数据清理和准备是任何机器学习项目中至关重要的第一步。尽管我们经常认为数据科学家花费大量时间来修改算法和机器学习模型,但现实情况是大多数数据科学家花费大量时间来清理数据。
在大数据分析机器学习的数据清理和准备中,我们将逐步介绍使用Python进行数据清理,检查数据集,选择特征列,以可视方式探索数据然后进行编码的过程机器学习的功能。
要了解有关数据清理的更多信息,请查看我们的交互式数据清理课程之一:
1、数据清理和分析课程(Python)
2、高级数据清理课程(Python)
3、数据清理(R)
了解数据
在我们开始为机器学习项目清理数据之前,至关重要的是要了解数据是什么,以及我们想要实现什么。没有这种了解,我们就没有依据来决定在清理和准备数据时要确定哪些数据是相关的。
我们将使用个人贷款的一些数据,个人贷款是一个个人贷款市场,它将正在寻求贷款的借款人与希望借钱并获得回报的投资者进行匹配。每个借款人都填写一份全面的申请表,提供他们过去的财务记录,贷款原因等。个人贷款使用过去的历史数据(以及他们自己的数据科学过程!)来评估每个借款人的信用评分,并为借款人分配一个利率。
批准的贷款在个人贷款网站上列出,合格的投资者可以在其中浏览最近批准的贷款,借款人的信用评分,贷款目的以及应用程序中的其他信息。
一旦投资者决定为贷款提供资金,借款人便每月向个人贷款偿还款项。个人贷款将这些付款重新分配给投资者。这意味着投资者不必等到全额还清就可以开始看到回报。如果按时还清了贷款,则投资者将获得与借款人除要求的金额外还需支付的利率相对应的回报。
但是,许多贷款没有按时还清,有些借款人拖欠贷款。这就是我们在清理个人贷款的一些数据进行机器学习时将尝试解决的问题。让我们想象一下,我们的任务是建立一个模型来预测借款人是否可能偿还或拖欠其贷款。
步骤1:检查数据集
个人贷款会在其网站上定期发布其所有已批准和已拒绝贷款申请的数据。为了确保我们都使用相同的数据集,我们已经在data.world上镜像了将用于本教程的数据。
在个人贷款类的网站上,您可以选择不同的年份范围来下载已批准和已拒绝贷款的数据集(CSV格式)。您还将在个人贷款类页面底部找到一个数据字典(XLS格式),其中包含有关不同列名的信息。该数据字典对于理解数据集中每一列表示什么很有用。数据字典包含两页:
1)LoanStats工作表:描述批准的贷款数据集
2)RejectStats工作表:描述拒绝的贷款数据集
由于我们对批准的贷款数据集感兴趣,因此我们将使用LoanStats工作表。
批准的贷款数据集包含有关当前贷款,已完成贷款和拖欠贷款的信息。在本教程中,我们将使用2007年至2011年的批准贷款数据,但是对于发布到个人贷款类网站上的任何数据,都将需要类似的清理步骤。
首先,让我们导入一些我们将要使用的库,并设置一些参数以使输出更易于阅读。就本教程而言,我们将扎实地掌握使用Python处理数据的基础知识,包括使用pandas,numpy等,因此,如果您需要掌握其中的任何技能,则可能需要浏览我们的课程清单。
将数据加载到熊猫
我们已经下载了数据集并命名为lending_club_loans.csv,但是现在我们需要将其加载到pandas DataFrame中以进行探索。加载完毕后,我们将需要执行一些基本的清理任务来删除一些不需要的信息,这些信息会使我们的数据处理速度变慢。
具体来说,我们将要:
1)删除第一行:它包含多余的文本,而不是列标题。此文本可防止熊猫库正确解析数据集。
2)删除“ desc”列:其中包含我们不需要的长文字说明。
3)删除“ URL”列:它包含指向个人贷款上每个链接的链接,只能使用投资者帐户进行访问。
4)删除所有缺失值超过50%的列:这将使我们能够更快地工作(并且我们的数据集足够大,如果没有它们,它将仍然有意义。
我们还将命名过滤后的数据集loans_2007,并在本节末尾将其保存为loans_2007.csv与原始数据分开的名称。这是一种很好的做法,可以确保我们拥有原始数据,以防万一需要返回并检索要删除的所有内容。
现在,让我们继续执行以下步骤:

让我们使用pandas head()方法显示loan_2007 DataFrame的前三行,以确保我们能够正确加载数据集:


让我们还使用pandas .shape属性来查看我们现阶段要处理的样本和功能的数量:

