进行调查和民意调查是收集数据和深入了解诸如客户为何离开我们网站等问题的最佳方法之一。还是为什么选民会吸引这位候选人?但是分析调查数据可能是一个真正的挑战!
在本教程中,我们将逐步介绍如何使用Python分析调查数据。但是不用担心-即使您以前从未编写过代码,也可以处理!我们将逐步进行它,到本教程结束时,您将看到如何仅用几行代码就能释放出相当不错的分析能力!
出于本文的目的,我们将分析StackOverflow的2019年开发人员调查数据,因为这是一个公开的,经过适当匿名的大型调查数据集。但是这些技术将适用于几乎所有类型的调查数据。
大多数调查数据的格式与我们在此处使用的格式类似:电子表格,其中每一行包含一个人的答案,而每一列包含特定问题的所有答案。这是我们的数据集的一个片段;您的外观可能相似。
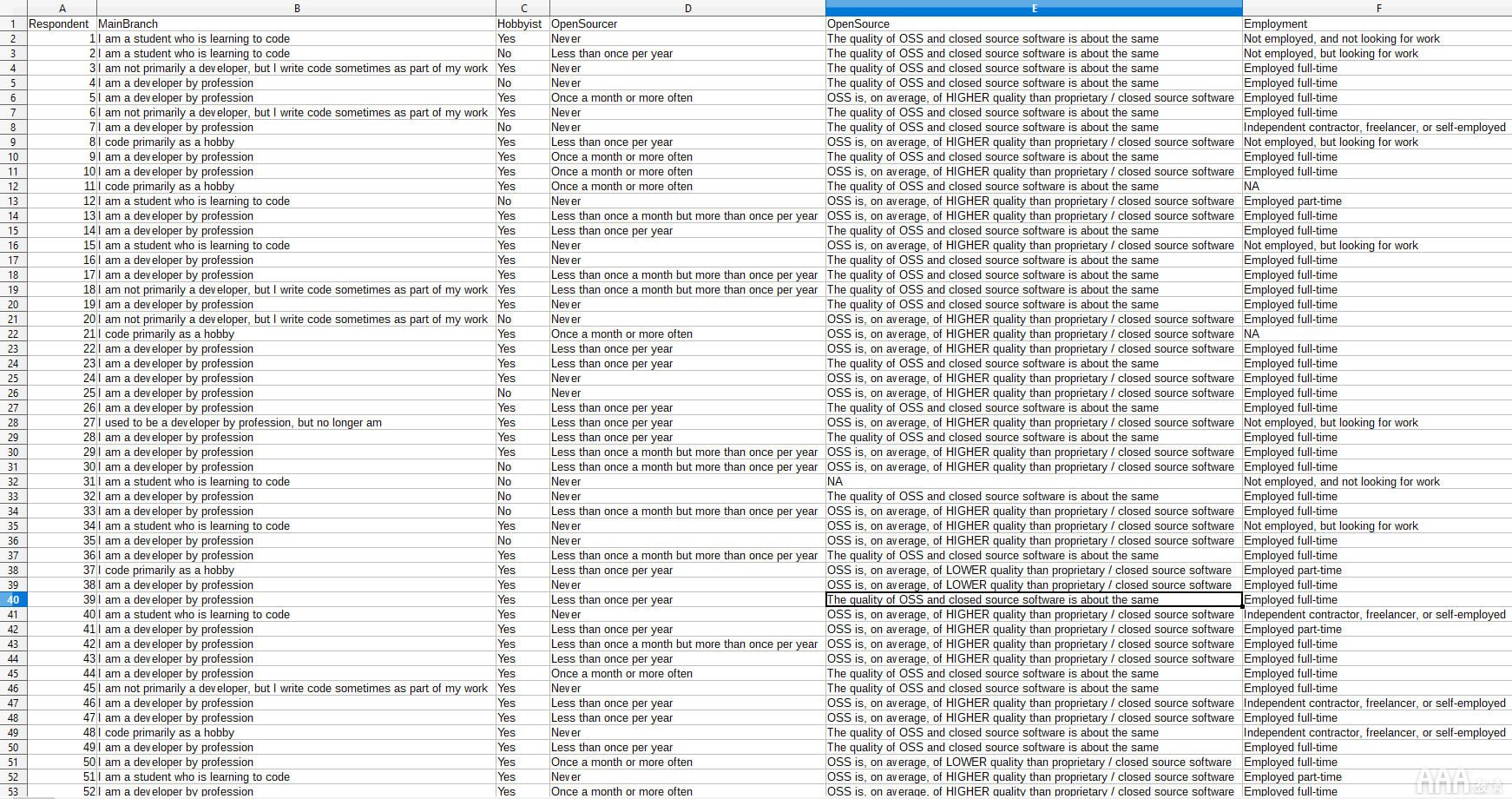
现在,让我们深入分析这些数据!我们将从几个快速步骤开始,以进行分析。
步骤1:以CSV档案的形式取得问卷调查回应
要使用代码分析调查数据,我们需要以.csv文件的形式获取它。如果您想使用与我们相同的数据集来完成本教程,则可以在此处获取2019 StackOverflow开发人员调查结果数据,该数据已经作为CSV文件(在文件内部.zip)准备好了。
如果您想开始使用自己的数据,请按照以下方式以CSV格式获取数据:
a.如果您运行在线调查,则可能可以直接从所使用的调查服务下载CSV。Typeform和许多其他在线调查工具将使您能够下载包含所有调查回复的CSV,这使事情变得轻松而简单。
b.如果您使用Google表格进行调查,那么您的数据将以在线Google表格的形式提供。在Google表格界面中,点击File > Download,然后选择Comma-separated values (.csv, current sheet)以CSV格式下载数据。
c.如果您以其他方式收集了数据,但是以电子表格格式保存了数据,则可以从Excel或几乎所有其他电子表格程序中将电子表格保存为CSV文件。在Excel中,您需要导航到File > Save As。在Save as type:字段中,选择CSV (Comma delimited) (*.csv),然后单击“保存”。在其他电子表格软件中,过程应非常相似。
