要了解什么是Hadoop,我们必须首先了解与大数据和传统处理系统有关的问题。前进,我们将讨论什么是Hadoop,以及Hadoop如何解决与大数据相关的问题。我们还将研究CERN案例研究,以突出使用Hadoop的好处。
在之前的博客“ 大数据教程”中,我们已经详细讨论了大数据以及大数据的挑战。在此博客中,我们将讨论:
1、传统方法的问题
2、Hadoop的演变
3、Hadoop的
4、Hadoop即用解决方案
5、何时使用Hadoop?
6、什么时候不使用Hadoop?
一、CERN案例研究
大数据正在成为组织的机会。现在,组织已经意识到他们可以通过大数据分析获得很多好处,如下图所示。他们正在检查大型数据集,以发现所有隐藏的模式,未知的相关性,市场趋势,客户偏好和其他有用的业务信息。
这些分析结果正在帮助组织进行更有效的营销,新的收入机会,更好的客户服务。他们正在提高运营效率,与竞争对手组织相比的竞争优势以及其他业务利益。
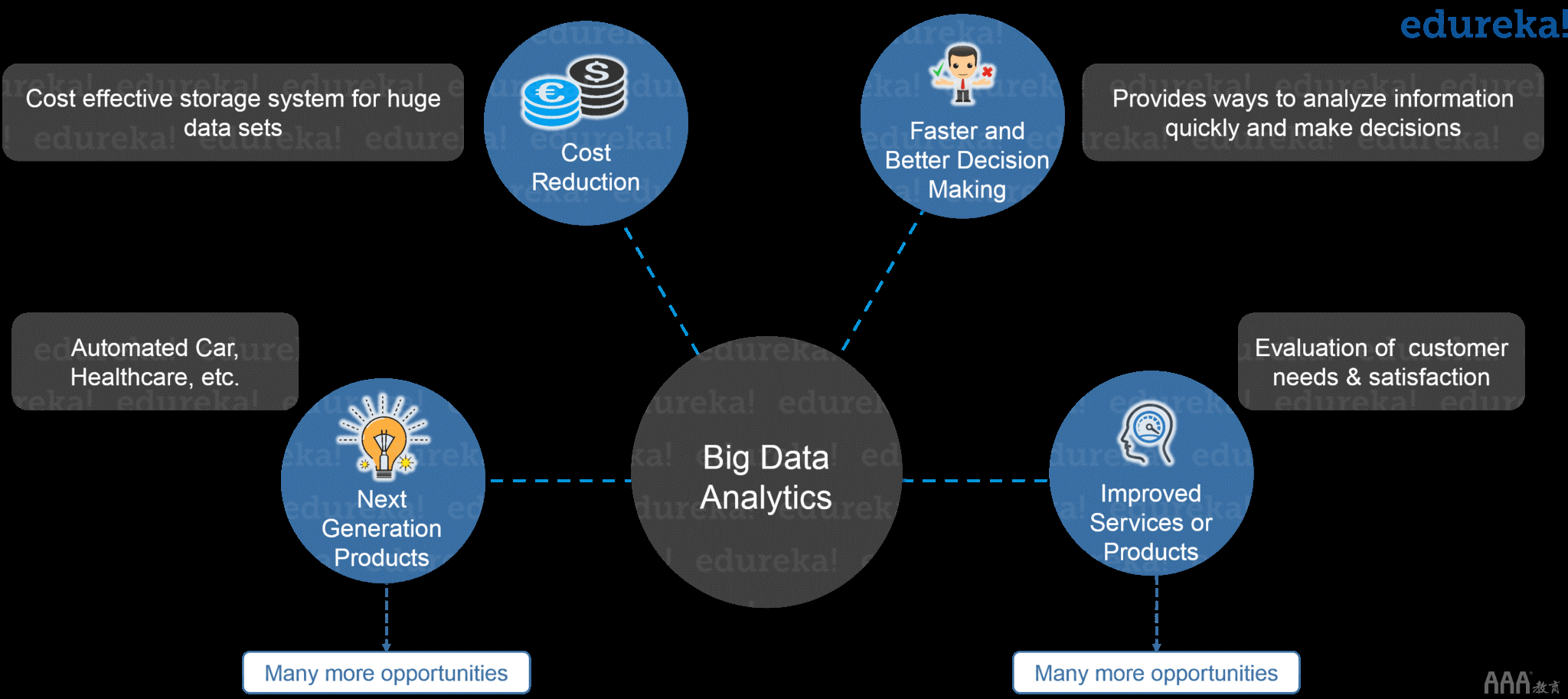
什么是Hadoop –大数据分析的好处
因此,让我们继续前进,了解在兑现大数据机会方面与传统方法相关的问题。
二、传统方法的问题
在传统方法中,主要问题是处理数据的异构性,即结构化,半结构化和非结构化。RDBMS主要关注于银行交易,运营数据等结构化数据,而Hadoop则专注于文本,视频,音频,Facebook帖子,日志等半结构化,非结构化数据。RDBMS技术是一种经过验证的,高度一致,成熟的系统许多公司的支持。另一方面,由于大数据(主要由不同格式的非结构化数据组成)对Hadoop提出了需求。
现在让我们了解与大数据相关的主要问题是什么。因此,继续前进,我们可以了解Hadoop是如何成为解决方案的。
