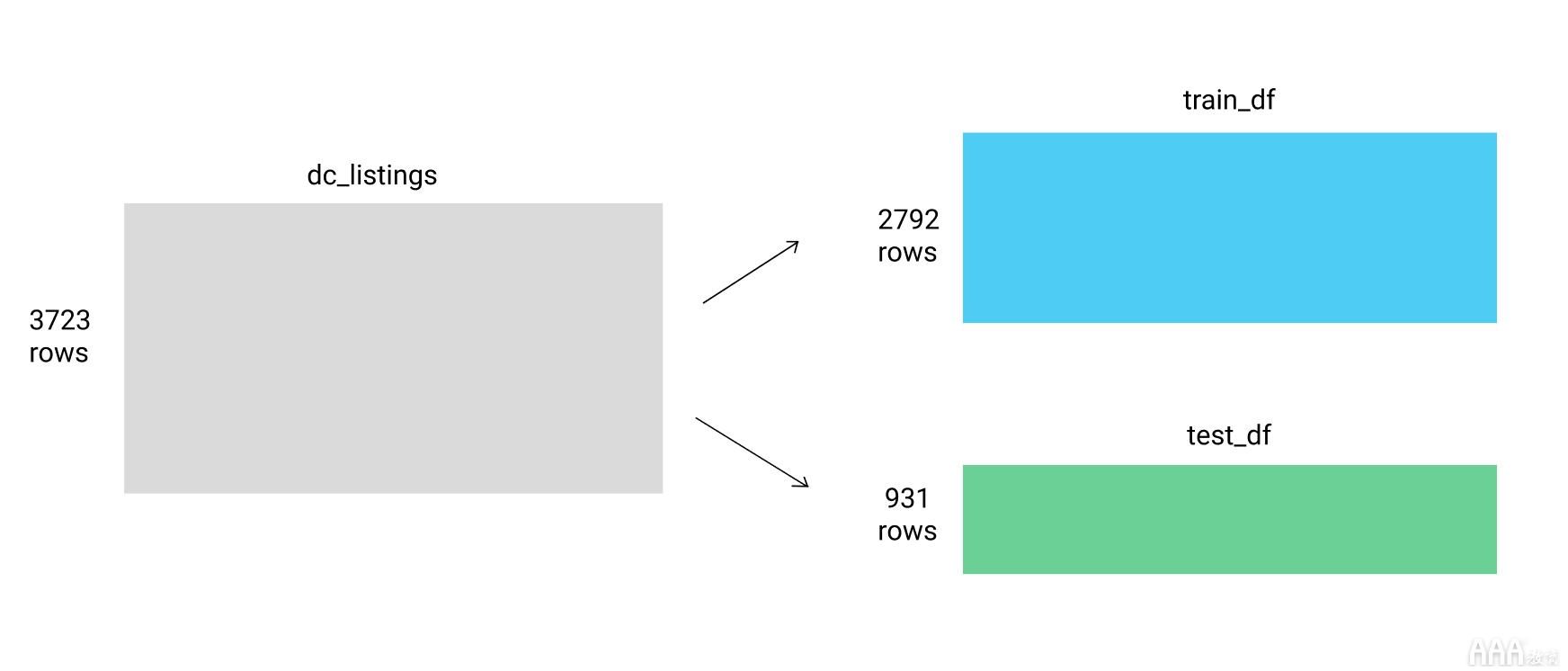
我们还将删除我们在创建第一个模型时先前添加的列。

为了使我们自己更轻松地查看指标,我们会将之前制作的模型合并为一个函数。我们不必担心对行进行随机化,因为它们仍是较早前随机化的。
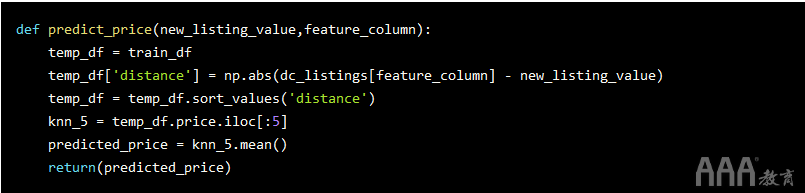
现在,我们可以使用此函数使用该accommodates列来预测测试数据集的值。