在继续之前,您可能想使用电子表格软件打开CSV文件并查看格式。如果看起来像我们之前看过的代码片段,那么分析将是最简单的:电子表格第一行中的问题,随后每一行中的受访者回答。例如,如果您的数据顶部有一些额外的行,则最好在继续操作之前删除这些行,以使数据集中的第一行是您的调查问题,随后的每一行都是一个受访者的答案。
步骤2:设置您的编码环境
(如果您已经安装了Anaconda并且熟悉Jupyter Notebook,则可以跳过此步骤。)
下一步是设置一个名为Jupyter Notebooks的工具。Jupyter笔记本电脑是一种流行的数据分析工具,因为它们设置迅速且使用非常方便。我们已经编写了深入的Jupyter Notebooks教程,其中有很多详细信息,但是我们将在此处介绍启动和运行所需的内容。
首先,访问Anaconda网站。稍微向下滚动,选择计算机的操作系统,然后单击Download以获取Python 3.7版本。
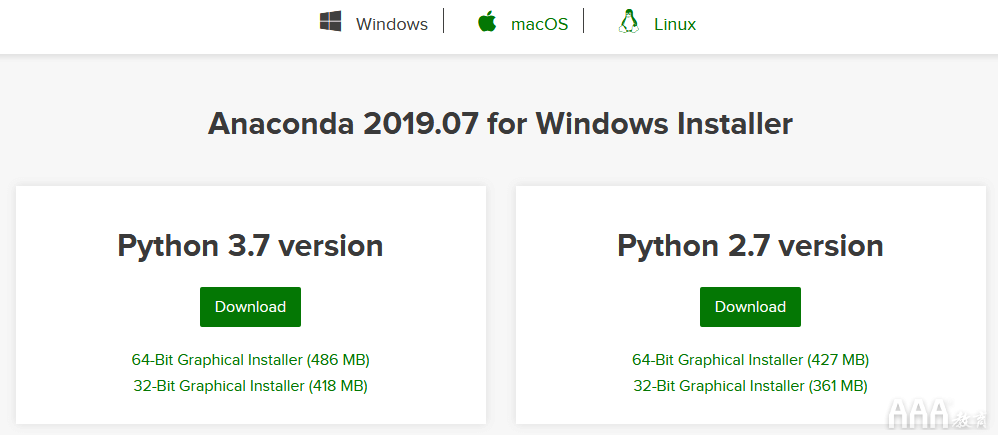
下载文件后,将其打开,然后按照提示在您选择的位置将其安装到计算机上。如果您不确定需要什么,则默认选项会很好。
安装完成后,打开Anaconda Navigator应用程序。您可以在刚安装Anaconda的任何目录中找到此文件,也可以通过在计算机上搜索“ Anaconda”来找到它。应用程序打开时,您可能会看到几个屏幕闪烁,然后您将看到以下内容:

单击该中心选项Jupyter Notebook下的“启动”。这将在您的Web浏览器中打开一个新标签。从那里,单击右上角的“新建”,然后在下拉菜单的“笔记本”下,单击“ Python 3”。
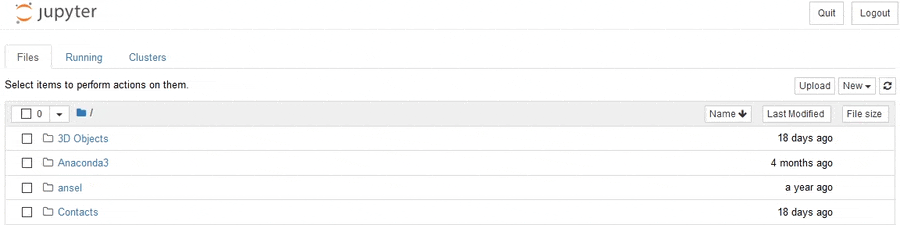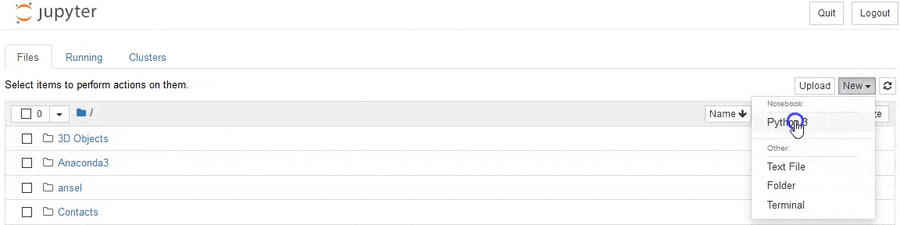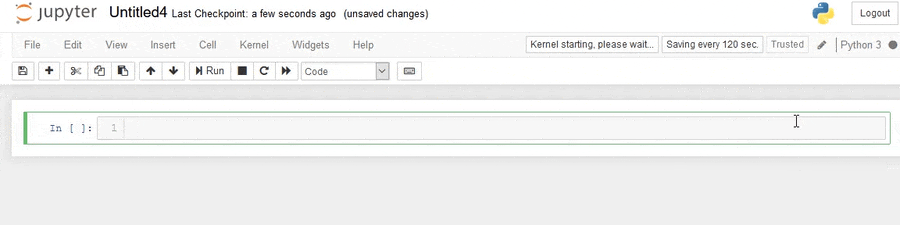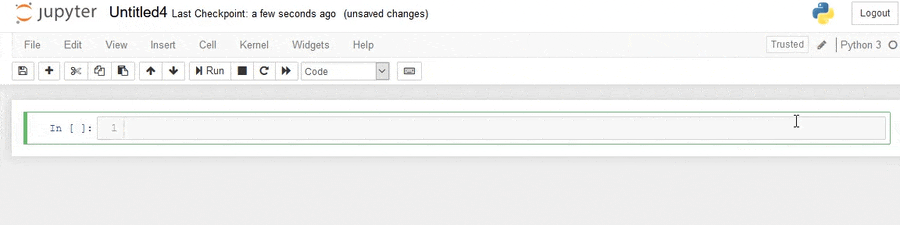
快点!您已经打开了一个新的Jupyter笔记本,我们准备开始编写一些代码!
