现代艺术博物馆是世界上最有影响力的博物馆之一,他们已经发布了有关其收藏中艺术品的数据集。但是,数据集存在一些数据质量问题,需要清理。
在之前我们发布的文章中,我们讨论了如何使用Python和Pandas清理数据集。在大数据分析如何使用命令行和csvkit清洁CSV数据中,我们将学习如何使用该csvkit库来获取和探索表格数据。
为什么使用命令行?
好问题!在云大数据分析环境中工作时,有时您只能访问服务器的外壳。在这些情况下,精通命令行大数据分析才是真正的超级大国。随着您变得更加熟练,使用命令行执行某些大数据分析任务比编写Python脚本或Hadoop作业要快得多。
最后,命令行具有丰富的工具生态系统,并且可以集成到文件系统中。这使得某些类型的任务(尤其是涉及多个文件的任务)异常简单。期望大数据分析如何使用命令行和csvkit清洁CSV数据有一些在命令行上工作的经验。如果您不熟悉命令行,建议您阅读我们的交互式命令行课程
csvkit
csvkit是一个为处理CSV文件而优化的库。它是用Python编写的,但是主要界面是命令行。您可以csvkit使用安装pip:

您将需要这个库来跟随大数据分析如何使用命令行和csvkit清洁CSV数据。
数据采集
MOMA艺术品数据集可在博物馆的Github回购中找到。让我们使用从Githubcurl下载Artworks.csv。curl是大多数Shell环境中内置的工具,使您可以在服务器之间传输数据。Github为每个文件提供直接URL,您可以通过单击Raw按钮找到它们。
最后,我们将使用>运算符将输出重定向curl到名为的文件artworks.csv。

数据探索
我们可以使用该head命令显示n文件的第一行(默认为10行)。要显示前三行,可以使用以下任一命令:
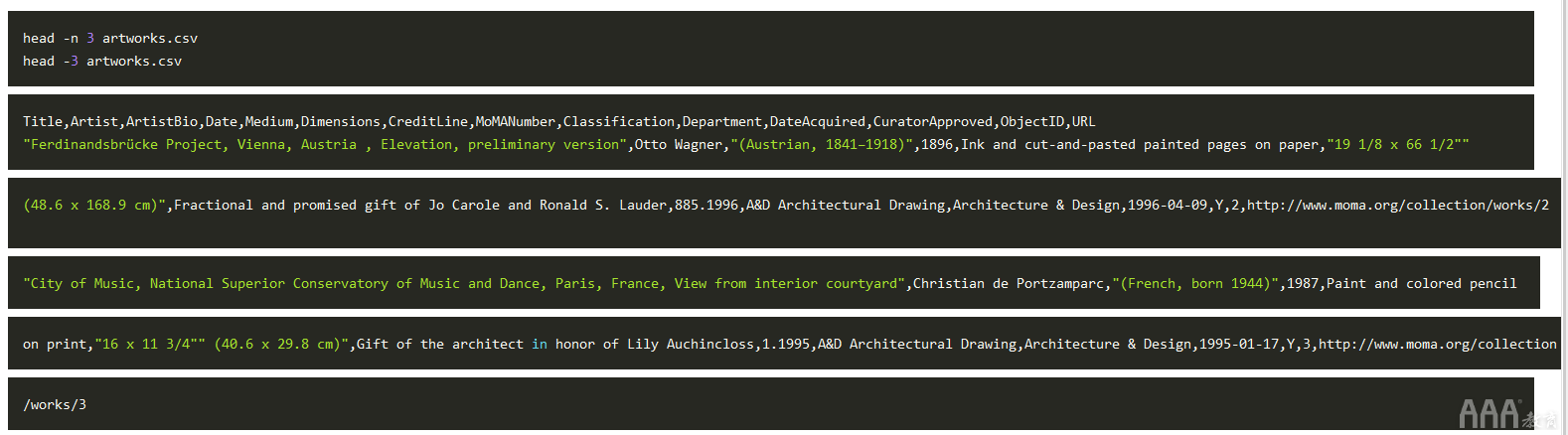
与大多数数据集一样,第一行看起来包含列标题。除此之外,输出杂乱无章,很难从默认输出中收集其他信息。我们需要一个知道如何以可读方式显示CSV文件的工具。
csvlook
csvlook是其中的工具csvkit,可让您以表格形式显示和预览CSV文件。csvlook artworks.csv将显示整个数据集,这很麻烦进行探索。让我们来代替管stdout的head -5 artworks.csv,以csvlook探索前5行:


这是代表管道的图:
尽管现在输出更容易阅读,但仍然很难探索。现在,让我们学习如何使用csvcut仅选择一些列并显示它们。
csvcut
csvcut是其中的一种工具csvkit,称为数据解剖刀,因为它允许您切片和修改CSV中的列。首先使用-n标记列出所有列:
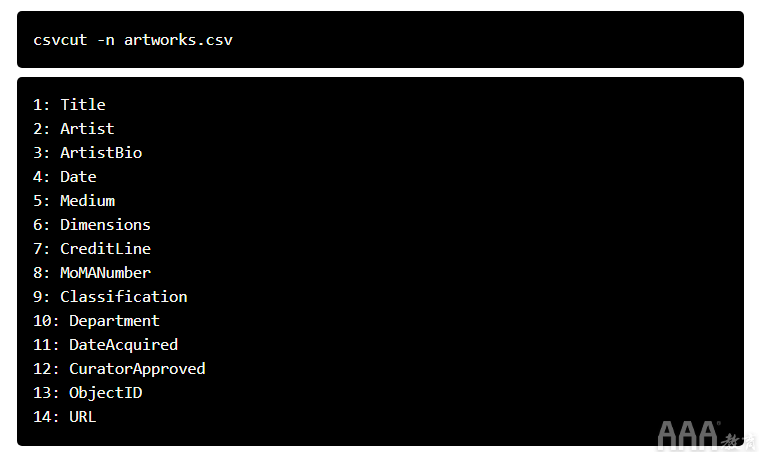
然后,我们可以使用该-c标志来指定所需的列。csvcut -c 1,2,3 artworks.csv | csvlook将返回前3列。您也可以自己使用列名称:csvcut -c Artist,ArtistBio,Date。运行这两个命令将显示整个数据集的3列,因此我们需要利用管道系统来查看仅几行。
我们可以查阅csvkit 文档以了解csvkit实用程序之间的管道:
所有csvkit实用程序都接受输入文件作为“标准输入”,以及文件名。这意味着我们可以使一个csvkit实用程序的输出成为下一个的输入。
这意味着我们可以管stdout的csvcut到stdin的csvlook!我们可以建立以下管道:
1)仅10使用提取第一行head
2)3使用 仅过滤到第一列csvcut
3)使用干净的方式显示 csvlook