步骤2:缩小色谱柱进行清洁
现在我们已经建立了数据,我们应该花一些时间来探索它,并理解每一列代表什么功能。这很重要,因为对功能的了解不足可能会导致我们在数据分析和建模过程中出错。
我们将使用个人贷款类提供的数据字典来帮助我们熟悉列以及每个列在数据集中的表示。为了简化该过程,我们将创建一个DataFrame来包含列的名称,数据类型,第一行的值以及数据字典中的描述。为了简化操作,我们已经将数据字典从Excel格式预先转换为CSV。
让我们加载该字典并看看。
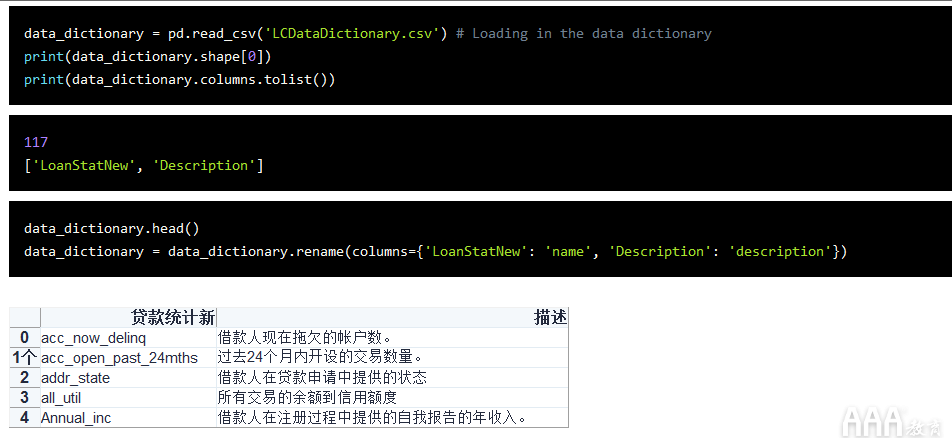
现在已经加载了数据字典,让我们loans_2007将data_dictionaryDataFrame 的第一行连接起来,为我们提供带以下几列的预览DataFrame:
1)name—包含的列名loans_2007。
2)dtypes—包含loans_2007列的数据类型。
3)first value—包含loans_2007第一行的值。
4)description—解释其中的每一列所loans_2007代表的含义。
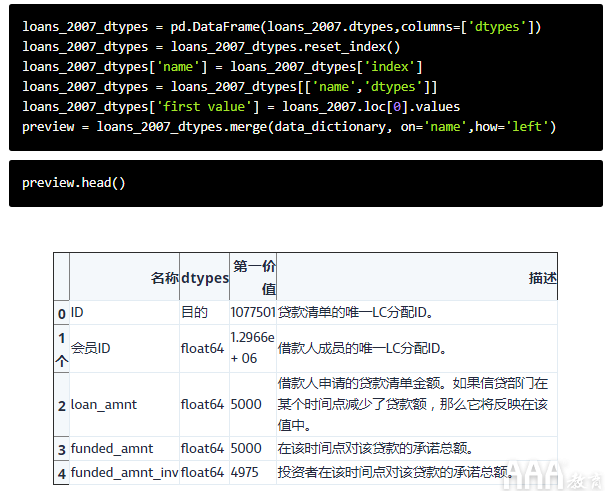
当我们打印loans_2007较早的形状时,我们注意到它有56列,因此我们知道此预览DataFrame有56行(其中一个解释loans_2007)。
尝试一次浏览预览的所有行可能很麻烦,因此,我们将其分为三个部分,每次查看较小的功能选择。当我们探索功能以更好地理解它们的每一个时,我们将要注意任何专栏文章:
泄漏未来的信息(在贷款已经被资助之后),
a、不会影响借款人的还款能力(例如个人贷款随机生成的ID值),
b、格式不佳,
c、需要更多数据或大量预处理才能变成有用的功能,或者
d、包含冗余信息。
这些都是我们要小心的事情,因为从长远来看,不正确地处理它们会损害我们的分析。
我们需要特别注意数据泄漏,这可能会导致模型过拟合。这是因为该模型还将从我们使用时将无法使用的功能中进行学习,从而对未来的贷款进行预测。我们需要确保我们的模型仅使用贷款申请时的数据进行训练。
第一组列
让我们显示的前19行preview并进行分析:
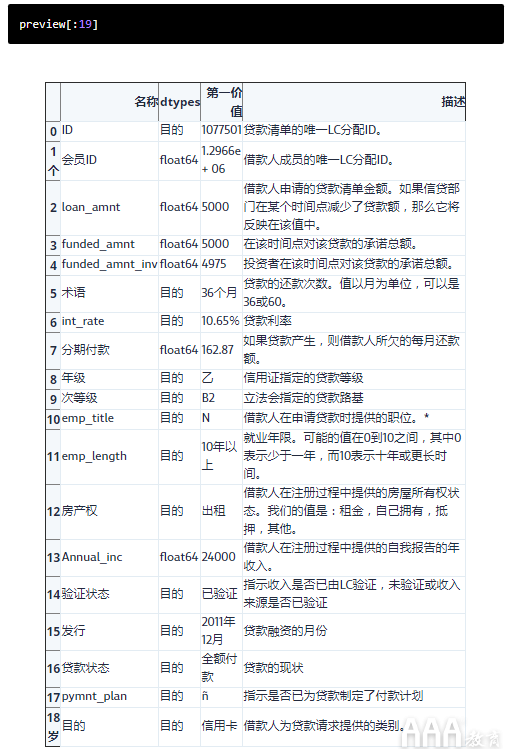
在分析了列并考虑了我们要构建的模型之后,我们可以得出结论,可以删除以下功能:
1)id —由个人贷款类随机生成的字段,仅供唯一标识。
2)member_id —也是个人贷款类随机生成的字段,仅供识别。
3)funded_amnt —泄露未来的信息(在贷款已开始提供资金之后)。
4)funded_amnt_inv -还会泄漏未来的数据。
5)sub_grade-包含该grade列中已经存在的冗余信息(更多信息在下面)。
6)int_rate-也包含在此grade列中。
7)emp_title -需要其他数据和大量处理才能变得有用
8)issued_d -泄漏未来的数据。
注意:个人贷款使用借款人的等级和还款期限(30个月或几个月)来分配利率(您可以阅读有关“ 利率和费用”的更多信息)。这会导致给定等级内利率的变化。
对于我们的模型可能有用的是集中于借款人的集群而不是个人。而且,这正是分级的作用-它根据借款人的信用评分和其他行为对借款人进行细分,这就是为什么我们将保留该grade列并降低利息int_rate和的原因sub_grade。在移到下一组列之前,让我们从DataFrame中删除这些列。