第3步:将调查数据导入Python
我们编写的前两行代码将使我们能够将数据集放入Python和Jupyter Notebook中,以便我们可以开始使用它。
我们将从导入名为的Python库开始pandas,并对其进行昵称,pd以便我们可以在代码中轻松引用它。为此,我们将使用语法import pandas as pd。此代码告诉Python导入pandas库,然后告诉我们在使用字母时pd,我们希望它引用该pandas库。
Python库有点像浏览器插件。它们添加了额外的功能,因此我们可以使用Python做更多的事情。Pandas是一个非常流行的数据分析库,它将使我们的分析工作更加轻松。
使用“昵称” pd不是强制性的,但这是熊猫用户常见的约定,因此习惯使用它会更容易阅读其他人的代码。
导入熊猫后,我们需要阅读CSV来创建所谓的熊猫DataFrame。DataFrame只是我们可以使用熊猫处理的数据表。稍后,我们将在视觉上看到DataFrame的外观,但是要将数据导入Python和熊猫,我们需要做两件事:
1)阅读我们下载的CSV文件,我们可以使用名为pandas的函数来完成此操作 .read_csv()
2)将CSV数据分配给变量,以便我们可以轻松地引用它
函数是对输入执行操作的代码位。在这种情况下,我们将输入CSV文件的文件名,然后.read_csv()函数将自动为我们将其解析为pandas DataFrame。
您可以将Python中的变量想像成书名。书名使参考书变得容易-我们可以说“杀死一只知更鸟”,人们就会知道我们在说什么,因此我们不必背诵整本书。变量的工作原理类似。它们就像是简短的标题,我们可以用来将更大量的信息(例如我们要分析的调查数据)引荐给Python,而不必重述所有这些信息。
但是,我们确实必须告诉Python我们第一次使用变量时在说什么。我们将变量名称df(DataFrame的缩写)用于调查数据。
因此,我们将用于读取数据集的代码如下所示:df = pd.read_csv('survey_results_public.csv')。这是该代码从左到右告诉Python的内容:
1)df =告诉Python我们正在创建一个名为的新变量df,当您看到时df,请参考以下信息:
2)pd 告诉Python查看我们之前导入的pandas库。
3).read_csv('survey_results_public.csv')告诉Python使用函数.read_csv()读取文件survey_results_public.csv。
请注意,如果CSV文件未与正在使用的Jupyter Notebook存储在同一文件夹中,则需要指定数据集的文件路径。保存时间会有所不同,但是可能看起来像这样:df = pd.read_csv('C://Users/Username/Documents/Filename.csv')。
这就足够了。通过在Jupyter Notebook的第一个单元格中键入以下代码来运行代码,然后单击“ 运行”按钮:

但是等等,什么也没发生!那是因为我们实际上并没有告诉Python给我们任何形式的响应。我们的代码实际起作用了吗?
为了进行检查,让我们使用另一个名为的熊猫方法.head()。这将向我们展示DataFrame的前几行。我们可以通过在括号之间放置一个数字来指定要查看的行数,或者我们可以简单地将其保留不变,它将显示前五行。
不过,我们确实需要告诉.head()我们要看什么DataFrame,因此我们将使用语法df.head()。该df通知的Python我们想看看该数据帧,我们只是用我们的CSV数据所做的.告诉Python我们要做的东西的数据帧,然后head()告诉Python的是什么,我们想做的事:显示前五行。

有我们的DataFrame!看起来很像电子表格,对吧?我们可以看到一些答案看起来被截断了,但是不用担心,数据并没有丢失,只是没有直观地显示出来。
我们可能还会注意到此数据中还有其他一些奇怪的事情,例如NaN在某些行中的外观。稍后我们将对此进行处理,但是首先,让我们使用另一个称为pandas的功能.shape来仔细查看我们的数据集,以赋予我们数据集的大小。

这说明我们的数据集中有88,883行和85列。这些数字应与调查中被调查者(行)和问题(列)的数量完全对应。如果这样做的话,这意味着我们所有的调查数据现在都存储在该DataFrame中,可以进行分析了。
步骤4:分析多项选择调查问题
你如何继续进行分析,从这里真的是你的,并与85题,有吨不同的东西,我们可以用这个数据做。但是,让我们从简单的问题开始:是或否的问题。
(注意:要弄清楚某些列名在StackOverflow数据中的含义可能很困难,但是数据集下载随附一个随附的模式文件,其中包含每个问题的全文,因此您可能需要不时引用它有时间将列名与受访者实际看到的问题进行匹配。)
该调查中比较独特的是或否问题之一是:“您认为今天出生的人的生活会比父母更好吗?”
看到乐观的StackOverflow社区对未来的感觉可能会很有趣!我们可以使用名为的方便的熊猫函数来做到这一点value_counts()。
该value_counts()函数一次查看一列数据,并计算该列包含的每个唯一条目的实例数。(在熊猫语中,单列称为“系列”,因此您可能会将此功能称为Series.value_counts()。)
要使用它,我们需要做的就是告诉Python我们要查看的特定Series(又称专栏),然后告诉它执行.value_counts()。我们可以通过写数据框的名称来指定特定的列,然后在方括号内写该列的名称,如下所示:df['BetterLife']。
(就像我们的列表一样,由于'BetterLife'是字符串而不是数字或变量名,因此我们需要将其放在撇号或引号中,以防止Python引起混淆)。
让我们运行该代码,看看我们得到了什么!
