列表是大数据分析Python中最强大的数据类型之一。在此大数据分析Python列表教程中,您将学习如何在分析有关移动应用程序的数据时使用列表。
在大数据分析Python列表使用教程中,我们假设您了解大数据分析Python的基本知识,包括使用字符串,整数和浮点数。如果您不熟悉这些内容,则可以尝试免费的大数据分析Python基础知识课程。
我们将使用来自移动应用商店数据集(Ramanathan Perumal)的以下数据表:
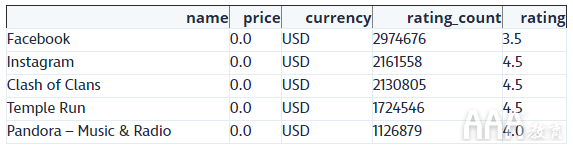
表中的每个值都是一个数据点。例如,第一行(列标题之后)具有五个数据点:
1)Facebook
2)0.0
3)USD
4)2974676
5)3.5
数据点的集合构成一个数据集。我们可以将上面的整个表理解为数据点的集合,因此我们将整个表称为数据集。我们可以看到我们的数据集有五行五列。
使用对大数据分析Python类型的理解,我们可能认为我们可以将每个数据点存储在其自己的变量中-例如,这就是我们可以存储第一行的数据点的方式:
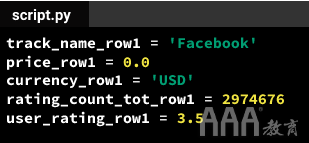
上面,我们存储了:
1)文字“ Facebook”作为字符串
2)价格为0.0的浮动
3)文本“ USD”作为字符串
4)评分计数2,974,676作为整数
5)用户评级3.5为浮动
为数据集中的每个数据点创建变量将是一个繁琐的过程。幸运的是,我们可以使用list更有效地存储数据。这是我们可以为第一行创建数据点列表的方式:
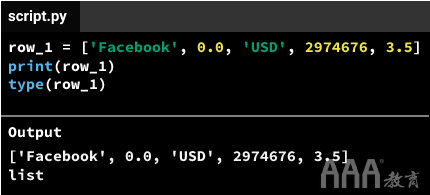
要创建上面的列表,我们:
1)输入一系列数据点,并用逗号分隔每个数据点: 'Facebook', 0.0, 'USD', 2974676, 3.5
2)用括号将序列括起来: ['Facebook', 0.0, 'USD', 2974676, 3.5]
创建列表后,通过将其分配给名为的变量,将其存储在计算机的内存中row_1。
要创建数据点列表,我们只需要:
1)用逗号分隔数据点。
2)用括号将数据点的序列括起来。
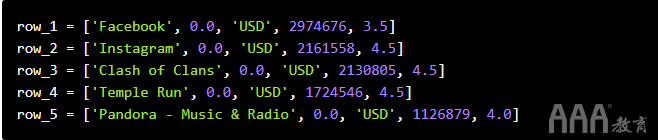
现在,我们创建五个列表,数据集中的每一行一个:
索引大数据分析Python列表
列表可以包含各种数据类型。类似的列表[4, 5, 6]具有相同的数据类型(仅整数),而列表['Facebook', 0.0, 'USD', 2974676, 3.5]具有混合的数据类型:
1)两串('Facebook', 'USD')
2)两个浮点(0.0,3.5)
3)一整数(2974676)
该['Facebook', 0.0, 'USD', 2974676, 3.5]列表有五个数据点。要查找列表的长度,我们可以使用以下len()命令:
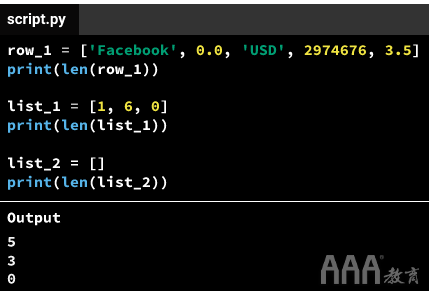
对于小列表,我们只需在屏幕上计数数据点即可找到长度,但是len()当您使用包含许多元素的列表,或者需要为不知道长度的数据编写代码时,该命令将非常有用提前时间。
列表中的每个元素(数据点)都有一个与之关联的特定编号,称为索引编号。索引始终从0开始,因此第一个元素的索引号为0,第二个元素的索引号为1,依此类推。
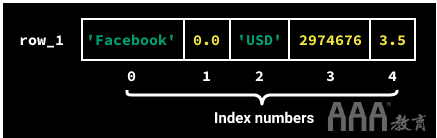
若要快速找到列表元素的索引,请确定其在列表中的位置编号,然后减去1。例如,字符串'USD'是列表的第三个元素(位置编号3),因此其索引编号必须为2,因为3 – 1 = 2。
索引号帮助我们从列表中检索单个元素。回顾row_1上面的代码示例中的列表,我们可以'Facebook'通过运行代码来检索索引编号为0 的第一个元素(字符串)row_1[0]。
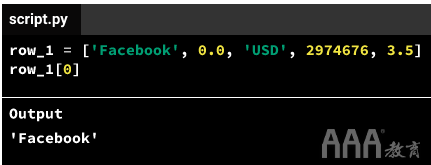
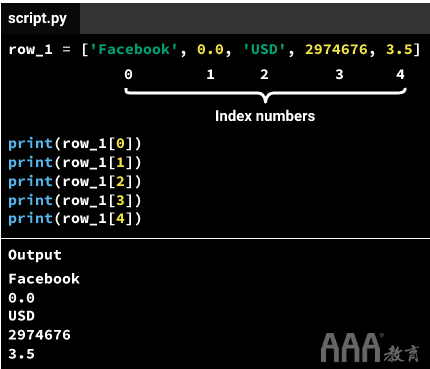
检索单个列表元素的语法遵循该模型list_name[index_number]。例如,上面的列表的名称为row_1,第一个元素的索引号为0-在list_name[index_number]模型之后,我们得到row_1[0],其中索引号0在变量name后面的方括号中row_1。

这是我们如何检索中的每个元素row_1:
检索列表元素使执行操作更加容易。例如,我们可以选择Facebook和Instagram的评分,并找到平均值或两者之间的差异:
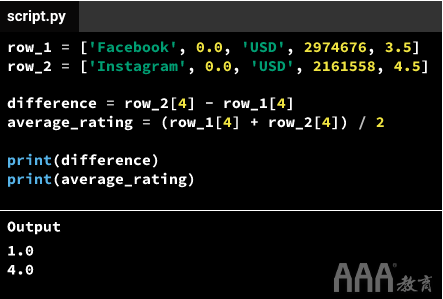
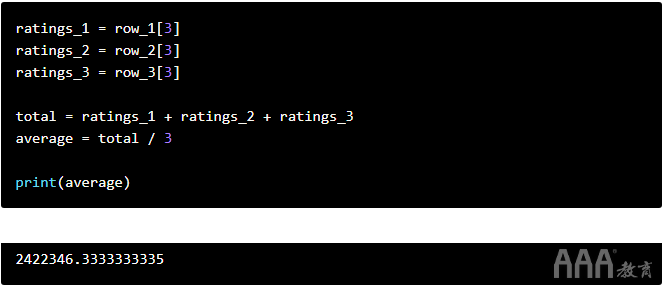
让我们使用列表索引从前三行中提取评分数量,然后取平均值:
对列表使用负索引
在大数据分析Python中,我们有两个列表索引系统:
1)正索引:_first)元素的索引号为0,第二个元素的索引号为1,依此类推。
2)负索引:最后一个元素的索引号为-1,倒数第二个元素的索引号为-2,依此类推。
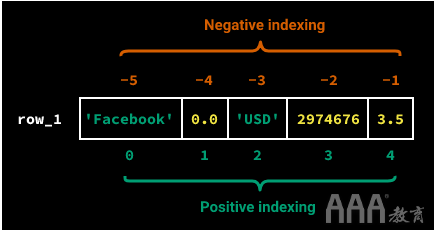
实际上,我们几乎总是使用正索引来检索列表元素。当我们要选择列表的最后一个元素时,负索引很有用-特别是如果列表很长,并且我们无法通过计数来判断长度。
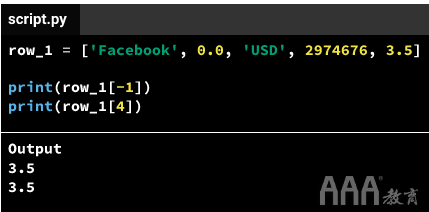
请注意,如果我们使用的索引号不在两个索引系统的范围内,则会得到一个IndexError。
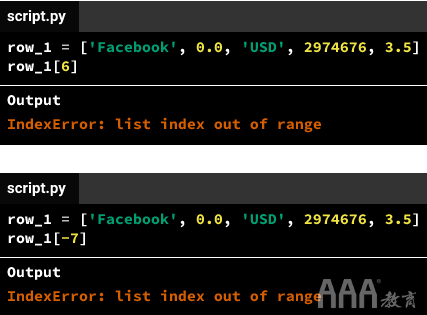
让我们使用负索引从前三行中的每行中提取用户评分(最后一个值),然后取平均值。
切片大数据分析Python列表
代替单独选择列表元素,我们可以使用语法快捷方式来选择两个或更多连续元素:
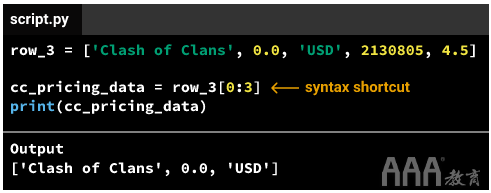
当我们从一个名为list的列表中选择第一个n元素(n代表一个数字)时a_list,可以使用语法快捷方式a_list[0:n]。在上面的示例中,我们需要从列表中选择前三个元素row_3,因此我们使用row_3[0:3]。
当选择前三个元素时,我们将列表的一部分切成薄片。因此,选择列表的一部分的过程称为列表切片。
我们可能想采用多种方式对列表进行切片:
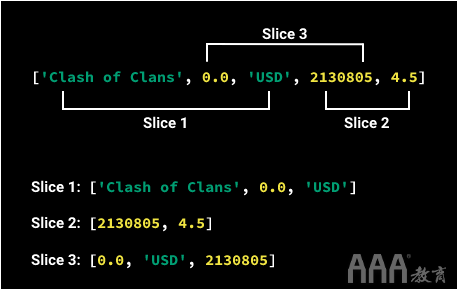
要检索我们想要的任何列表切片:
a)我们首先需要确定切片的第一个和最后一个元素。
b)然后,我们需要确定切片的第一个和最后一个元素的索引号。
c)最后,我们可以使用语法检索所需的列表切片a_list[m:n],其中:
1)m表示切片的第一个元素的索引号;和
2)n表示切片的最后一个元素的索引号加上一个(如果最后一个元素的索引号为2,则我们n将为3,如果最后一个元素的索引号为4,n则将为5,依此类推)。