现在,我们准备继续进行下一组列(功能)。
第二组列
让我们继续进行下19列:
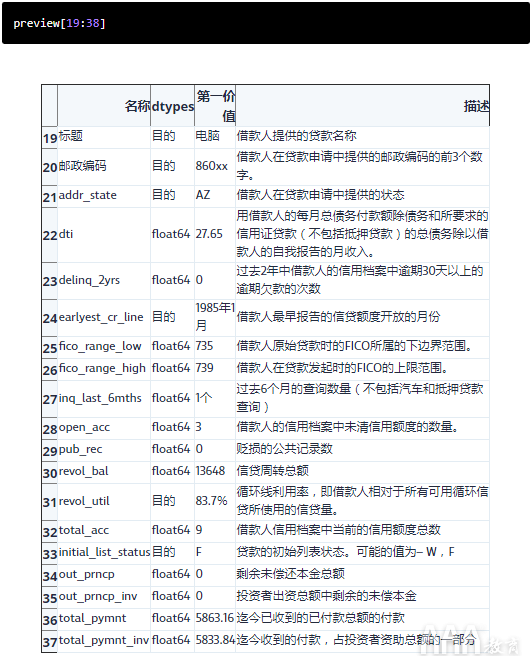
在该组中,注意fico_range_low和fico_range_high列。虽然两者都在上表中,但在查看最后一组列后,我们将进一步讨论它们。另请注意,如果您使用的是较新的个人贷款类数据,则该数据可能不包括FICO得分的数据。
现在,回顾第二组列,我们可以通过删除以下列来进一步完善数据集:
1)zip_code –对于addr_state列,大多数情况下是多余的,因为5位邮政编码中的前3位仅可见。
2)out_prncp –泄漏未来的数据。
3)out_prncp_inv –还会泄漏未来的数据。
4)total_pymnt –还会泄漏未来的数据。
5)total_pymnt_inv –还会泄漏未来的数据。
让我们继续,从DataFrame中删除以下5列:

第三组列
让我们分析最后一组功能:
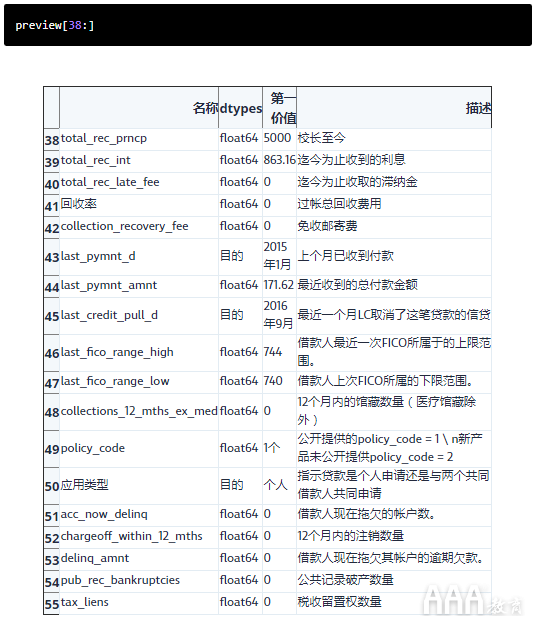
在这最后一组列中,我们需要删除以下所有列,所有这些将来都会泄漏数据:
1)total_rec_prncp
2)total_rec_int
3)total_rec_late_fee
4)recoveries
5)collection_recovery_fee
6)last_pymnt_d
7)last_pymnt_amnt
让我们删除最后一组列:
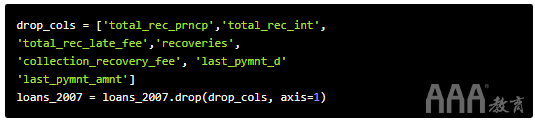
大!现在,我们有了一个数据集,它将对构建我们的模型更加有用,因为它不必浪费时间处理无关的数据,也不会通过分析来自未来的信息来“欺骗”贷款的结果。
调查FICO分数列
这是值得花一些时间来讨论fico_range_low,fico_range_high,last_fico_range_low,和last_fico_range_high列。
FICO分数是信用分数:银行和信用卡使用的数字代表一个人的信用度。尽管在美国使用的信用评分类型有几种,但FICO评分是最著名和使用最广泛的。
当借款人申请贷款,借贷俱乐部得到借款人的信用分数从FICO -他们是考虑到借款人得分范围的下限和上限属,它们存储这些值fico_range_low,fico_range_high。之后,对借方分数的任何更新都记录为last_fico_range_low和last_fico_range_high。
任何数据科学项目的关键部分是尽一切可能理解数据。在研究此特定数据集时,我发现了由斯坦福大学的一群学生于2014年发起的项目。在该项目的报告中,该小组将last_fico_range滞纳金和回收金中的当前信用评分()列为他们错误地添加到功能中的字段,但指出后来他们从这些列中了解了所有将来泄漏的信息。
但是,按照该小组的项目,斯坦福大学的另一个小组研究了相同的个人贷款数据集。他们last_fico_range_low在建模中使用了FICO分数列,仅将其删除。第二组报告被描述last_fico_range_high为预测准确结果的更重要特征之一。
有了这些信息,我们必须回答的问题是:FICO信用评分会泄露未来的信息吗?回忆一下,当我们使用模型进行预测时,如果其中包含的数据不可用,则认为该列泄漏了信息-在这种情况下,当我们在未来的贷款申请中使用我们的模型来预测借款人是否违约时。
这篇博客文章深入研究了个人贷款类贷款的FICO分数,并指出,尽管查看FICO分数的趋势可以很好地预测贷款是否会违约,但在贷款获得贷款后,个人贷款类会继续更新FICO分数。换句话说,虽然我们可以使用初始FICO分数(fico_range_low和fico_range_high)(那些可以作为借款人的应用程序的一部分提供),但我们不能使用last_fico_range_low和last_fico_range_high,因为个人贷款类可能会在借款人申请后更新这些分数。
让我们看一下我们可以使用的两列中的值:
让我们摆脱缺失的值,然后绘制直方图以查看两列的范围:
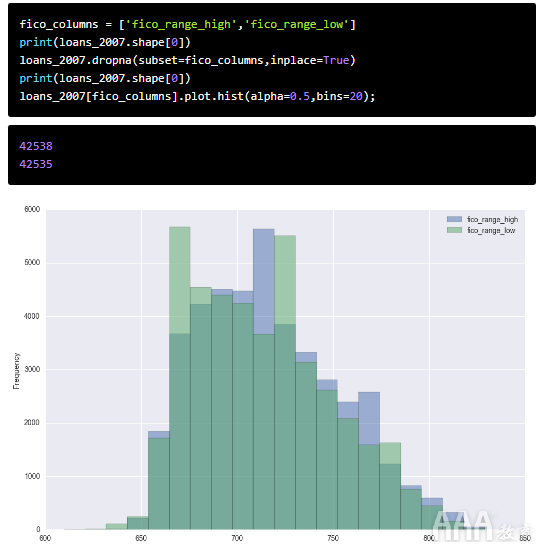
现在,让我们继续前进,创造了平均的列fico_range_low和fico_range_high列,并将它命名fico_average。请注意,这不是每个借款人的平均FICO得分,而是我们知道借款人所处的最高和最低范围的平均值。