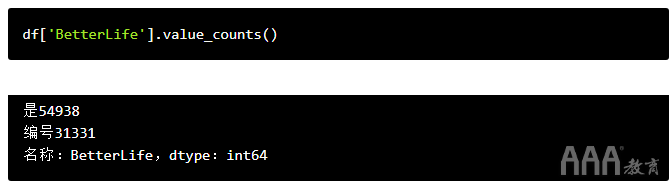
真好!现在我们知道,在我们的数据集中的88883位受访者中,有54938位认为未来前景一片光明。
不过,将其表示为响应总数的百分比可能会更有用。值得庆幸的是,我们可以通过在value_counts()括号内添加一个输入来做到这一点。函数输入在编程中称为自变量,可以使用它们将信息传递给影响其输出内容的函数。
在这种情况下,我们将传递一个看起来像这样的参数:normalize=True。该大熊猫文档大约有一些这方面的细节,但长话短说:value_counts将承担我们希望normalize是False,如果我们不把任何东西里面的功能,因此将返回原始计数为每个值。
但是,如果设置normalize为True,它将通过将它们表示为我们指定的pandas系列中总行数的百分比来“标准化”计数。
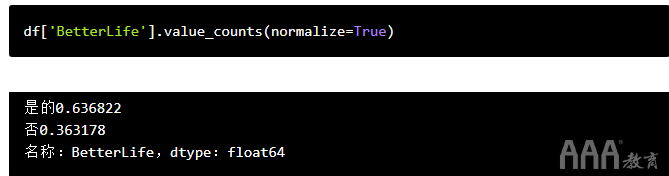
现在我们可以看到大约64%的开发人员认为今天出生的孩子的生活会越来越好,大约36%的开发人员认为今天的孩子生活质量相近或较差。
让我们在另一个有趣的是/否问题上尝试相同的事情:“您是否认为需要成为经理才能赚更多的钱?” 许多硅谷公司声称,管理不是获得财务成功的唯一途径,但开发商是否会购买?
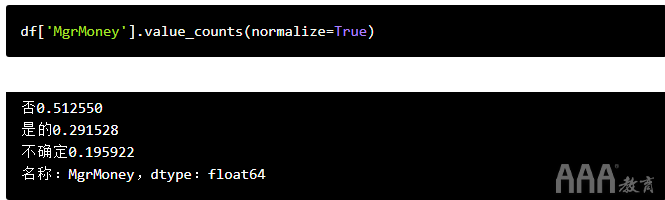
显然,大多数开发人员都没有购买它。实际上,只有不到30%的人相信他们无需进入管理就能赚更多的钱!
我们还可以看到,尽管这是一个是/否问题,但是StackOverflow包含了第三个响应选项(“不确定”),我们的代码仍然以相同的方式工作。value_counts()将适用于任何选择题。
步骤5:绘制多项选择答案
查看数字可能会很有启发性,但人类是视觉生物。幸运的是,对于我们来说,直观地绘制这些问题的答案非常简单!
由于我们是在Jupyter Notebook中编写代码的,因此我们将从Jupyter的魔力开始:

此代码不是我们分析的一部分,它只是一条指令,告诉Jupyter Notebook在我们正在使用的笔记本中内嵌显示图表。
运行完之后,我们所要做的就是在代码末尾添加一个小片段.plot(kind='bar')。这告诉Python接受我们刚刚提供的内容,然后将结果绘制在条形图中。(如果需要,我们可以替换'bar'为'pie'以获得饼图)。
让我们尝试一下有关开发人员偏爱的社交媒体网站的多项选择问题:
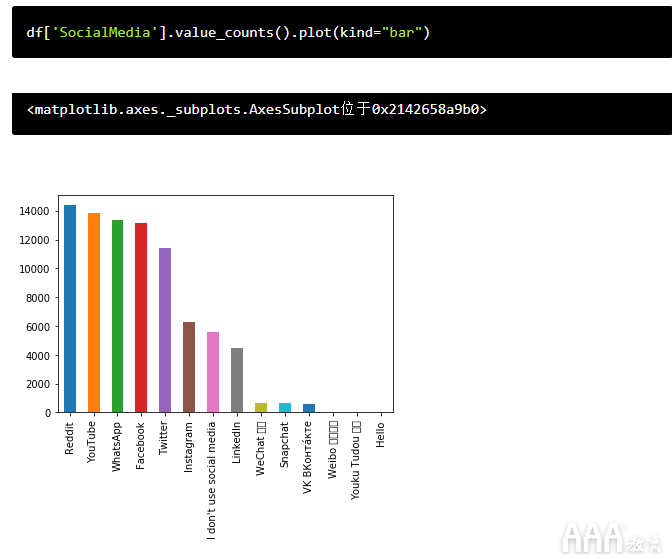
那已经很酷了,但是我们可以通过向该.plot()函数添加更多参数来使它看起来更快。具体来说,让我们添加两个:
a.称为参数的参数figsize,以英寸为单位的宽度和高度定义图表的大小(即(15,7)
b.称为的参数color定义了条形的颜色。
让我们使用Dataquest的绿色#61D199:
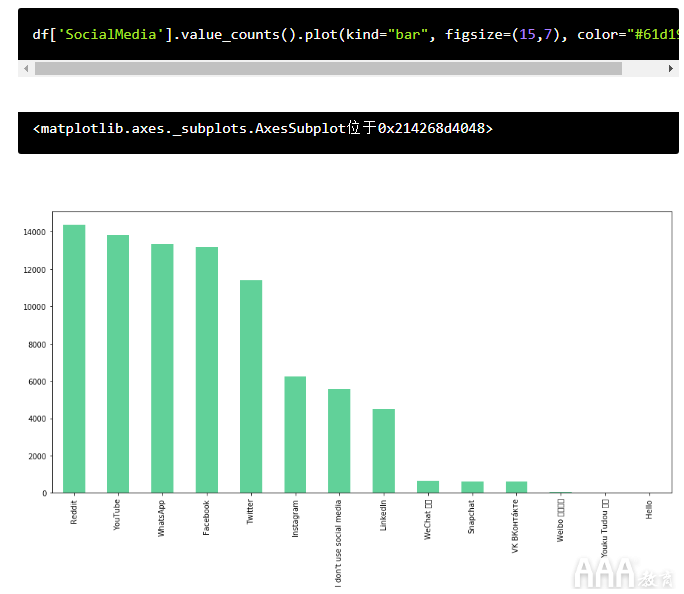
我们可以使用此图表做更多的工作,但是就我们在这里的目的而言,这已经足够了-我们只是在快速可视化之后!