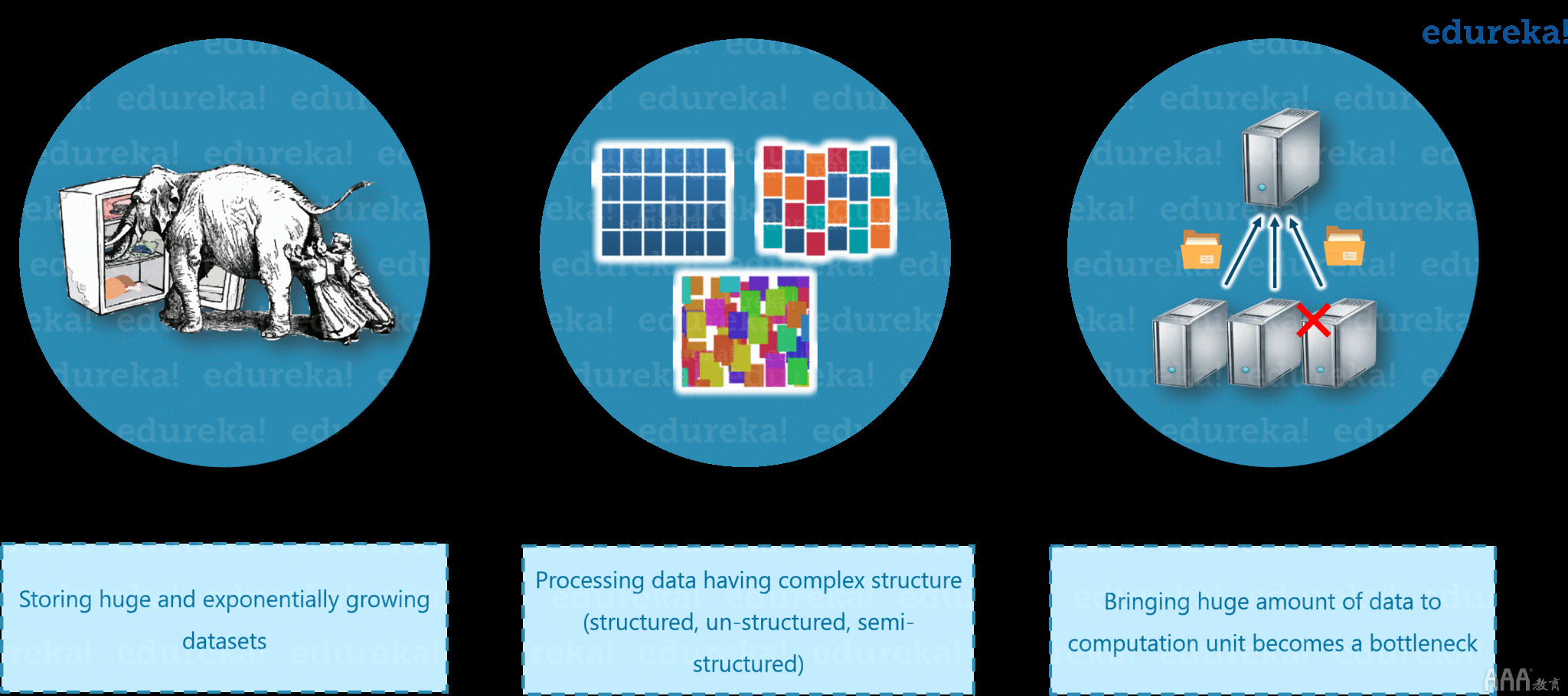
什么是Hadoop –大数据问题
第一个问题是存储大量数据。
无法在传统系统中存储大量数据。原因很明显,存储将仅限于一个系统,并且数据正在以惊人的速度增长。
第二个问题是存储异构数据。
现在,我们知道存储是一个问题,但是让我告诉您,这只是问题的一部分。由于我们讨论了数据不仅庞大,而且还以各种格式存在,例如:非结构化,半结构化和结构化。因此,您需要确保您拥有一个系统来存储从各种来源生成的所有这些种类的数据。
第三个问题是访问和处理速度。
硬盘容量正在增加,但磁盘传输速度或访问速度并未以相似的速度增加。让我以一个示例为您进行解释:如果您只有一个100 Mbps I / O通道,并且正在处理1TB数据,则大约需要2.91个小时。现在,如果您有四台具有一个I / O通道的计算机,则对于相同数量的数据,大约需要43分钟。因此,与存储大数据相比,访问和处理速度是更大的问题。
在了解什么是Hadoop之前,让我们首先了解一下Hadoop在一段时间内的发展。
Hadoop的演变
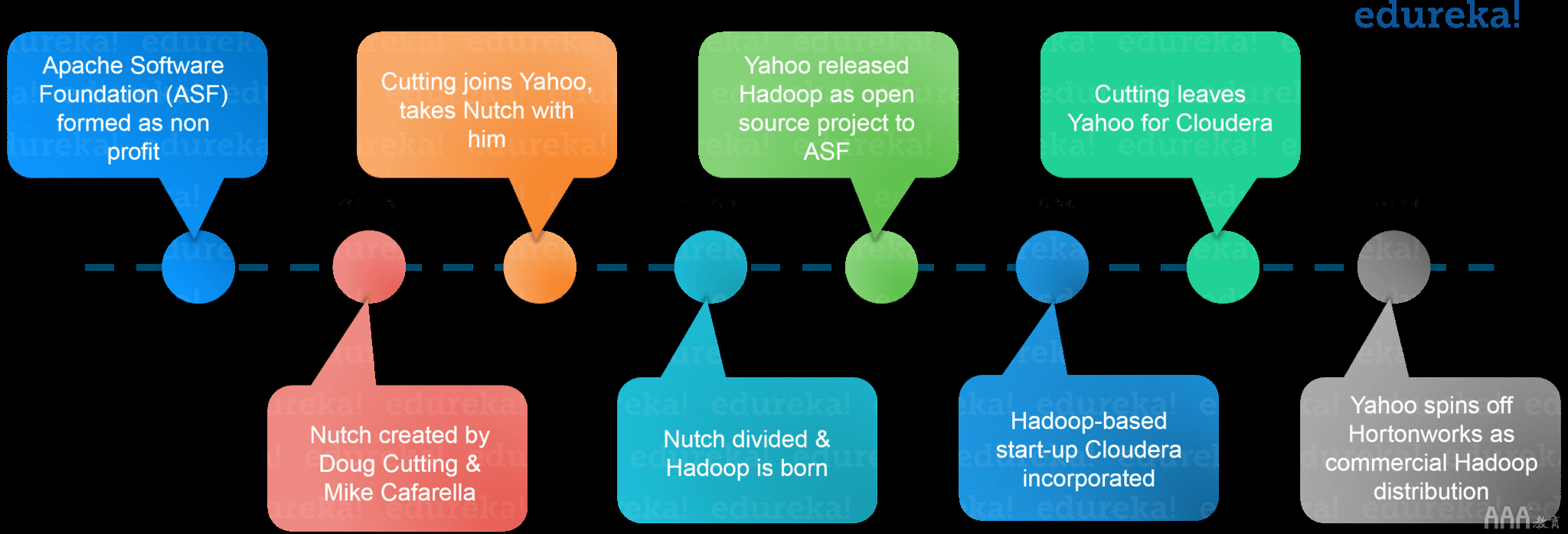
2003年,道格·切特(Doug Cutting)启动了Nutch项目,以处理数十亿次搜索并为数百万个网页建立索引。2003年10月下旬– Google发布带有GFS(Google文件系统)的论文。2004年12月,Google发布了MapReduce论文。在2005年,Nutch使用GFS和MapReduce进行操作。2006年,雅虎与Doug Cutting及其团队合作,基于GFS和MapReduce创建了Hadoop。如果我告诉您,您会感到惊讶,雅虎于2007年开始在1000个节点的群集上使用Hadoop。