使用RMSE评估我们的模型
对于许多预测任务,我们希望对远离实际值的预测值的惩罚要远大于接近实际值的预测值。
为此,我们可以取平方误差值的平均值,称为均方根误差(RMSE)。下面是RMSE下式:,其中表示的数量测试集中的行。起初,这个公式可能看起来很让人不知所措,但我们要做的只是:

a)取每个预测值与实际值(或误差)之差,
b)平方这个差(平方),
c)取所有平方差的平均值(均值),然后
d)取均值的平方根(根)。
因此,从下往上读取:均方根误差。让我们为测试集上的预测计算RMSE值。
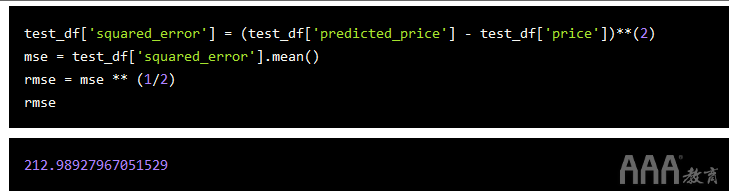
RMSE约为213美元。关于RMSE的一件方便的事是,因为我们先平方然后取平方根,所以RMSE的单位与我们预测的值相同,这使我们易于理解错误的范围。
在这种情况下,规模很大-我们离准确的预测还差得远。
比较不同型号
有了一个误差指标,我们可以用来查看模型的准确性,让我们使用不同的列创建一些预测,并研究误差的变化情况。
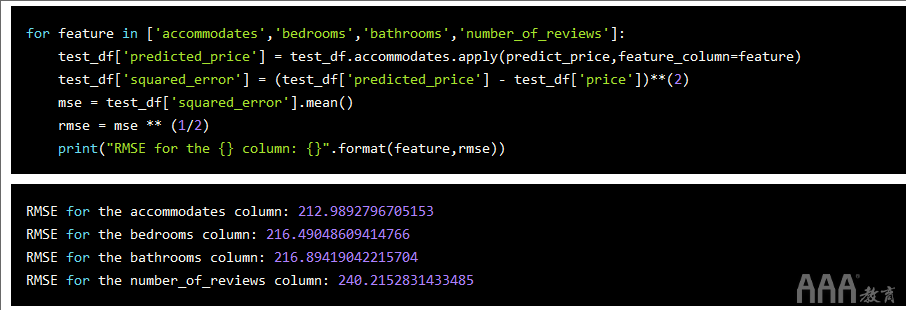
我们可以看到,我们训练的四个模型中最好的模型是使用该accomodates列的模型。
但是,相对于数据集中列表的价格范围,我们得到的错误率非常高。这类错误率的预测不会很有帮助。
值得庆幸的是,我们可以做些什么!到目前为止,我们仅使用一种功能(称为单变量模型)来训练模型。为了获得更高的准确性,我们可以让它同时评估多个特征,这被称为多元模型。
我们将阅读此数据集的完整版本,以便我们可以专注于评估模型。在我们清理的数据集中:
a)由于我们无法计算具有非数字字符的值的欧几里得距离,因此所有列均已转换为数字值。
b)为简单起见,非数字列已被删除。
c)缺少值的所有列表均已删除。
d)我们对列进行了归一化,这将为我们提供更准确的结果。
如果您想了解有关数据清理和为机器学习准备数据的更多信息,可以阅读出色的文章为机器学习准备和清理数据。
让我们阅读这个干净的版本,称为dc_租房平台.normalized.csv,并预览前几行:

我们将从建立使用accommodates和bathrooms功能的模型开始。对于这种情况,我们的欧几里得方程应为:
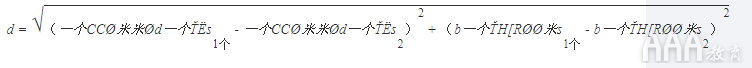
为了找到两个生活空间之间的距离,我们需要计算两个accommodates值之间的平方差,两个bathrooms值之间的平方差,将它们相加,然后取所得总和的平方根。
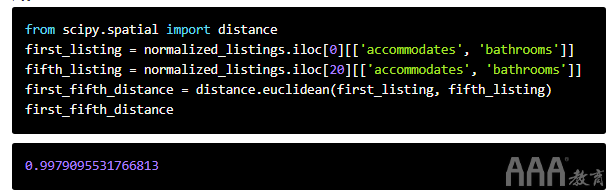
这是前两行之间的欧式距离normalized_listings:

到目前为止,我们已经通过自己编写方程的逻辑来自己计算欧几里得距离。我们可以改用from中的distance.euclidean()函数scipy.spatial,该函数将两个向量作为参数并计算它们之间的欧式距离。该euclidean()函数期望:
1)这两个向量都将使用类似列表的对象(Python列表,NumPy数组或pandas系列)来表示
2)两个向量都必须是一维的并且具有相同数量的元素
让我们使用该euclidean()函数来计算要练习的数据集中第一行和第五行之间的欧几里得距离。
创建多元KNN模型
我们可以扩展先前的功能以使用两个功能以及整个数据集。而不是distance.euclidean(),我们将使用distance.cdist(),因为它允许我们一次传递多行。
(该cdist()方法可以使用多种方法来计算距离,但默认为欧几里得。)
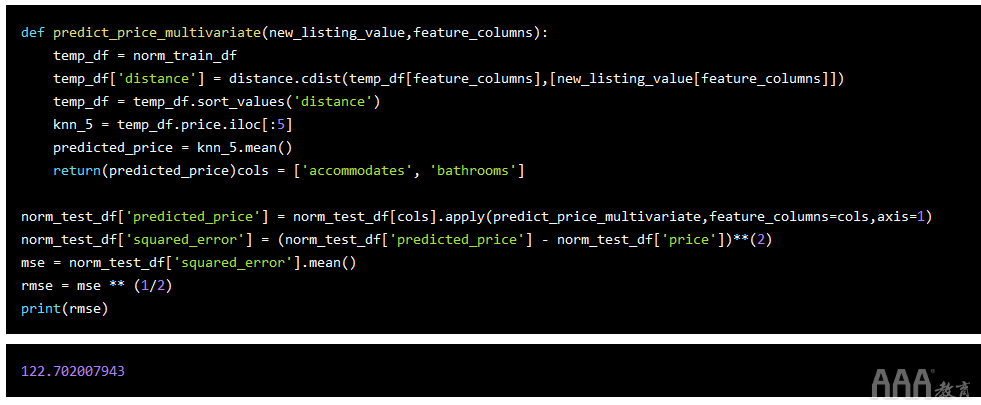
您可以看到,使用两项功能(而不只是)时,我们的RMSE从212提高到122 accommodates。尽管它仍然不如我们希望的那样准确,但这是一个巨大的改进。
scikit-learn简介
我们一直在从头开始编写函数来训练我们的k近邻模型。这有助于了解机制的工作原理,但是现在我们了解了基础知识,便可以使用Python的scikit-learn库更快,更高效地工作。
Scikit-learn是Python中最受欢迎的机器学习库。它具有适用于所有主要机器学习算法的内置功能以及简单,统一的工作流程。这两个属性使大数据分析家在新数据集上训练和测试不同的模型时,工作效率令人难以置信。
scikit-learn工作流程包括四个主要步骤:
a)实例化您要使用的特定机器学习模型。
b)使模型适合训练数据。
c)使用模型进行预测。
d)评估预测的准确性。
scikit-learn中的每个模型都是作为单独的类实现的,第一步是识别我们要为其创建实例的类。
任何可以帮助我们预测数值的模型(例如模型中的上市价格)都称为回归模型。机器学习模型的另一个主要类别称为分类。当我们尝试从一组固定的标签(例如血型或性别)中预测标签时,将使用分类模型。
在我们的例子中,我们想使用KNeighborsRegressor类。这个词回归从类名KNeighborsRegressor是指回归模型类,我们刚才讨论的,而“KNeighbors”来自k-最近邻模型中,我们正在构建。
Scikit-learn使用类似于Matplotlib的面向对象的样式。我们需要在调用其他构造函数之前实例化一个空模型。

如果参考文档,默认情况下我们会注意到:
1)n_neighbors:邻居数,设置为 5
2)algorithm:用于计算最近的邻居,设置为 auto
3)p:设置为2,对应于欧几里得距离
让我们将algorithm参数设置为,brute并将n_neighbors值保留为5,这与我们构建的手动实现相匹配。

拟合模型并做出预测
现在,我们可以使用fit方法使模型适合数据。对于所有模型,该fit方法均采用两个必需参数:
1)类似于矩阵的对象,其中包含我们要从训练集中使用的要素列。
2)包含正确目标值的类似列表的对象。
“类矩阵对象”意味着该方法非常灵活,可以接受pandas DataFrame或NumPy 2D数组。这意味着我们可以从DataFrame中选择要使用的列,并将其用作该fit方法的第一个参数。
对于第二个参数,请回想一下,以下所有都是可接受的类似列表的对象:
1)一个NumPy数组
b)Python列表
c)pandas系列对象(例如列)
让我们从DataFrame中选择目标列,并将其用作方法的第二个参数fit:

fit()调用该方法时,scikit-learn将在KNearestNeighbors实例(knn)中存储我们指定的训练数据。如果我们尝试将包含缺失值或非数字值的数据传递到fit方法中,则scikit-learn将返回错误。那是该库的妙处之一–它包含许多类似的功能,以防止我们犯错误。
现在,我们已经指定了要用于预测的训练数据,我们可以使用预测方法对测试集进行预测。该predict方法只有一个必需的参数:
类似于矩阵的对象,其中包含我们要进行预测的数据集中的特征列
我们在培训和测试期间使用的功能列数需要匹配或scikit-learn会返回错误。

该predict()方法返回一个NumPy数组,其中包含price测试集的预测值。
现在,我们拥有练习整个scikit-learn工作流程所需的一切:

当然,仅仅因为我们使用scikit-learn而不是手动编写函数,并不意味着我们可以跳过评估步骤,以了解模型预测的实际准确性!
使用Scikit-Learn计算MSE
到目前为止,我们一直使用NumPy和SciPy函数来协助我们手动计算RMSE值。或者,我们可以改用sklearn.metrics.mean_squared_error function()。
该mean_squared_error()函数接受两个输入:
1)类似于列表的对象,代表测试集中的真实值。
2)第二个类似列表的对象,代表由模型生成的预测值。
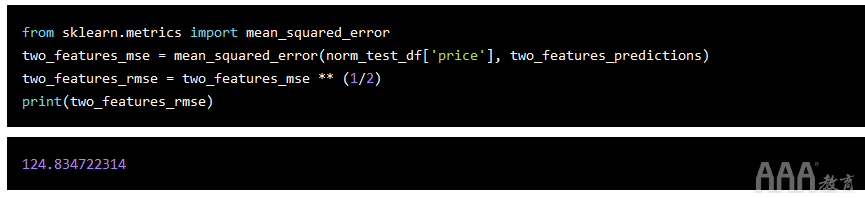
从语法的角度来看,这不仅简单得多,而且由于scikit-learn已针对速度进行了大幅优化,因此运行模型所需的时间更少。
请注意,我们的RMSE与手动实现的算法略有不同-这可能是由于随机差异以及我们的“手动” KNN算法与scikit-learn版本之间在实现上的细微差异。
请注意,对scikit-learn库本身的更改也会在一定程度上影响这些值。如果您按照用Python搭建机器学习模型预测房租价格进行操作,但结果略有不同,则可能是因为您使用的是scikit-learn的较新版本。
使用更多功能
scikit-learn最好的事情之一是它使我们可以更快地进行迭代。让我们通过创建一个使用四个特征而不是两个特征的模型来进行尝试,看看是否可以改善我们的结果。
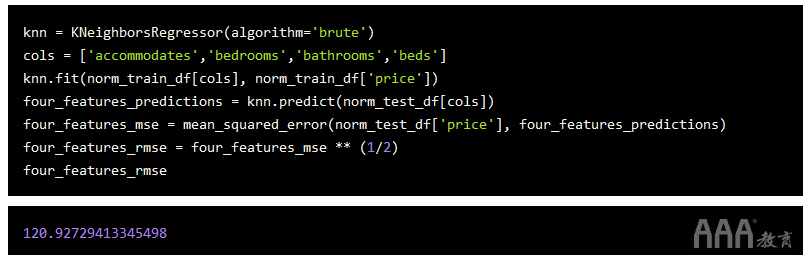
在这种情况下,我们的错误略有下降。但是,添加功能时可能并不总是这样做。这是要意识到的重要事项:添加更多功能并不一定会产生更准确的模型。
这是因为添加不是目标变量的准确预测指标的功能会在模型中添加“噪声”。
摘要
让我们看看我们学到了什么:
我们了解了什么是机器学习,并通过了一个非常基本的手动“模型”来预测房屋的销售价格。
我们了解了k最近邻居算法,并从头开始在Python中建立了一个单变量模型(仅一个功能),并用其进行了预测。
我们了解到,RMSE可用于计算模型的误差,然后可用于迭代和尝试改善我们的预测。
然后,我们从头开始创建了一个多变量(多个功能)模型,并将其用于更好的预测。
最后,我们了解了scikit-learn库,并使用KNeighborsRegressor该类进行了预测。
下一步
如果您想了解更多信息,那么用Python搭建机器学习模型预测房租价格基于我们的AAA教育机器学习基础课程,这是我们的大数据分析学习路径的一部分。用Python搭建机器学习模型预测房租价格将详细介绍并改进本文中构建的模型,同时使您可以继续进行,在浏览器中编写代码,并通过我们的答案检查系统对代码进行每一步检查,以确保您正确执行所有操作。
如果您想自己继续研究此模型,可以采取以下几项措施来提高准确性:
a)尝试用不同的值代替k。
b)返回原始数据集,并将我们删除的一些列转换为数字(我们的“机器学习的准备和清洁数据”一文将在这里为您提供帮助),并尝试添加不同的功能组合。
c)尝试一些功能工程,在其中您可以基于现有数据创建新列:我们的Kaggle入门:房价竞争一文提供了一个简单的示例。
填写下面表单即可预约申请免费试听!怕钱不够?可先就业挣钱后再付学费! 怕学不会?助教全程陪读,随时解惑!担心就业?一地学习,可推荐就业!
©2007-2022/ www.aaa-cg.com.cn 北京漫动者数字科技有限公司 备案号: 京ICP备12034770号 监督电话:010-53672995 邮箱:bjaaa@aaaedu.cc

 热门推荐
热门推荐
 UI设计
UI设计
 产品经理
产品经理
 大数据分析
大数据分析
 原画设计
原画设计
 平面设计
平面设计
 新媒体运营
新媒体运营 