步骤6:分析调查数据的子集
当然,与打印简单的结果计数相比,我们通常会想做得更多!根据我们设置的几乎任何条件,我们可以使用Python和熊猫轻松地选择和分析非常细粒度的数据子集。
例如,我们较早时看到,基于StackOverflow用户对'BetterLife'我们所分析问题的回答,他们占少数,但相当少数的人期望世界变得更糟。例如,与更乐观的开发人员相比,此用户子集可能年龄更大或更年轻吗?
我们可以使用所谓的布尔值对我们的数据进行排序,并仅显示对该问题回答“是”或“否”的人的回答。
我们将通过指定要查看的DataFrame和Series(即列)来创建布尔值,然后使用条件运算符仅过滤该Series中满足特定条件的响应。
这次,让我们先运行代码,然后再仔细看看它在做什么:

为确认此方法是否有效,我们可以使用来检查该数据集的大小.shape,然后said_no使用我们的老朋友将行数与对该问题回答“否”的人数进行比较.value_counts()。
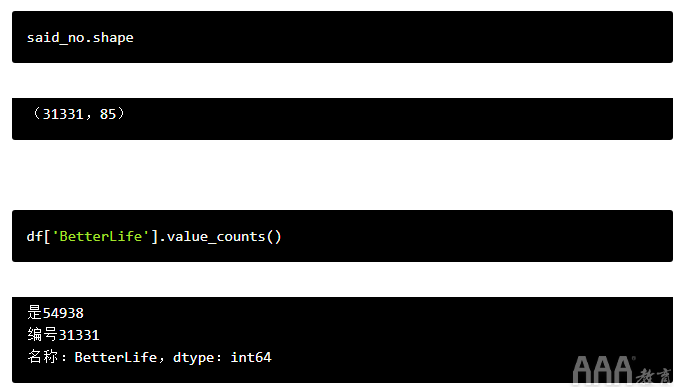
我们可以看到我们的新数据框有31,331行,对更好的生活问题回答“否”的人数相同。我们可以通过value_counts()在此新数据帧上快速运行来进一步确认过滤器是否有效:
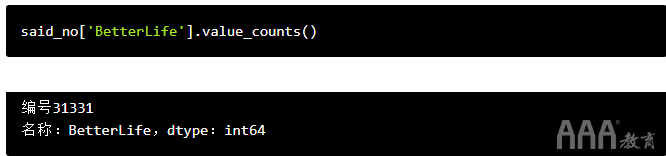
完善。好的,让我们回头看一下这段代码:

这里发生了什么事?从左到右:
1)said_no = 告诉Python创建一个名为said_no的新变量,并使其等于等号右侧的任何内容。
2)df告诉Python使它said_no等效于dfDataFrame(我们的原始数据集),但是……
3)[df['BetterLife'] == 'No']告诉Python 仅包含df其中'BetterLife'列的答案等于的行'No'。
注意这里的双等号。在Python中,当我们要分配值时,即使用单个等号a = 1。我们使用双等号检查等价性,Python实际返回的是True或False。在这种情况下,我们告诉Python来,其中只有返回行df['BetterLife'] == 'No'的回报True。
现在,我们有了一个仅包含“否”答复者的数据框,让我们为“是”人们创建一个等效的答复者,然后进行一些比较。

现在,让我们看看通过将这些群体与人们如何回答有关其年龄的问题进行比较,可以确定什么。该问题的答案是整数,因此我们可以对它们执行数学运算。我们可以进行的一项快速检查是,对更好的生活问题说“是”与“否”的人的平均年龄或中位数年龄是否存在显着差异。
我们将在此代码中使用几个新技巧:.mean()和.median()函数,它们将分别自动计算一列数值数据的平均值和中位数。我们还将把我们的计算结果包含在一个print()命令中,以便同时打印所有四个数字。
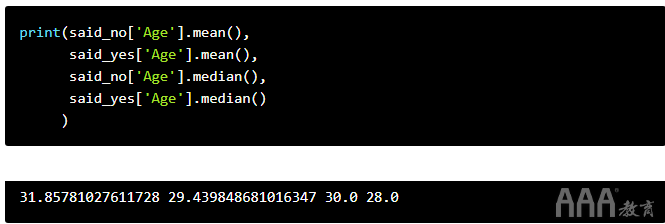
正如我们在这里看到的那样,悲观主义者的年龄往往稍大一些,但幅度不大。看看特定年龄段的人如何回答这个问题以及是否有所不同可能会很有趣。如果悲观主义者倾向于年龄稍大一些,例如,我们是否会看到50岁以上和25岁以下的开发人员的答案之间存在显着差异?