当我们需要选择第一个或最后一个x元素(x代表一个数字)时,我们可以使用更简单的语法快捷方式:
1)a_list[:x]当我们要选择第一个x元素时。
2)a_list[-x:]当我们要选择最后一个x元素时。
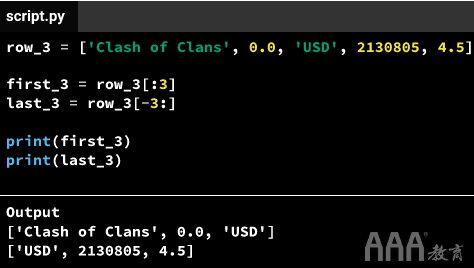
让我们看看如何从第一行中提取前四个元素(以及有关Facebook的数据):
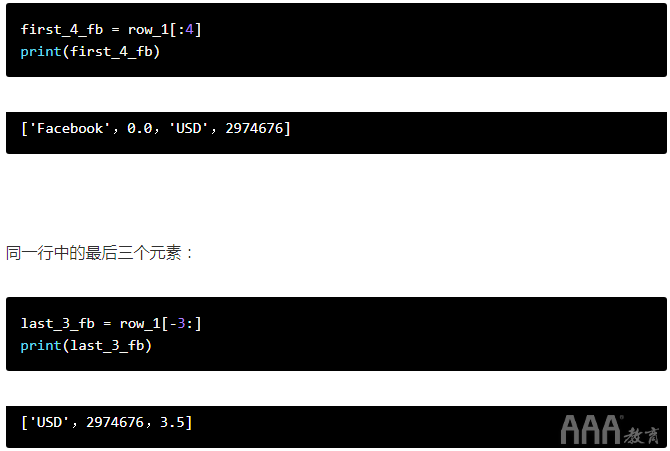
以及第五行中的元素3和4(以及有关Pandora的数据):

大数据分析Python列表列表
之前,我们介绍了列表,它是每个数据点使用一个变量的更好选择。'Facebook', 0.0, 'USD', 2974676, 3.5我们可以将五个数据点捆绑在一起,而不是为五个数据点分别设置一个变量,然后将列表存储在一个变量中。
到目前为止,我们一直与具有五个行的数据集,我们已经存储在单独的变量每行作为一个列表(变量row_1,row_2,row_3,row_4,和row_5)。但是,如果我们的数据集包含5,000行,那么最终将得到5,000个变量,这将使我们的代码混乱,几乎无法使用。
为了解决这个问题,我们可以将五个变量存储在一个列表中:
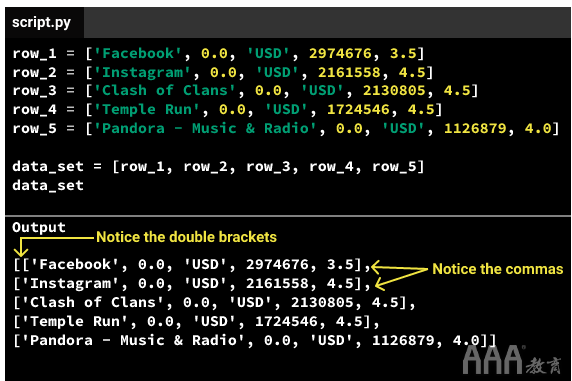
正如我们所看到的,data_set是一个列表,记录了其它五个列表(row_1,row_2,row_3,row_4,和row_5)。包含其他列表的列表称为列表列表。
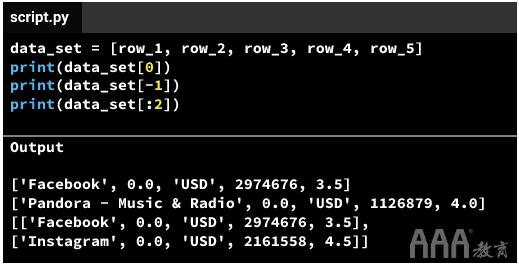
该data_set变量仍然是一个列表,这意味着我们可以检索单个列表元素并使用我们学到的语法执行列表切片。在下面,我们:
a.使用检索第一个列表元素(row_1)data_set[0]。
b.使用检索最后一个列表元素(row_5)data_set[-1]。
c.通过使用进行列表切片, 检索前两个列表元素(row_1和row_2)data_set[:2]。
我们会经常需要检索这是一个列表的列表的一部分列表各个元素-例如,我们可能要检索的值3.5从['Facebook', 0.0, 'USD', 2974676, 3.5],这是一部分data_set名单列表。下面,我们3.5从data_set使用中学到的内容中进行摘录:
a.我们row_1使用进行检索data_set[0],并将结果分配给名为的变量fb_row。
b.我们打印fb_row,输出['Facebook', 0.0, 'USD', 2974676, 3.5]。
c.我们检索的最后一个元素fb_row使用fb_row[-1](因为fb_row是一个列表),并将结果分配给指定的变量fb_rating。
d.打印fb_rating,输出3.5
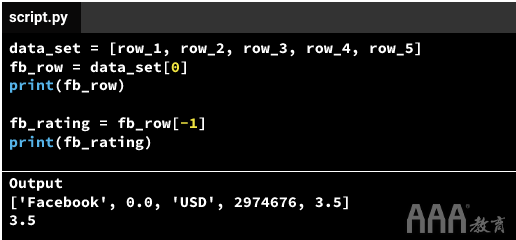
上面,我们3.5分两步进行检索:首先检索data_set[0],然后检索fb_row[-1]。但是,3.5通过链接两个索引([0]和[-1]),有一种更简单的方法来检索相同的值-代码将data_set[0][-1]检索3.5:
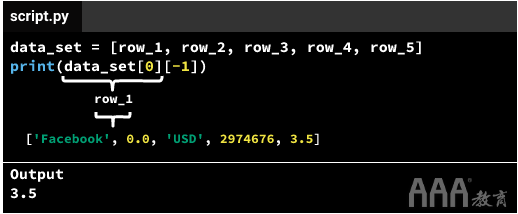
上面,我们已经看到了两种获取值的方法3.5。两种方法都导致相同的输出(3.5),但是第二种方法涉及较少的键入操作,因为它很好地结合了我们在第一种情况下看到的步骤。虽然您可以选择任一选项,但人们通常会选择第二个选项。
让我们将五个单独的列表转换为列表列表:
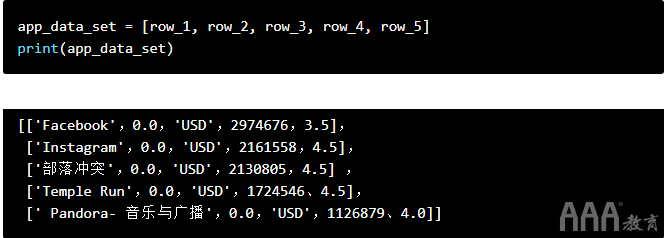
重复清单程序
在执行此任务之前,我们对计算应用程序的平均评分感兴趣。当我们只处理三行时,这是一个可行的任务,但是添加的行越多,它变得越难。使用之前的策略,我们将:
a.检索每个单独的评分。
b.总结一下评分。
c.除以评分数。
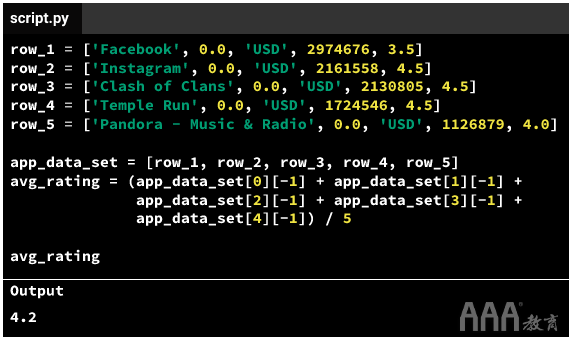
如您所见,五个等级会使情况变得复杂。如果我们正在处理包含1,000行的数据,则将需要不切实际的代码量!我们需要找到一种简单的方法来检索许多评级。
查看上面的代码示例,我们看到一个过程不断重复:我们为中的每个列表选择了最后一个列表元素app_data_set。该app_data_set卖场五名名单,所以我们重复相同的过程五次。如果我们可以直接告诉大数据分析Python我们要为其中的每个列表重复该过程app_data_set怎么办?