2008年1月下旬,雅虎向Apache Software Foundation发布了Hadoop作为一个开源项目。2008年7月,Apache通过Hadoop成功测试了4000个节点的集群。2009年,Hadoop在不到17小时的时间内成功整理了PB级数据,以处理数十亿次搜索并为数百万个网页建立索引。在2011年12月,Apache Hadoop发布了1.0版。2013年8月下旬,发布了2.0.6版。
当我们讨论这些问题时,我们发现分布式系统可以作为解决方案,而Hadoop提供了相同的解决方案。现在,让我们了解什么是Hadoop。
三、什么是Hadoop?
Hadoop是一个框架,它允许您首先在分布式环境中存储大数据,以便可以并行处理它。 Hadoop中基本上有两个组件:
1、大数据Hadoop认证培训
2、讲师指导的课程现实生活中的案例研究评估终身访问探索课程

什么是Hadoop – Hadoop框架
第一个是用于存储的HDFS(Hadoop分布式文件系统),它使您可以在集群中存储各种格式的数据。第二个是YARN,用于Hadoop中的资源管理。它允许对数据进行并行处理,即跨HDFS存储。
让我们首先了解HDFS。
HDFS
HDFS创建一个抽象,让我为您简化一下。与虚拟化类似,您可以在逻辑上将HDFS视为用于存储大数据的单个单元,但是实际上您是在分布式方式下跨多个节点存储数据。HDFS遵循主从架构。
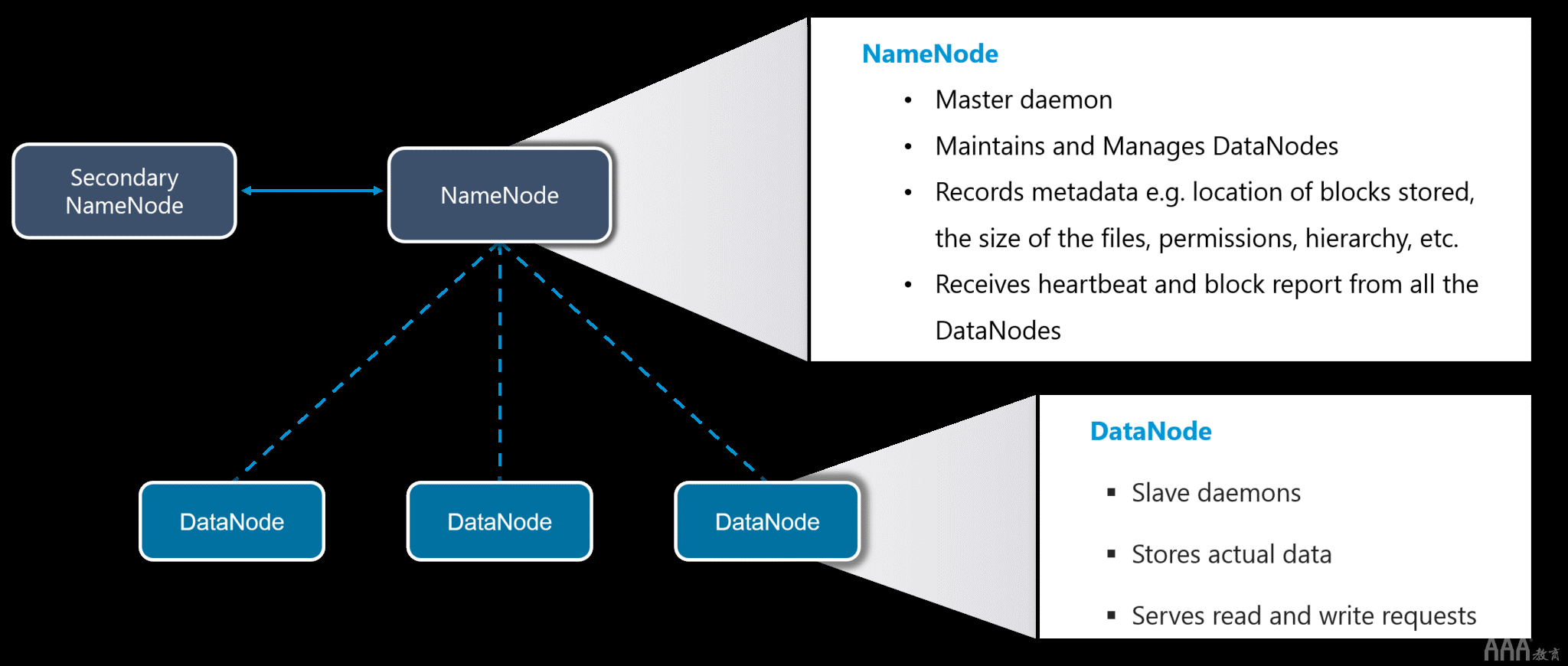
什么是Hadoop – HDFS