我们可以使用我们一直在使用的布尔运算来找出答案,但是==我们将使用>=,<=因为我们要过滤掉'Age'50岁以上或25岁以下的受访者,而不是使用它来检查条件。
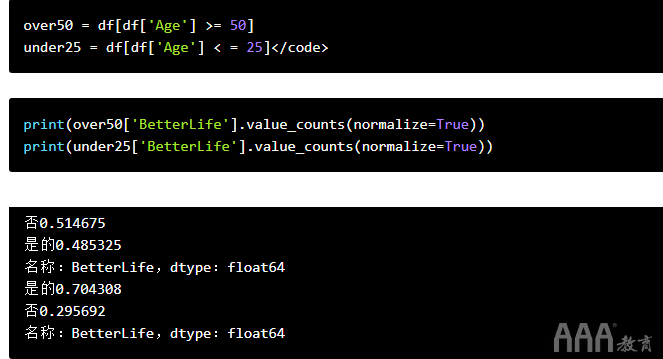
有趣!看起来最老的开发人员确实非常悲观,其中一半以上的人说今天出生的孩子的生活不会比父母更好。另一方面,年轻开发者似乎比平均水平更为乐观。
但是,值得检查一下我们实际上要处理的样本有多大。我们可以使用len()函数快速完成此操作,该函数将计算DataFrame的列表或行中的项目数。

与总数据量相比,这两个组都没有很大,但是两者都足够大,足以代表真正的分裂。
步骤7:过滤更具体的子集
到目前为止,我们一直在一次使用布尔值过滤数据,以查看以特定方式回答特定问题的人员。但是我们实际上可以将布尔值链接在一起,以非常快速地过滤到非常细粒度的级别。
要做到这一点,我们将使用一对大熊猫的布尔运算符,&和&~。
&如我们所料,允许我们将两个布尔值串在一起,并且True仅在两个条件都为真时才返回。因此,在我们的上下文中,如果要通过过滤原始DataFrame中的行来创建新的DataFrame,则&在两个布尔值之间使用将允许我们仅添加同时满足两个条件的行。
我们可以认为&~是“不是”。如果我们&~在两个布尔值之间使用,则仅当第一个布尔值求值为,True而第二个布尔值为时,它才返回一行False。
在语法方面,使用单个布尔值的唯一变化是,当我们将多个布尔值串在一起时,需要将每个布尔值括在括号中,因此基本格式如下所示: df[(Boolean 1) & (Boolean 2)]
让我们通过筛选对更好的生活问题回答“是”并且居住在印度的人们来进行尝试:

我们可以通过快速检查我们筛选出的答案的值计数来确认此功能是否按预期工作:
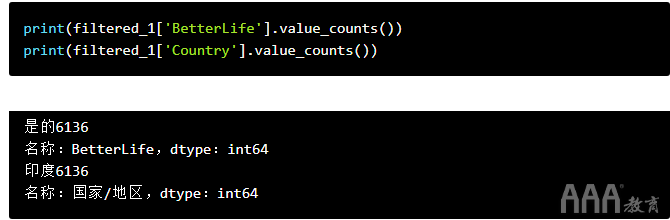
如我们所见,我们的新DataFrame 仅filtered_1包含印度人,他们对未来给出了乐观的答案。
刚才,我们结合了两个布尔值。但是我们可以串在一起的数目没有限制,所以让我们尝试更复杂的下钻。我们将仅过滤以下人员:
a.对美好生活的问题回答“是”
b.超过50岁
c.住在印度
d.不要编码为爱好
e.至少偶尔为开源项目做贡献
开始了:
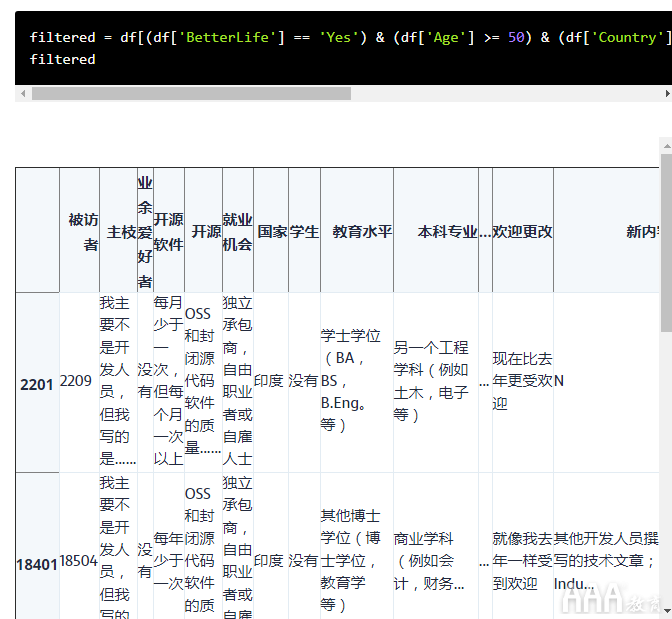
现在,我们开始看到使用编程来分析调查数据的真正力量!从超过了88,000响应的初始数据集,我们找到了一个非常五个人的特定受众!