幸运的是,我们可以做到这一点-大数据分析Python为我们提供了一种简单的方法来重复一个过程,当我们需要重复数百,数千甚至数百万次过程时,这可以极大地帮助我们。
比方说,我们有一个列表[3, 5, 1, 2]分配给一个变量ratings,我们想重复以下过程:对每个元素在 ratings,打印元素。这就是我们可以将其转换为大数据分析Python语法的方式:
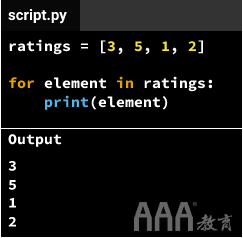
在我们上面的第一个例子,我们想重复这个过程是_”提取的最后一个元素为每个列表中的 app_data_set “_。这是我们可以将该过程转换为大数据分析Python语法的方式:
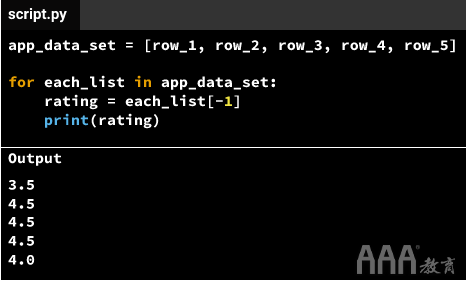
让我们尝试更好地了解上述情况。大数据分析Python一次将一个列表元素从中分离出来app_data_set,然后将其分配给each_list(基本上成为一个存储列表的变量-我们将在下一个屏幕上进一步讨论):
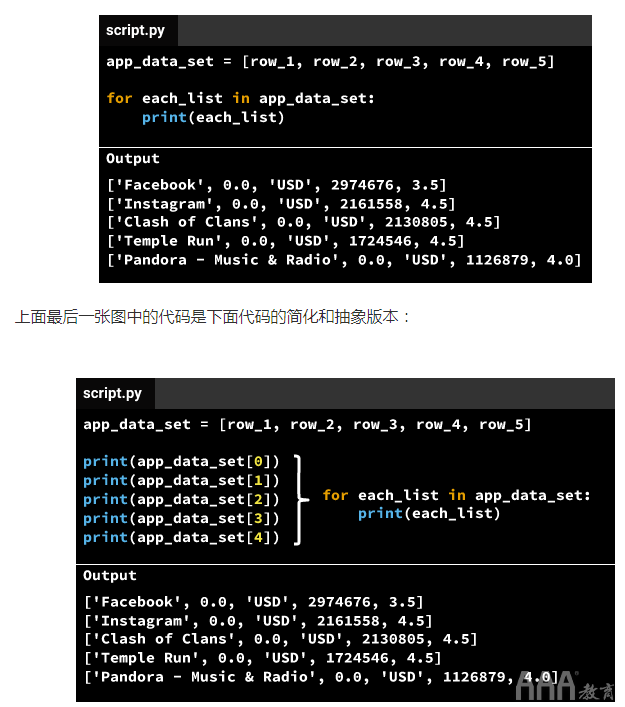
使用上述技术需要我们为数据集中的每一行编写一行代码。但是使用该for each_list in app_data_set技术只需要我们写两行代码,而不管数据集中的行数是多少—数据集可以有五行或一百万。
我们的中间目标是使用这项新技术来计算上述五行的平均评分,而最终目标是计算包含7,197行的数据集的平均评分。我们将在此任务的接下来的几个屏幕中执行此操作,但现在,我们将集中精力练习此技术以更好地掌握它。
在编写任何代码之前,我们需要缩进我们要在右边重复四个空格字符的代码:

从技术上讲,我们只需要在代码的右边至少缩进一个空格字符,但是大数据分析Python社区中的约定是使用四个空格字符。这有助于提高可读性-遵循此约定的其他人将更容易阅读您的代码,并且您将更容易阅读他们的代码。
让我们使用这种技术来打印每个应用程序的名称和等级:
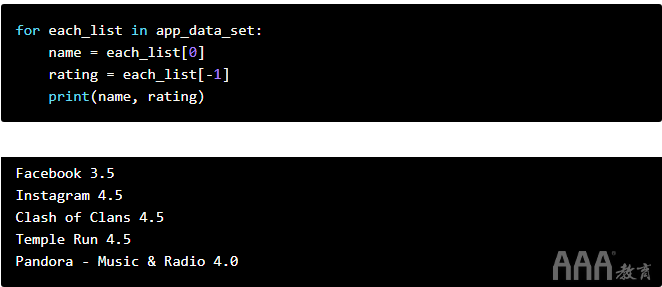
大数据分析Python中的列表和For循环