csvgrep
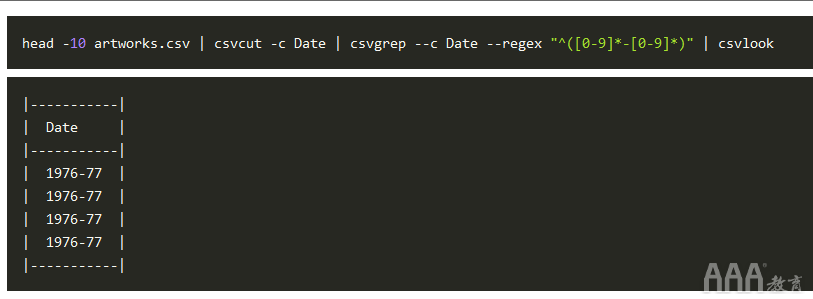
在使用历史数据集时,我们需要确保日期和时间列的格式正确(甚至基本的时间序列图都无法使用)。让我们探索Date和DateAcquired列:
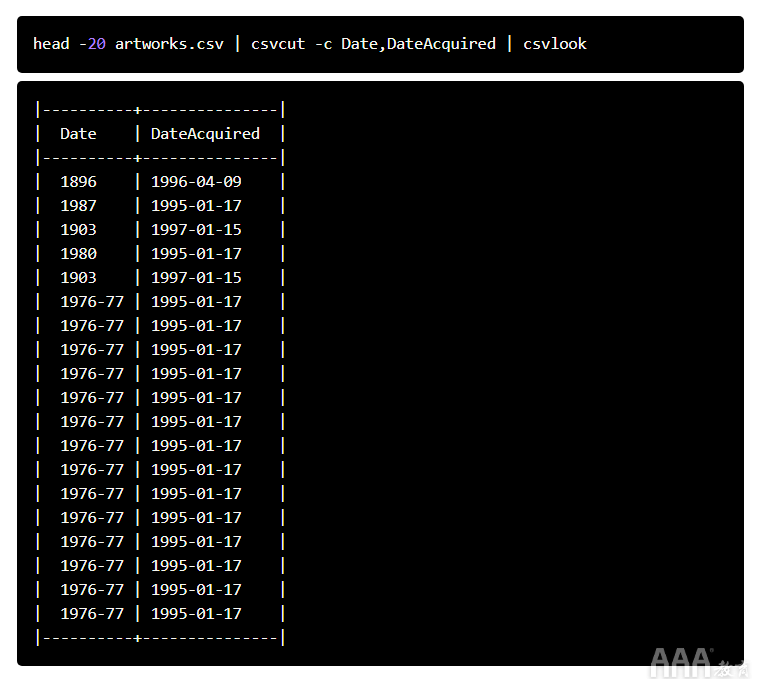
虽然前20个值DateAcquired看起来不错,但该Date列中的一些值在大多数数据可视化工具(如)中无法很好地发挥作用1976-77。我们只需选择范围内的第一年即可轻松解决这一问题(例如,1976从范围内1976-77)。在此之前,让我们找出与该模式匹配的行数。
我们可以使用该csvgrep工具提取与正则表达式匹配的一列(或多列)中的所有值。我们csvgrep使用-c标记指定要匹配的列。我们csvgrep使用-regex标志指定要使用的正则表达式。正则表达式^([0-9]*-[0-9]*)匹配以连字符(-)分隔的数字对。
由于我们在列上搜索模式的实例,因此Date我们编写以下代码:

让我们修改并运行我们构建为合并的管道csvgrep:
csvstat
精彩!现在我们知道它可以工作,让我们将正则表达式应用于整个Date列(而不只是前10行),并确定有多少行与该模式匹配。该csvstat工具将CSV作为输入(stdin),并计算摘要统计信息。我们可以使用该--count标志来指定只需要行数。
我们也可以删除csvcut,head和,csvlook因为我们不需要显示输出。

看起来有18,073行与该模式匹配。现在计算一下:
1)多少行与4位数字年份模式匹配
2)数据集包含多少行
我们可以使用正则表达式(^[0-9]{4}$)查找所有4位数字的年份值并将结果通过管道传递给csvstat:

最后,要获取数据集的总行数,我们可以将wc命令与-l标志一起使用(仅显示行数):

如果将与4位数字的年份正则表达式(76263)相匹配的行数与与年份范围的正则表达式(18073)相匹配的行数相结合,则会得到(94336)行。鉴于总共有137,382行,这是我们分析的一个很好的起点!
填写下面表单即可预约申请免费试听!怕钱不够?可先就业挣钱后再付学费! 怕学不会?助教全程陪读,随时解惑!担心就业?一地学习,可推荐就业!
©2007-2022/ www.aaa-cg.com.cn 北京漫动者数字科技有限公司 备案号: 京ICP备12034770号 监督电话:010-53672995 邮箱:bjaaa@aaaedu.cc

 热门推荐
热门推荐
 UI设计
UI设计
 产品经理
产品经理
 大数据分析
大数据分析
 原画设计
原画设计
 平面设计
平面设计
 新媒体运营
新媒体运营 