让我们检查一下我们刚刚做了什么。
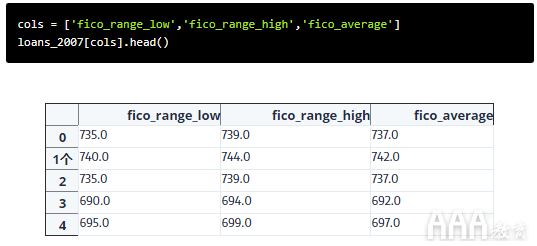
好!我们得到了均值计算,一切都正确。现在,我们可以继续下降fico_range_low,fico_range_high,last_fico_range_low,和last_fico_range_high列。
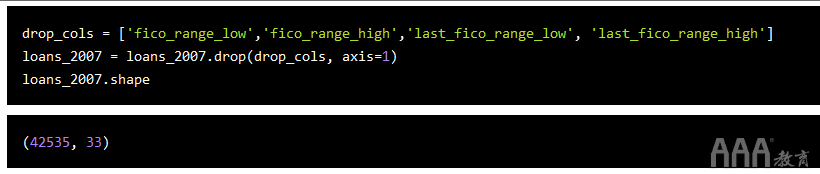
注意,只要熟悉数据集中的列,我们就可以将列数从56减少到33,而不会丢失任何对我们的模型有意义的数据。我们还通过丢弃会泄漏将来信息的数据来避免问题,而这会弄乱我们模型的结果。这就是为什么数据清理如此重要的原因!
确定目标列
现在,我们将确定适当的列以用作建模的目标列。
我们的主要目标是预测谁将还清贷款,谁将违约,我们需要找到一栏反映此情况。我们从预览DataFrame中的列描述中学到了内容,这loan_status是主数据集中描述贷款状态的唯一字段,因此让我们将此列用作目标列。
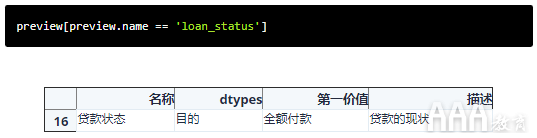
当前,此列包含需要转换为数值才能用于训练模型的文本值。让我们探索此列中的不同值,并提出转换它们的策略。我们将使用DataFrame方法value_counts()返回该loan_status列中唯一值的频率。
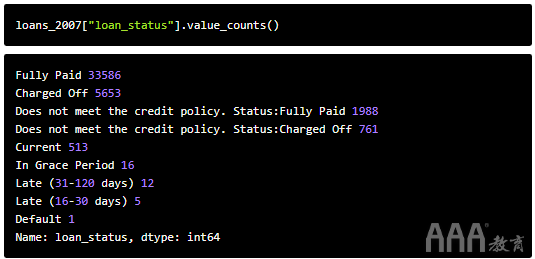
贷款状态有九种可能的值!让我们了解这些独特的值,以确定最能描述贷款最终结果的值,以及我们将要处理的分类问题。
我们可以在个人贷款类网站以及Lend Academy和Orchard论坛上阅读有关大多数不同贷款状态的信息。
下面,我们将这些数据汇总到下表中,以便我们可以看到唯一值,它们在数据集中的出现频率,并更清楚地了解每种含义:
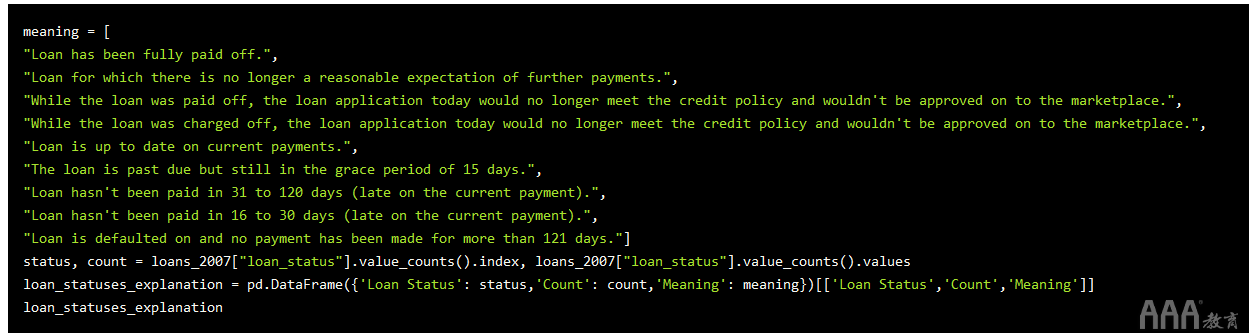
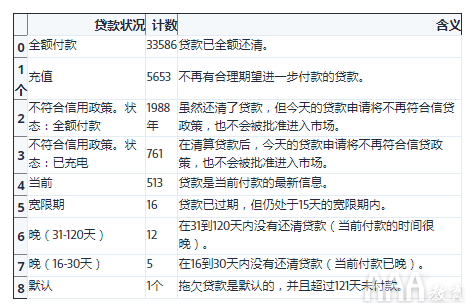
请记住,我们的目标是建立一个机器学习模型,该模型可以从过去的贷款中学习,从而试图预测哪些贷款将得到还清,而哪些则不会。在上表中,仅“已付清”和“已清还”值描述了贷款的最终结果。其他值描述的是仍在进行中的贷款,即使有些贷款延迟付款,我们也无法将其归类为“冲销”。
同样,虽然“默认”状态类似于“已注销”状态,但在个人贷款类的眼中,已注销的贷款基本上没有偿还的机会,而“违约”贷款的机会很小。因此,当我们只能使用样品loan_status列'Fully Paid'或'Charged Off'。
我们对指示贷款正在进行或正在进行的任何状态都不感兴趣,因为预测正在发生的事情不会告诉我们任何事情。
我们对能够预测将属于哪笔'Fully Paid'或'Charged Off'一笔贷款感兴趣,因此我们可以将问题视为二进制分类。让我们删除不包含'Fully Paid'或'Charged Off'作为贷款状态的所有贷款,然后将'Fully Paid'值转换1为正案例的'Charged Off'值并将值转换0为负案例的值。
这意味着在我们拥有的约42,000行中,我们将删除3,000多行。
转换列中所有值的方法很少,我们将使用DataFrame方法replace()。
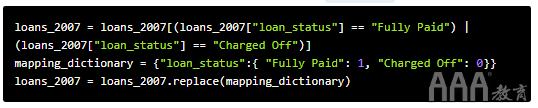
可视化目标列结果