我们刚刚学到的技术称为循环。循环是一个非常有用的工具,可用于使用大数据分析Python列表执行重复过程。因为我们总是以for(像in for some_variable in some_list:)开始,所以这种技术被称为for循环。
这些是for循环的结构部分
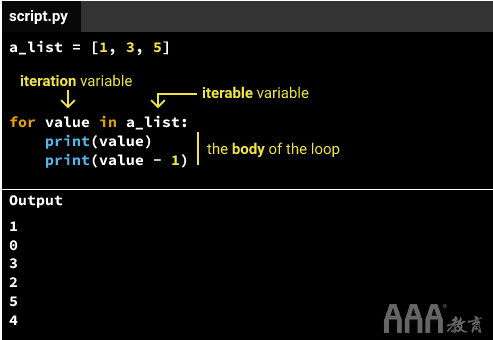
主体中 的缩进代码
a.对于第一次迭代,该值是iterable的第一个元素(来自上面的示例1)。
b.对于第二次迭代,该值是iterable的第二个元素(来自上面的示例3)。
c.对于第三次迭代,该值是iterable的第三个元素(来自上面的示例5)。
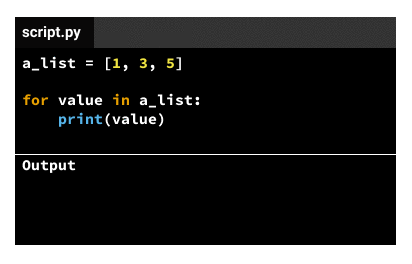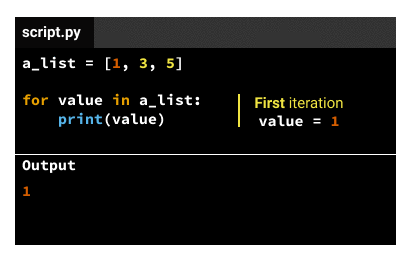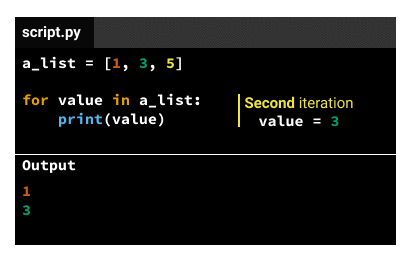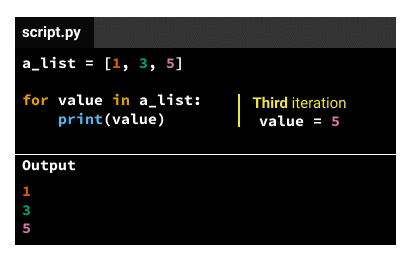
插入变量的名称可以是您喜欢的任何名称–如果value在上面dog的代码中将替换为,则代码将以完全相同的方式工作。也就是说,习惯上使用有助于传达数据含义的东西。
循环主体之外的 代码可以与代码交互
a.初始化变量 a_sum
b.我们循环(或迭代a_list
1)在迭代变量的当前值和存储在其中的当前值之间执行加法运算(在循环体内)valuea_suma_sum
2)将加法结果分配回 a_sum
3)打印a_sum变量的值(在循环体内)。请注意,a_sum每次添加后更改的值。在循环结束时,a_sum具有值9,该值等于a_list(1 + 3 + 5)中数字的总和。
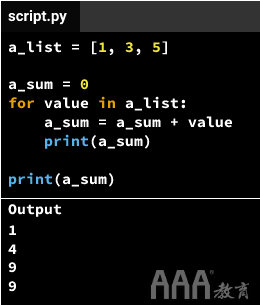
上面,我们创建了一种汇总列表中数字的方法。我们可以使用这种技术总结数据集中的评分。一旦有了总和,我们只需要除以等级数即可得出平均值。
我们在这里介绍了for循环的基础知识,但是如果您想进行更多练习,我们还提供了有关for循环基础知识和高级for循环的教程,您可以检阅。
计算列表平均值的另一种方法
现在,我们将学习计算平均评级值的另一种方法。创建列表后,可以使用命令向其中添加(或追加)值append()。
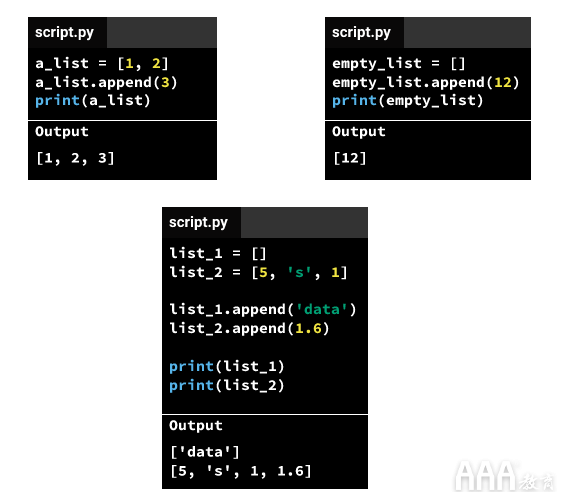