在HDFS中,名称节点是主节点,数据节点是从节点。 Namenode包含有关存储在Data节点中的数据的元数据,例如哪个数据块存储在哪个数据节点中,数据块的复制位置在哪里等 。实际数据存储在Data Nodes中。
我还想补充一下,实际上我们复制了数据节点中存在的数据块,默认复制因子是3。 由于我们使用的是商用硬件,并且我们知道这些硬件的故障率很高,所以如果其中一个DataNodes失败,HDFS将仍然具有那些丢失的数据块的副本。 您还可以根据需要配置复制因子。您可以阅读HDFS教程,详细了解HDFS。
四、Hadoop即解决方案
让我们了解Hadoop如何为刚刚讨论的大数据问题提供解决方案。
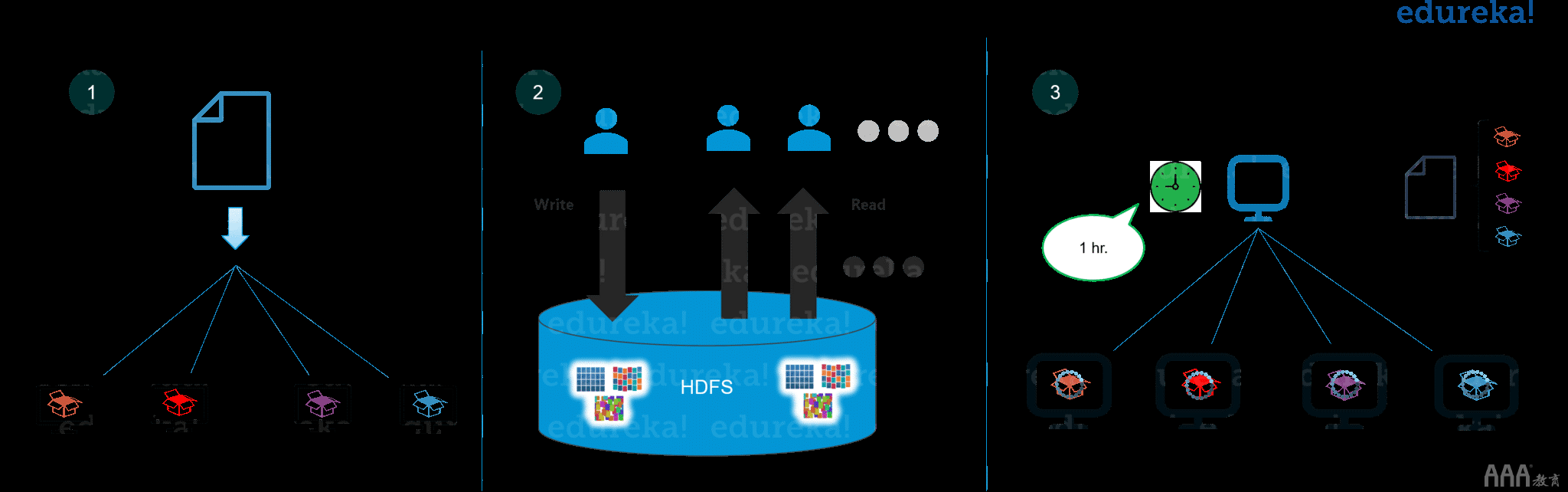
什么是Hadoop – Hadoop即解决方案
第一个问题是存储大数据。
HDFS提供了一种分布式大数据存储方式。您的数据存储在整个DataNode的块中,您可以指定块的大小。基本上,如果您拥有512MB的数据,并且已经配置了HDFS,那么它将创建128MB的数据块。 因此,HDFS将数据分为512/128 = 4的4个块,并将其存储在不同的DataNode上,还将在不同的DataNode上复制数据块。现在,由于我们正在使用商品硬件,因此存储已不是难题。
它还解决了缩放问题。它着重于水平缩放而不是垂直缩放。您始终可以根据需要随时在HDFS群集中添加一些额外的数据节点,而不是扩展DataNodes的资源。让我为您总结一下,基本上是用于存储1 TB的数据,您不需要1 TB的系统。您可以在多个128GB或更少的系统上执行此操作。
下一个问题是存储各种数据。