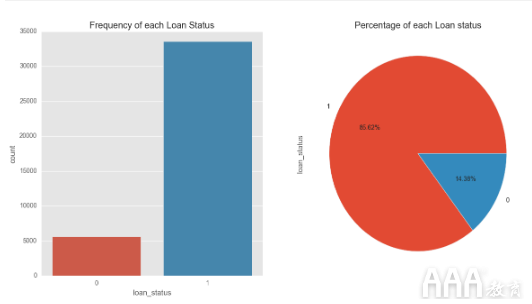
这些图表明,我们的数据集中有大量借款人还清了贷款,其中85.62%的借款人还清了借入的金额,而不幸的是有14.38%的违约。我们更感兴趣的是识别这些“违约者”,因为出于我们模型的目的,我们试图找到一种最大化投资回报的方法。
不向这些违约者提供贷款将有助于增加我们的回报,因此我们将继续着眼于清理数据,以期建立一个模型来识别应用程序中可能的违约者。
仅删除一个值的列
为了结束本节,让我们查找仅包含一个唯一值的所有列并将其删除。这些列不会对模型有用,因为它们不会向每个贷款申请添加任何信息。此外,删除这些列将减少我们在下一阶段需要进一步探讨的列数。
pandas Series方法nunique()返回唯一值的数量,不包括任何空值。我们可以在整个数据集上应用此方法,只需一个简单的步骤即可删除这些列。

同样,可能有一些列具有多个唯一值,但其中一个值在数据集中的频率很小。让我们查找并删除任何唯一值少于四次的列:
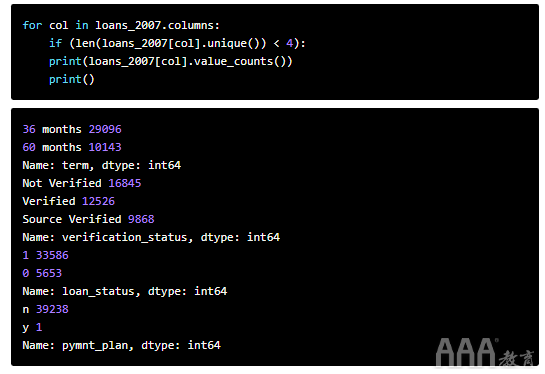
付款计划列(pymnt_plan)具有两个唯一值'y'和'n','y'仅出现一次。让我们删除此列:
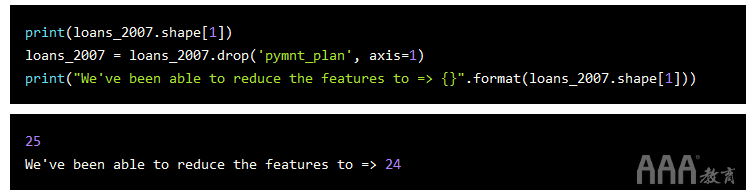
最后,让我们使用熊猫将我们刚清洗的DataFrame保存为CSV文件:

现在,我们有了更好的数据集。但是我们还没有完成数据清理工作,所以让我们继续吧!
步骤3:为机器学习准备功能
在本节中,我们将准备filtered_loans_2007.csv用于机器学习的数据。我们将专注于处理缺失值,将分类列转换为数字列并删除任何其他无关的列。
在将数据输入机器学习算法之前,我们需要处理缺失值和分类特征,因为大多数机器学习模型所基于的数学假定数据是数值的并且不包含缺失值。为了加强此要求,如果在使用线性回归和逻辑回归等模型时尝试使用包含缺失值或非数字值的数据训练模型,则scikit-learn将返回错误。
以下是我们在此阶段将要做的事情的概述:
a、处理缺失值
b、调查分类列
1)将分类列转换为数值特征
i)将序数值映射为整数
ii)将标称值编码为虚拟变量
不过首先,让我们从上一节的最终输出中加载数据:
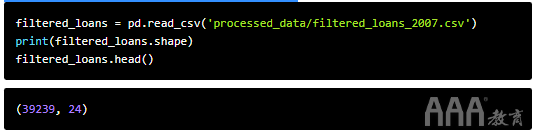