与我们学过的其他命令不同,请注意 append()list_name.append()append()
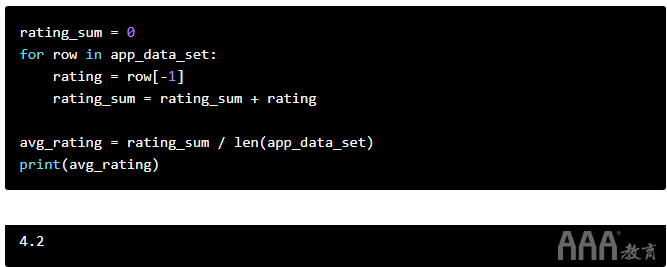
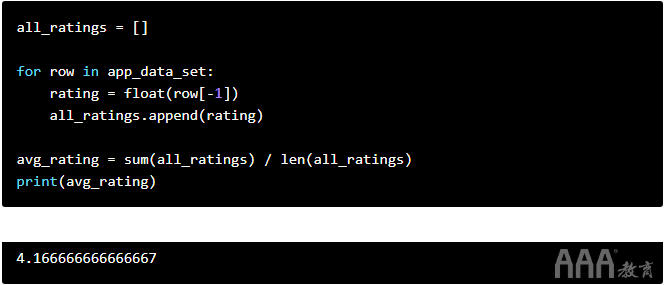
现在我们知道如何将值添加到列表中,我们可以按照以下步骤计算平均应用评分:
a.我们初始化一个空列表。
b.我们开始遍历数据集并提取
c.我们追加
d.获得所有等级后,我们:
1)使用该sum()命令汇总所有评分(以便能够使用sum()
2)我们将总和除以评分数(可以使用len()命令获得评分)。
在下面,我们可以看到为五行数据集实施的上述步骤:
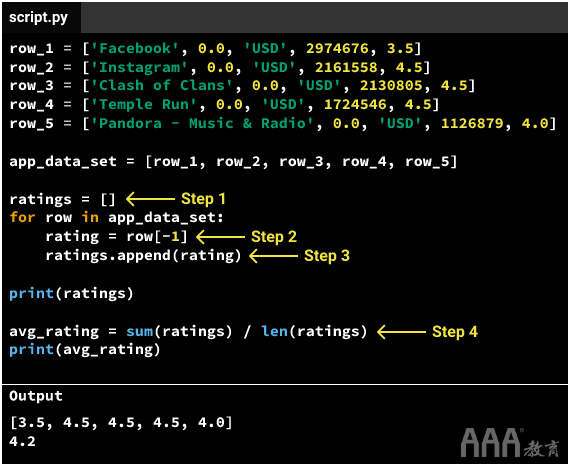
我们还可以append()通过将数据追加为列表来将另一行添加到列表中。让我们看看它是如何工作的:
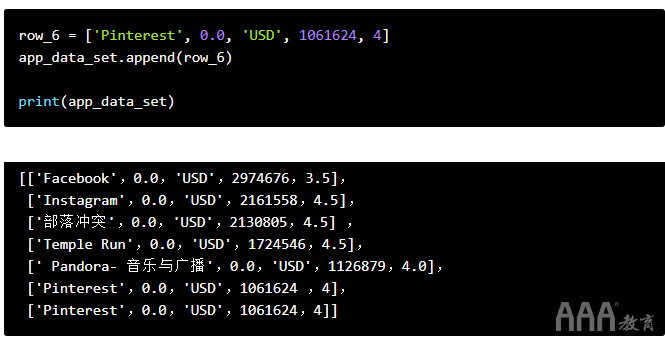
现在,让我们使用上面学到的技术来计算所有六个应用程序的平均评分:
下一步
在大数据分析Python列表使用教程中,我们学习了如何:
a.使用大数据分析Python列表存储和处理数据
b.使用正索引和负索引访问存储在列表中的值
c.使用列表列表来处理表格数据
d.用于循环自动执行重复性任务
e.将值附加到列表
如果您想练习使用大数据分析Python列表,那么大数据分析Python列表使用教程是基于我们的免费大数据分析Python基础课程的一部分。该课程可以从您的Web浏览器上进行,您将编写代码来分析7,000多个移动应用程序的完整数据集!
填写下面表单即可预约申请免费试听!怕钱不够?可先就业挣钱后再付学费! 怕学不会?助教全程陪读,随时解惑!担心就业?一地学习,可推荐就业!
©2007-2022/ www.aaa-cg.com.cn 北京漫动者数字科技有限公司 备案号: 京ICP备12034770号 监督电话:010-53672995 邮箱:bjaaa@aaaedu.cc

 热门推荐
热门推荐
 UI设计
UI设计
 产品经理
产品经理
 大数据分析
大数据分析
 原画设计
原画设计
 平面设计
平面设计
 新媒体运营
新媒体运营 