借助HDFS,您可以存储各种数据,无论是结构化,半结构化还是非结构化。由于在HDFS中,没有预转储模式验证。并且它也遵循一次写入和多次读取模型。因此,您只需写入一次数据,就可以多次读取数据以寻找见解。
Hird的挑战是访问和处理数据更快。
是的,这是大数据的主要挑战之一。为了解决该问题,我们将处理移至数据,而不是将数据移至处理。这是什么意思?而不是将数据移动到主节点然后进行处理。在MapReduce中,处理逻辑被发送到各个从属节点,然后在不同的从属节点之间并行处理数据。然后,将处理后的结果发送到主节点,在该主节点上合并结果,并将响应发送回客户端。
在YARN架构中,我们有ResourceManager和NodeManager。ResourceManager可能会或可能不会与NameNode配置在同一台机器上。 但是,应该将NodeManager配置在存在DataNode的同一台计算机上。
YARN通过分配资源和安排任务来执行您的所有处理活动。
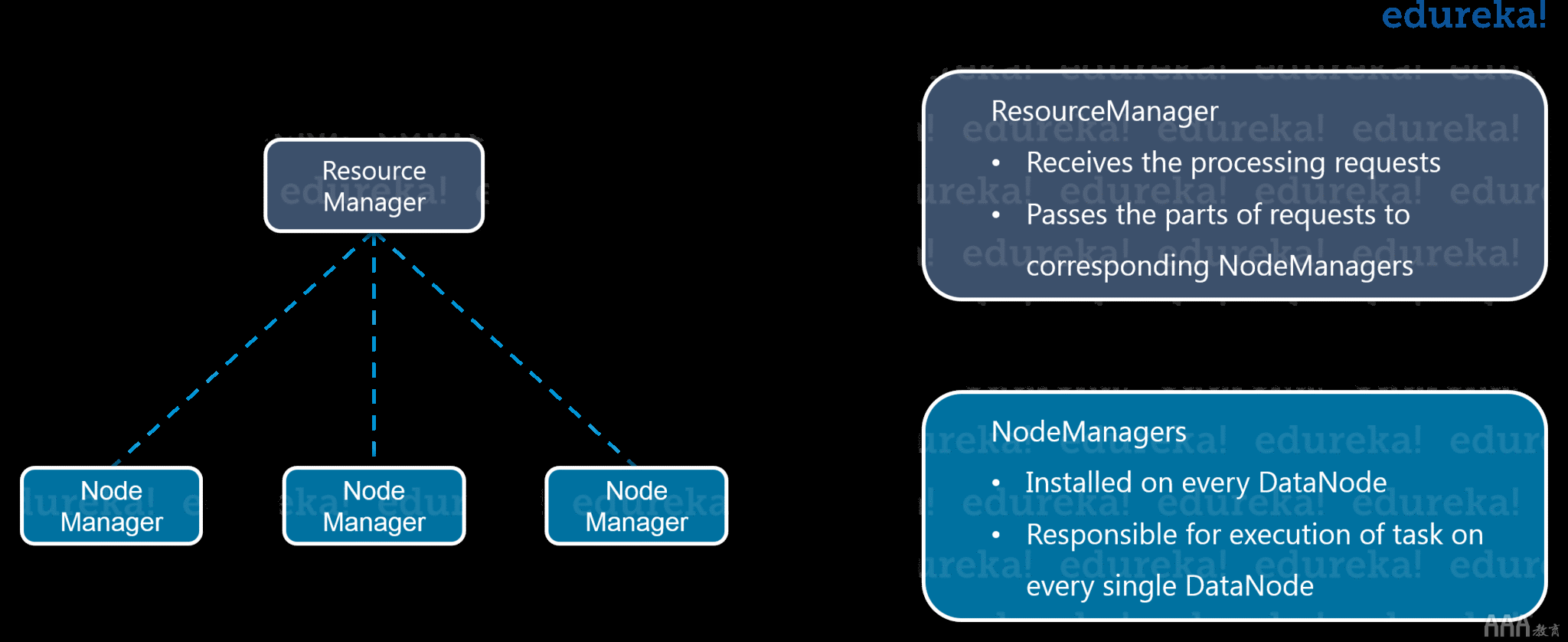
什么是Hadoop – YARN
它具有两个主要组件,即ResourceManager和NodeManager。
ResourceManager再次是主节点。它接收处理请求,然后将请求的各个部分相应地传递到相应的NodeManager,在此进行实际处理。NodeManager安装在每个DataNode上。它负责在每个单个DataNode上执行任务。
我希望现在您对什么是Hadoop及其主要组件有所了解。让我们继续前进,了解何时使用和何时不使用Hadoop。
何时使用Hadoop?
Hadoop用于:
1、搜索 – Yahoo,亚马逊,Zvents
2、日志处理 – Facebook,雅虎
3、数据仓库 – Facebook,AOL