尝试使用电子表格软件快速筛选出如此特定的受众非常困难,但是在这里,我们仅用一行代码构建并运行了筛选器。
步骤8:分析多答案调查问题
在分析调查数据的背景下,我们可能需要做的另一件事是处理多答案问题。例如,在此调查中,受访者被问及他们使用哪种编程语言,并指示他们选择尽可能多的答案。
不同的调查对这些问题的答案可能会有所不同。有时,每个答案可能在单独的列中,或者所有受访者的答案都可以存储在单个列中,每个答案之间使用某种分隔符。因此,我们的首要任务是查看相关列,以了解在此特定调查中如何记录答案。
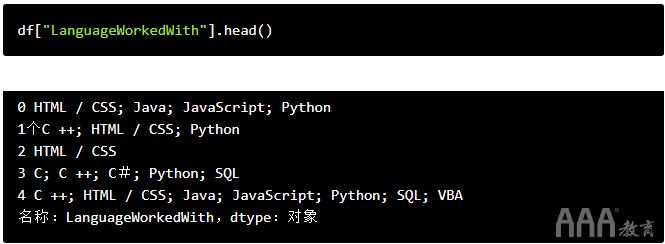
在本次调查中,我们可以看到受访者的答案被存储在一个单独的列中,;用作分隔符。
由于在本教程中我们正在使用Python,因此让我们开始分析调查数据以了解有多少开发人员正在使用Python。
一种方法是查看Python此列中包含该字符串的行数。Pandas有一个内置方法,可通过一系列称为的方法来实现Series.str.contains。这将查看系列中的每一行(在本例中为我们的LanguageWorkedWith列),并确定该行是否包含我们作为参数提供的任何字符串。如果该行确实包含该字符串参数,则将返回True,否则将返回False。
知道了这一点,我们可以快速找出有多少受访者在使用的语言中包含Python。我们将告诉Python我们要查看的系列(df["LanguageWorkedWith"]),然后将str.contains()其与参数一起使用Python。这将给我们一个布尔序列,然后我们要做的就是使用来计数“ True”响应的数量value_counts()。
再一次,我们可以使用该参数normalize=True以百分比形式查看结果,而不是查看原始计数。
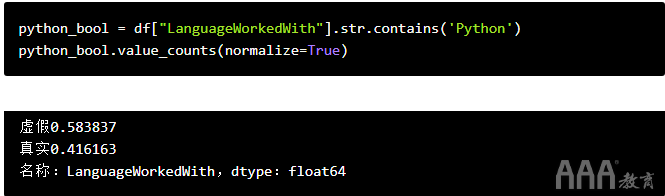
这是获得我们答案的一种快捷方法(几乎所有开发人员中有42%使用Python!)。但是通常,我们可能希望能够细分本专栏中的答案,以进行更深入的分析。
举例来说,我们想弄清楚提及每种语言的频率。要使用上面的代码来完成此操作,我们需要知道每个可能的响应,然后针对每个可能的答案运行类似于以上代码的内容。
在某些情况下,这可能是可行的,但如果有大量潜在答案(例如,如果允许受访者选择“其他”选项并填写自己的选择),则该方法可能不可行。相反,我们需要使用我们之前找到的定界符将每个答案分开。
就像我们Series.str.contains以前看过pandas系列中的字符串是否包含子字符串一样,我们可以Series.string.split基于定界分隔该系列中的每一行,并将其作为参数传递给该函数。在这种情况下,我们知道定界符为;,因此我们可以使用.str.split(';')。
我们也将增加一个额外的参数,expand=True以str.split()。通过将每种语言设置为自己的列(每行仍代表一个受访者),这将从我们的系列中创建一个新的数据框。您可以在此处阅读有关其工作原理的更多信息。
让我们在该'LanguageWorkedWith'列上运行该代码,并将结果存储为名为的新熊猫系列lang_lists。
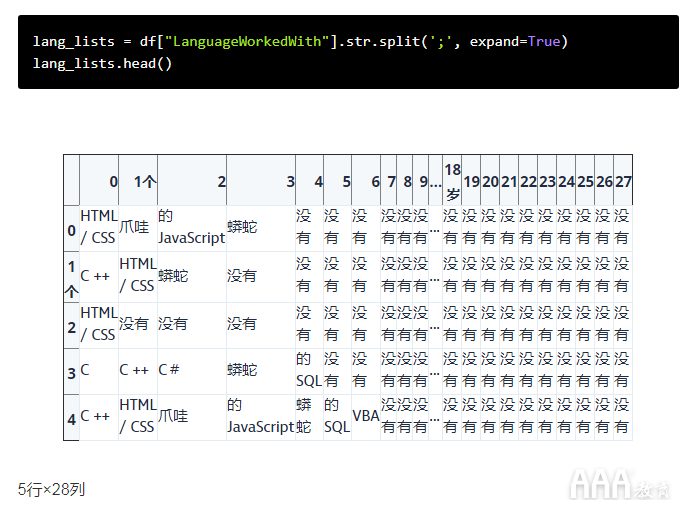
如我们所见,字符串拆分有效。现在,我们系列中的每一行都是新数据框中的一行,并且每种语言都已从其他语言拆分为唯一的列。
但是我们想弄清楚每种语言被提及过多少次,我们还没有完成。value_counts()在这里无济于事-我们只能在pandas系列上使用它,而不能在DataFrame上使用它。