处理缺失值
让我们计算缺失值的数量并确定如何处理它们。我们可以像这样在整个DataFrame中返回缺失值的数量:
a)首先,使用Pandas DataFrame方法isnull()返回包含布尔值的DataFrame:
1)True 如果原始值为null
2)False 如果原始值不为null
b)然后,使用Pandas DataFrame方法sum()计算每列中空值的数量。
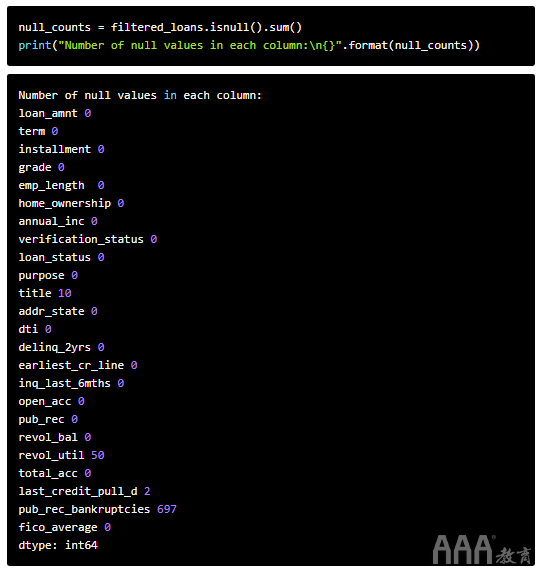
请注意,尽管大多数列都有0个缺失值,title有9个缺失值,revol_util有48个,并pub_rec_bankruptcies包含675行有缺失值。
让我们完全删除列中该列中超过1%(392)的行包含空值的列。此外,我们将删除其余包含空值的行。这意味着我们将丢失一些数据,但作为回报,保留一些额外的功能以用于预测(因为我们不必删除那些列)。
我们将保留title和revol_util列,只是删除包含缺失值的行,但pub_rec_bankruptcies由于该行中有1%以上的行具有缺失值,因此将其完全删除。
具体来说,这是我们要做的事情:
a)使用滴法去除pub_rec_bankruptcies从列filtered_loans。
b)使用dropna方法,从删除所有行filtered_loans包含任何遗漏值。
这就是代码中的样子。

请注意,有多种方法可以处理缺失值,这是用于机器学习的数据清理中最重要的步骤之一。我们针对Python的数据清理高级课程对清理数据时遗漏的值进行了更深入的探讨,这将是深入学习该主题的重要资源。
不过,出于此处的目的,我们已经完成了这一步,因此让我们继续使用分类列。
调查分类列
我们的目标是最终获得一个可供机器学习使用的数据集,这意味着它不包含任何缺失值,并且列中的所有值均为数字(浮点或整型数据类型)。
我们已经处理了缺少的值,所以现在让我们找出对象数据类型的列数,并弄清楚如何使这些值成为数字。
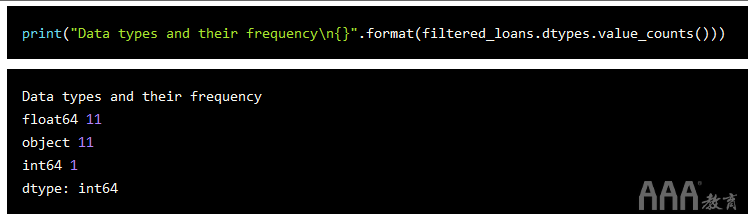
我们有11个对象列,其中包含需要转换为数字特征的文本。让我们使用DataFrame方法select_dtype只选择对象列,然后显示一个示例行,以更好地了解每一列中的值如何格式化。
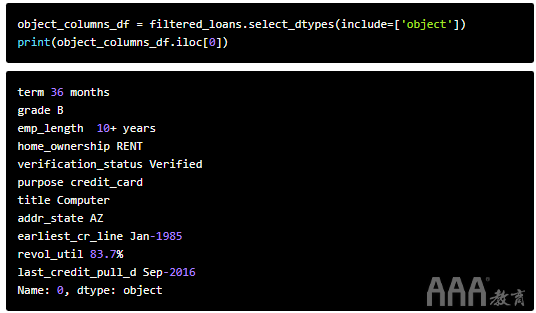
请注意,该revol_util列包含数值,但被格式化为对象。我们从preview前面的DataFrame 列描述中学到的revol_util是“循环使用率或借款人相对于所有可用信贷所使用的信贷量”(在此处了解更多)。我们需要将其格式化revol_util为数字值。这是我们可以做的:
a、使用str.rstrip()字符串方法去除右尾的百分号(%)。
b、在产生的Series对象上,使用astype()方法转换为type float。
c、将新的系列浮点值重新分配给中的revol_util列filtered_loans。

继续,这些列似乎代表分类值:
1)home_ownership —房屋所有权状态,根据数据字典,只能是4个分类值中的1个。
2)verification_status —表示收入是否已由个人贷款类验证。
3)emp_length -借款人在申请时受雇的年限。
4)term -贷款的还款次数,为36或60。
5)addr_state -借款人的居住地。
6)grade — LC根据信用评分分配贷款等级。
7)purpose —借款人为贷款请求提供的类别。
8)title -借款人提供了借款名称。
可以肯定的是,让我们通过检查每个值中的唯一值来进行确认。
此外,基于第一行的对值purpose和title,看来这两列反映了同样的信息。我们将分别探索其唯一值计数,以确认是否为真。