4、视频和图像分析 –纽约时报,Eyealike
到目前为止,我们已经看到了Hadoop如何使大数据处理成为可能。但是在某些情况下,不建议使用Hadoop。
什么时候不使用Hadoop?
以下是其中一些方案:
1、低延迟数据访问:快速访问少量数据
2、多种数据修改:仅当我们主要关注读取数据而不修改数据时,Hadoop才是更好的选择。
3、大量小文件:Hadoop适用于只有少量大文件的情况。
在了解了最合适的用例之后,让我们继续研究Hadoop创造奇迹的案例研究。
Hadoop-CERN案例研究
瑞士的大型强子对撞机是世界上最大,功能最强大的机器之一。它配备了约1.5亿个传感器,每秒产生PB的数据,并且数据在不断增长。
欧洲核子研究组织(CERN)的研究表明,这些数据在数量和复杂性方面一直在扩大,其中一项重要任务是满足这些可扩展的需求。因此,他们设置了Hadoop集群。通过使用Hadoop,他们限制了硬件成本和维护复杂性。
他们整合了Oracle和Hadoop,并获得了整合的优势。 Oracle优化了他们的在线交易系统和Hadoop,为他们提供了可扩展的分布式数据处理平台。他们设计了一个混合系统,首先将数据从Oracle迁移到Hadoop。然后,他们使用Oracle API对来自Oracle的Hadoop数据执行查询。他们还使用诸如 Avro& Parquet之类的Hadoop数据格式进行高性能分析,而无需更改连接到Oracle的最终用户应用程序。
他们在CERN-IT Hadoop服务上使用的主要Hadoop组件:
1、您可以在Hadoop生态系统中了解每个工具。
2、集成Oracle和Hadoop的技术:
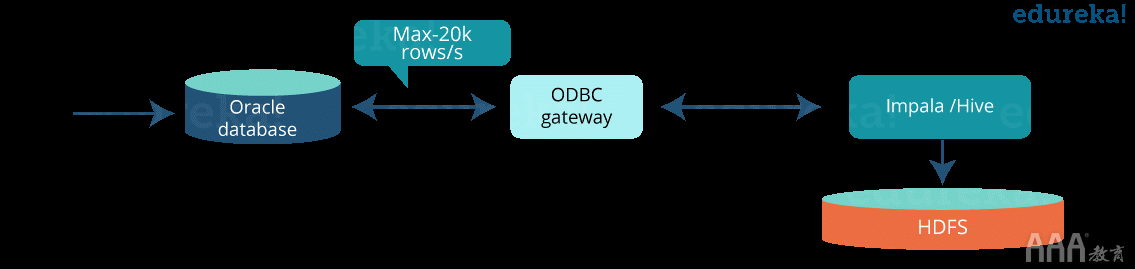
3、将数据从Oracle导出到HDFS
4、Sqoop在大多数情况下都足够好,他们还采用了其他一些可能的选项,例如自定义提取,Oracle DataPump,流式传输等。
从Oracle查询Hadoop
他们使用Oracle中的数据库链接访问了Hadoop引擎中的表。通过透明地组合Oracle和Hadoop中的数据,还可以构建混合视图。
使用Hadoop框架处理Oracle数据库中的数据
他们使用Hadoop引擎(例如Impala,Spark)来处理从Oracle导出的数据,然后直接在JDBC中从Spark SQL在RDBMS中读取该数据。
|
1个
2
3
|
create database link my_hadoop using 'impala-gateway';select * from big_table@my_hadoop where col1= :val1; |
从Oracle卸载到Hadoop
步骤1:将数据卸载到Hadoop
步骤2:将查询卸载到Hadoop
步骤3:从Oracle查询访问Hadoop
使用数据库链接从Oracle查询Apache Hive / Impala表
通过ODBC网关将查询分载到Impala(或Hive)
在oracle上创建混合视图的示例
根据CERN的案例研究,我们可以得出以下结论:
|
1个
2
3
4
5
6
7
|
create view hybrid_view as select * from online_table where date > '2016-10-01' union all select * from archive_table@hadoop where date <= '2016-10-01' |