为了能够看到每种语言被提及的总次数,我们需要做更多的工作。我们可以采用多种方法来解决此问题,但这是一种:
a.使用df.stack()堆栈该数据帧,把每个列,然后互相使顶部堆叠它们每一个在数据帧的数据点出现在一个单一的熊猫系列。
b.value_counts()在这个新的“堆叠式”系列上 使用,可以得出提到每种语言的总次数。
这有点复杂,所以让我们先用一个简单的示例进行尝试,以便我们可以直观地观察正在发生的事情。我们将从与十分相似的DataFame开始lang_lists,但它要短得多,以便更容易理解。
这是我们的DataFrame(由于这不是我们真实数据集的一部分,因此您可能不想尝试与此代码一起编写代码,只需阅读此页上的代码并尝试了解正在发生的事情):
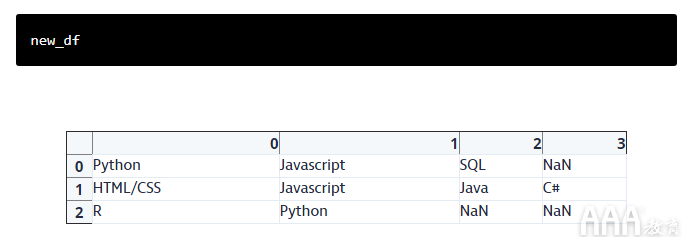
首先,我们将使用.stack()该数据帧进行分割,然后将各列彼此堆叠。请注意,发生这种情况时,将自动删除插入到上述数据框中的空值。

这是发生的事情的动画视图:

现在,我们已经将每个答案堆叠到一个系列中,可以value_counts()用来计算总数:
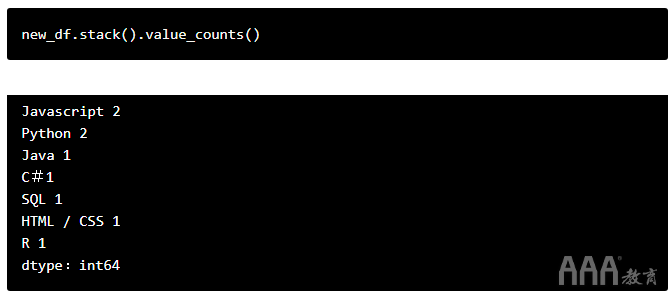
那就是我们需要的原始计数!请注意,normalize=True此处无法使用基于百分比的读数,因为该计算基于序列的长度,该序列有9行,而我们的原始数据集只有3个响应。
现在,我们知道如何执行此操作,让我们使用已经创建的系列在真实数据集上尝试相同的操作lang_lists。
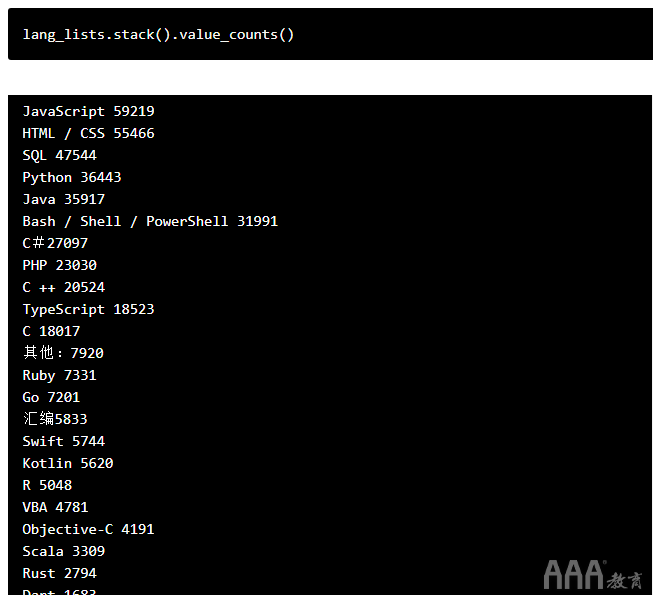
这就是我们正在寻找的信息!现在,让我们通过使用与之前使用的相同绘图方法直观地绘制此信息的图表,最后对我们的分析项目进行润色。
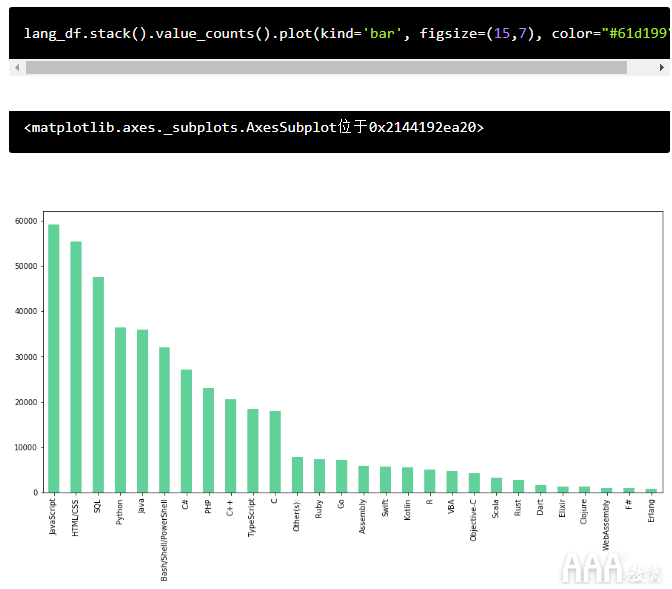
分析调查数据:后续步骤
在本教程中,我们介绍了一些使用Python分析调查数据的基本方法。尽管阅读了很长时间,但如果回头看,您会发现我们实际上只使用了几行代码。一旦掌握了这些要点,进行这种分析实际上非常快!
当然,我们只是在这里刮了一下表面。您还可以做更多的事情,尤其是对于如此庞大的数据集。如果您正在寻找挑战,可以尝试回答以下问题。
a.如果您根据以上数据计算出的百分比除以调查受访者总数(88,883),您会发现它们与StackOverflow报告的数字并不完全相同。这是因为少数受访者没有回答语言问题。您如何找到并计算这些受访者,以找到列出每种语言的受访者的确切百分比?
b.上面的结果为我们提供了在所有接受调查的开发人员中使用最流行的语言,但是此调查的另一个问题确定了不同类型的角色,包括数据科学家,数据分析师等。您是否可以创建一个图表来显示最受欢迎的语言数据专业人员之间?
填写下面表单即可预约申请免费试听!怕钱不够?可先就业挣钱后再付学费! 怕学不会?助教全程陪读,随时解惑!担心就业?一地学习,可推荐就业!
©2007-2022/ www.aaa-cg.com.cn 北京漫动者数字科技有限公司 备案号: 京ICP备12034770号 监督电话:010-53672995 邮箱:bjaaa@aaaedu.cc

 热门推荐
热门推荐
 UI设计
UI设计
 产品经理
产品经理
 大数据分析
大数据分析
 原画设计
原画设计
 平面设计
平面设计
 新媒体运营
新媒体运营 