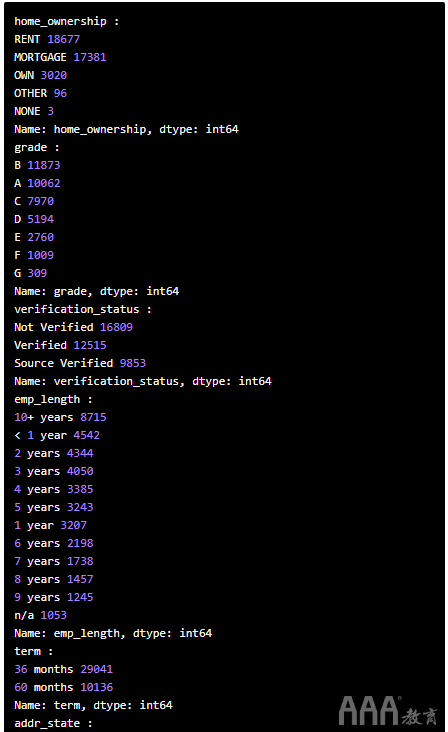
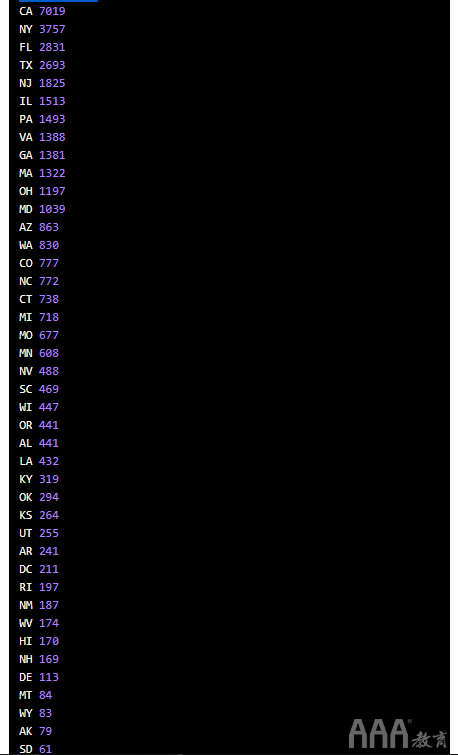
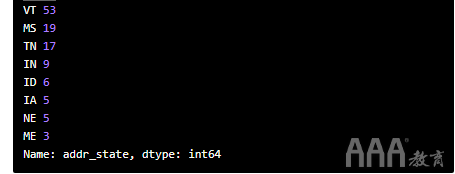
最后,请注意第一行的值earliest_cr_line和last_credit_pull_d列的值都包含日期值,这些日期值需要大量的功能设计,以使其可能有用:
1)earliest_cr_line —借款人最早报告的信贷额度开放的月份。
2)last_credit_pull_d —最近一个月个人贷款类提取了此笔贷款的信贷。
对于某些分析,进行此功能工程可能是值得的,但是出于本教程的目的,我们将仅从DataFrame中删除这些日期列。
首先,让我们探索看起来好像包含分类值的六列的唯一值计数:
这些列大多数包含离散的分类值,我们可以将其编码为虚拟变量并保留。addr_state但是,该列包含太多唯一值,因此最好删除它。
接下来,让我们看看purpose和title列的唯一值计数,以了解我们要保留哪些列。
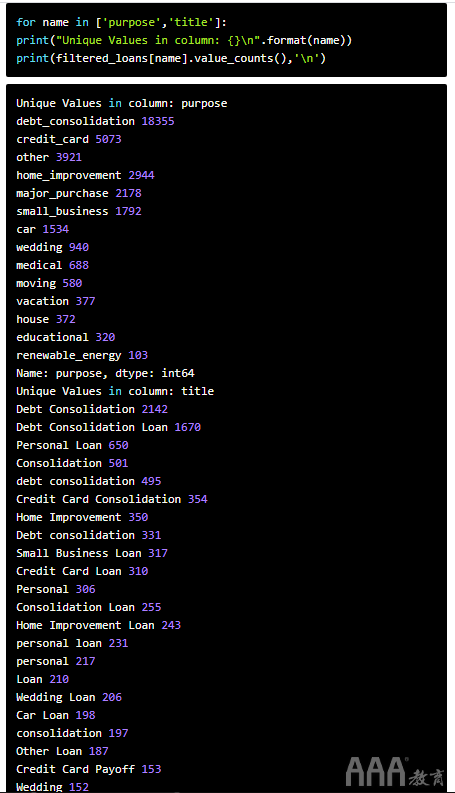
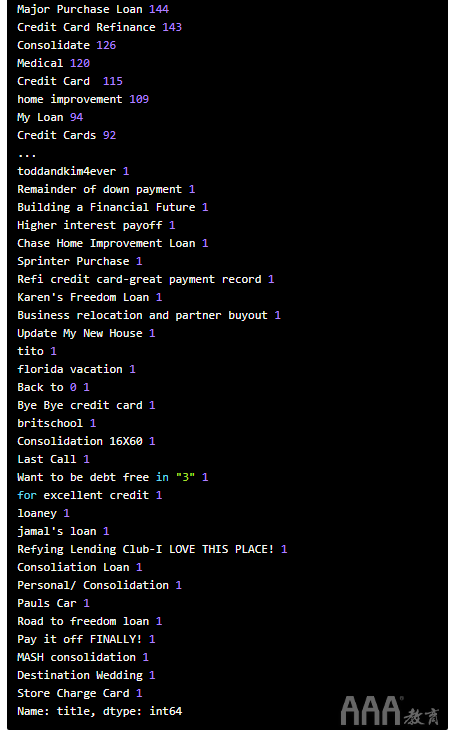
似乎purpose和title列确实包含重叠的信息,但是该purpose列包含的离散值较少并且更整洁,因此我们将其保留并丢弃title。
让我们删除到目前为止我们决定不保留的列:

将分类列转换为数值特征
首先,让我们了解数据集中的两种分类特征,以及如何将它们转换为数字特征:
有序值:这些分类值是自然顺序的。我们可以按升序或降序对它们进行排序或排序。例如,我们较早地了解到个人贷款类将贷款申请人的等级从A 分级为G,并为每个申请人分配相应的利率-A等级风险最低,B等级风险高于A,依此类推:
A
标称值:这些是常规分类值。您不能订购标称值。例如,虽然我们可以emp_length根据在劳动力中花费的年限在“就业时长”列()中订购贷款申请人:
1年<2年<3年…
我们无法通过专栏来做到这一点purpose。说:
汽车<婚礼<教育<移动<房子
这些是我们现在在数据集中具有的列:
序数值
1)grade
2)emp_length
标称值 _home_ownership
1)verification_status
2)purpose
3)term
有两种不同的方法来处理这两种类型。为了序值映射到整数,我们可以使用数据框大熊猫方法replace()来映射两者grade并emp_length以适当的数值:
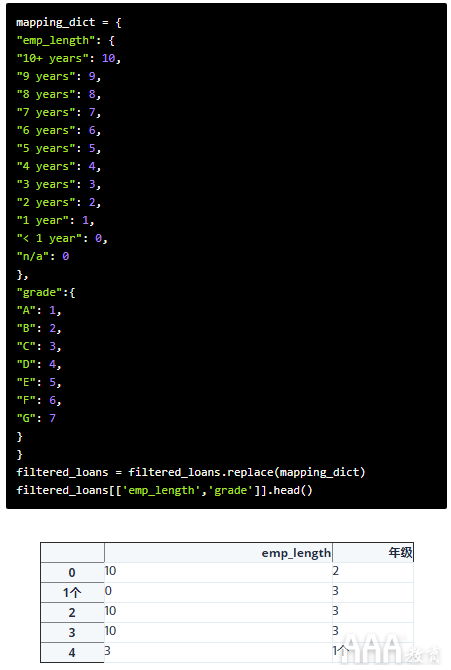
完善!让我们继续看名义值。将名义特征转换为数字特征需要将其编码为伪变量。该过程将是:
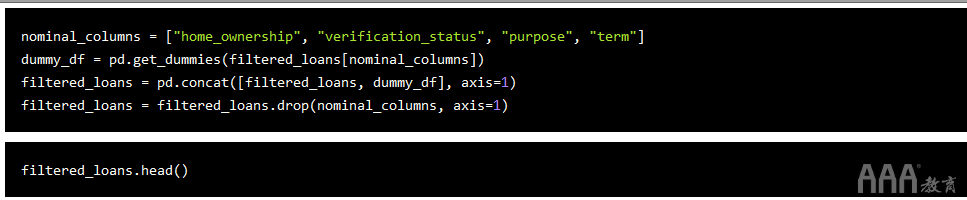
1)使用pandas的get_dummies()方法返回一个新的DataFrame,其中包含每个虚拟变量的新列。
2)使用该concat()方法将这些虚拟列添加回原始DataFrame。
3)使用drop方法完全删除原始列。
让我们继续对数据集中的标称列进行编码:

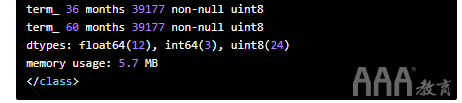
总结一下,让我们检查一下本节的最终输出,以确保所有要素的长度相同,不包含空值且为数字。我们将使用pandas的info方法来检查filtered_loansDataFrame:
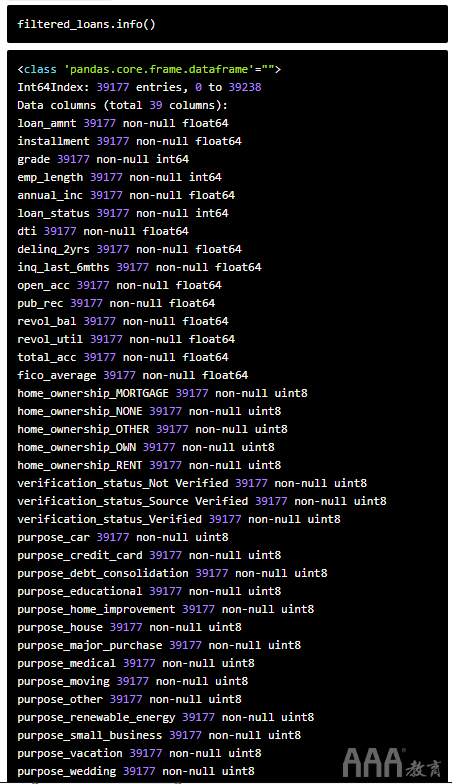
一切看起来都不错!恭喜,我们刚刚清理了大数据集进行机器学习,并在此过程中为我们的库添加了一些有价值的数据清理技能。
但是,我们仍然需要完成一项重要的最终任务!
保存为CSV
最好将工作流的每个部分或阶段的最终输出存储在单独的csv文件中。这种做法的好处之一是,它可以帮助我们更改数据处理流程,而不必重新计算所有内容。
和以前一样,我们可以使用方便的pandas to_csv()函数将DataFrame存储为CSV 。

下一步
在本文中,我们介绍了处理大型数据集,清理数据并为机器学习项目准备数据所需的基本步骤。但是,还有很多东西要学习,您可以从这里选择许多不同的方向。
如果您对数据清理技能感到满意,并且想更多地使用该数据集,请查看我们的交互式机器学习演练课程,该课程涵盖了使用个人贷款数据的后续步骤。
如果您想继续研究数据清理技能,请查看我们的一个(或多个)交互式数据清理课程,以更深入地研究这项关键的数据科学技能:
1)数据清理和分析课程(Python)
2)高级数据清理课程(Python)
3)数据清理(R)
填写下面表单即可预约申请免费试听!怕钱不够?可先就业挣钱后再付学费! 怕学不会?助教全程陪读,随时解惑!担心就业?一地学习,可推荐就业!
©2007-2022/ www.aaa-cg.com.cn 北京漫动者数字科技有限公司 备案号: 京ICP备12034770号 监督电话:010-53672995 邮箱:bjaaa@aaaedu.cc

 热门推荐
热门推荐
 UI设计
UI设计
 产品经理
产品经理
 大数据分析
大数据分析
 原画设计
原画设计
 平面设计
平面设计
 新媒体运营
新媒体运营 