1、Hadoop具有可伸缩性,非常适合大数据分析
2、Oracle已证明可用于并发事务性工作负载
3、解决方案可用于集成Oracle和Hadoop
4、使用混合系统(Oracle + Hadoop)具有巨大的价值:
5、适用于旧版应用程序和OLTP工作负载的Oracle API
6、用于分析工作负载的商品硬件的可伸缩性
我希望这个博客能为您提供丰富的信息,并为您的知识增加价值。在我们的Hadoop教程系列的下一个博客(即Hadoop教程)中,我们将更详细地讨论Hadoop,并详细了解HDFS和YARN组件的任务。
既然您已经了解了什么是Hadoop,请查看Edureka 的Hadoop培训,Edureka是一家受信任的在线学习公司,其网络遍布全球,共有250,000多名满意的学习者。Edureka大数据Hadoop认证培训课程使用零售,社交媒体,航空,旅游,金融领域的实时用例,帮助学习者成为HDFS,Yarn,MapReduce,Pig,Hive,HBase,Oozie,Flume和Sqoop的专家。
填写下面表单即可预约申请免费试听!怕钱不够?可先就业挣钱后再付学费! 怕学不会?助教全程陪读,随时解惑!担心就业?一地学习,可推荐就业!
©2007-2022/ www.aaa-cg.com.cn 北京漫动者数字科技有限公司 备案号: 京ICP备12034770号 监督电话:010-53672995 邮箱:bjaaa@aaaedu.cc

 热门推荐
热门推荐
 UI设计
UI设计
 产品经理
产品经理
 大数据分析
大数据分析
 原画设计
原画设计
 平面设计
平面设计
 新媒体运营
新媒体运营 






