凌乱的数据集无处不在。如果要分析数据,不可避免地需要清理数据。在大数据分析R语言tidyverse数据清洗工具教程中,我们将研究如何使用R和一些漂亮的tidyverse工具来做到这一点。
该tidyverse工具提供了强大的方法来诊断和清理杂乱的数据集,R.虽然有更为我们可以用tidyverse做,在大数据分析R语言tidyverse数据清洗工具教程中,我们将重点学习如何:
1、将逗号分隔值(CSV)和Microsoft Excel平面文件导入R
2、合并数据框
3、清理列名
4、更多消息!
tidyverse是为处理数据而设计的R程序包的集合。tidyverse软件包具有共同的设计理念,语法和数据结构。Tidyverse包“一起玩”。使用tidyverse,您可以花费更少的时间来清理数据,从而可以将更多的精力放在分析,可视化和建模数据上。
一、干净数据和混乱数据的特征
什么是干净数据?干净的数据是准确,完整的,并且格式易于分析。干净数据的特征包括以下数据:
1、没有重复的行/值
2、无错误(例如,没有拼写错误)
3、相关(例如,无特殊字符)
4、适当的数据类型进行分析
5、没有异常值(或仅包含已识别/理解的异常值)
6、遵循“整洁的数据”结构
数据混乱的常见症状包括包含以下内容的数据:
1、特殊字符(例如,数字中的逗号)
2、存储为文本/字符数据类型的数值
3、行重复
4、拼写错误
5、不正确的地方
6、空格
7、缺失数据
8、零而不是空值
二、动机
在大数据分析R语言tidyverse数据清洗工具教程文章中,我们将使用五个可在纽约市财政部滚动销售数据网站上公开获得的房地产销售数据集。我们鼓励您下载数据集并继续学习!每个文件都包含纽约市五个行政区之一的一年的房地产销售数据。我们将使用以下Microsoft Excel文件:
1、Rollingsales_bronx.xls
2、Rollingsales_brooklyn.xls
3、Rollingsales_manhattan.xls
4、Rollingsales_queens.xls
5、Rollingsales_statenisland.xls
当我们处理大数据分析R语言tidyverse数据清洗工具教程文章时,请想象您正在帮助一个朋友在纽约市开展他们的房屋检查业务。您可以通过分析数据来帮助他们,以更好地了解房地产市场。但是您意识到在分析R中的数据之前,您需要首先进行诊断和清理。在诊断数据之前,您需要将其加载到R中!
三、使用readxl将数据加载到R中
使用tidyverse工具的好处通常在数据加载过程中显而易见。在许多情况下,readxl当Microsoft Excel数据加载到R中时,tidyverse软件包会为您清除一些数据。如果您正在使用CSV数据,则tidyverse readr软件包功能read_csv()是要使用的功能(稍后将介绍)。
让我们来看一个例子。这是布鲁克林区的Excel文件的外观:
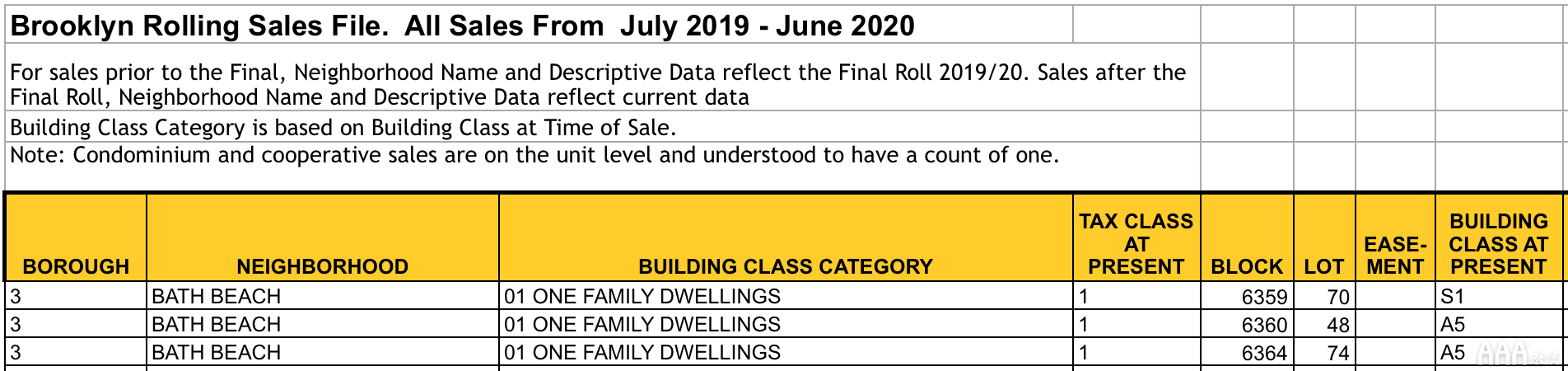
现在,让我们从Excel文件将Brooklyn数据集加载到R中。我们将使用该readxl包。我们指定函数自变量skip = 4是因为我们要用作标题的行(即列名)实际上是第5行。我们可以完全忽略前四行,并将数据从第5行开始加载到R中。这是代码:

请注意,我们将此数据集保存为变量名称,brooklyn以备将来使用。
四、使用tidyr :: glimpse()查看数据
tidyverse提供了一种用户友好的方式glimpse(),可使用tibble包装中的功能查看此数据。要使用此程序包,我们将需要加载它以便在当前会话中使用。但是,我们不仅可以单独加载此程序包,还可以一次加载许多tidyverse程序包。如果没有tidyverse软件包集合,请在R或R Studio会话中使用以下命令将其安装在计算机上:

安装软件包后,将其加载到内存中:

现在已将tidyverse其加载到内存中,对布鲁克林数据集进行“瞥见”:
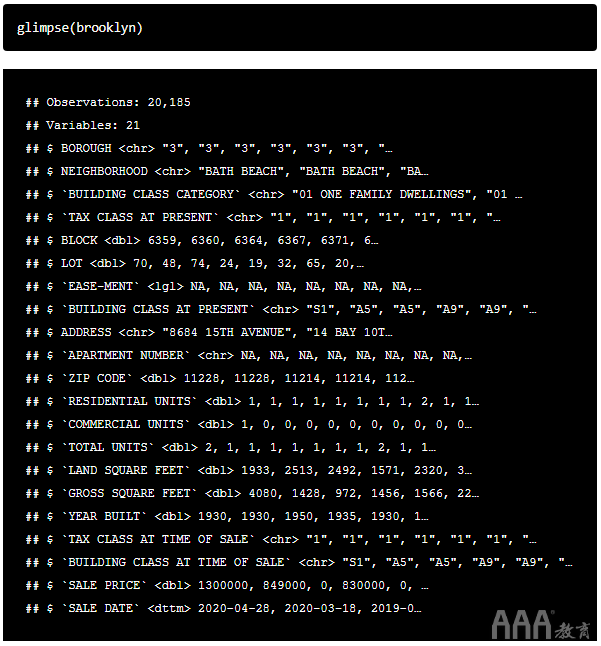
该glimpse()功能提供了一种用户友好的方式,可以查看数据框中所有列或变量的列名和数据类型。使用此功能,我们还可以查看数据框中的前几个观察值。该数据框包含20,185个观测值或房地产销售记录。并且有21个变量或列。
五、数据类型
查看每一列的数据类型,我们通常会发现数据以一种随时可以使用的格式存储!例如:
1、NEIGHBORHOOD 是“字符”类型,也称为字符串。
2、GROSS SQUARE FEET (即属性的大小)的类型为“ double”,是R中“数字”类的一部分。
3、SALE PRICE 也是数字。
4、SALE DATE 以代表日历日期和时间的格式存储。
那么为什么这很重要呢?因为GROSS SQUARE FEET和SALE PRICE是数字,所以我们可以立即对数据执行算术运算。例如,我们可以计算所有物业的平均售价:

六、准备绘图!
SALE DATE以表示日历日期和时间的格式存储该数据很有用,因为这使我们能够使用一行代码来按日期绘制房地产销售的直方图:
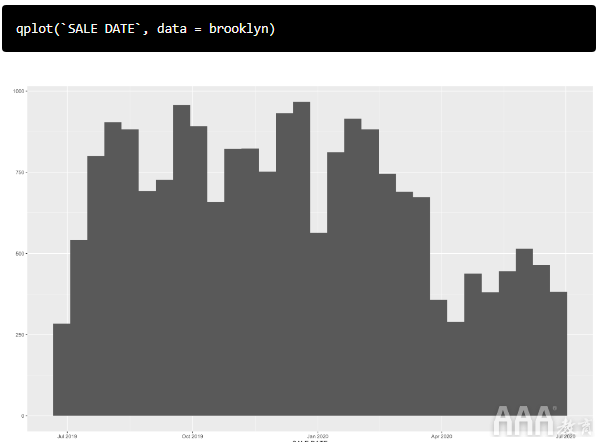
请注意,2020年4月房地产销售急剧下降。这可能与COVID-19大流行有关吗?如您所见,仅需几行代码,我们就可以开始探索数据并提出一些有趣的问题!
请注意,用于制作直方图的qplot()函数来自ggplot2软件包,这是一个核心tidyverse软件包。
七、与read.csv()比较
该readxl()功能对我们有多大帮助?让我们将其与R中内置的read.csv()功能进行比较。为此,我们下载了原始Excel文件,在Mac上的Numbers程序中将其打开,然后将文件转换为CSV。当然,这种工作流程并不理想,但对于分析人员来说,更喜欢以CSV格式读取表格数据并不少见。
这是我们使用CSV格式加载相同数据时看到的内容read.csv():
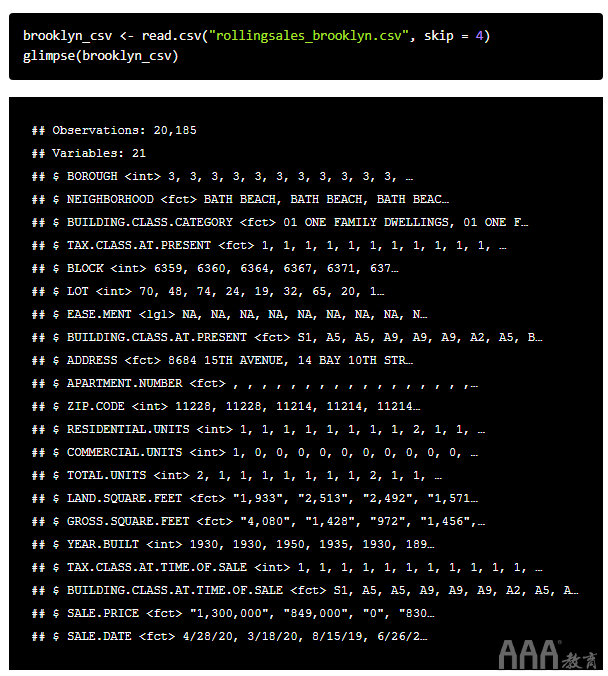
这些数据比较混乱!方法如下:
1、诸如的字符(字符串)数据ADDRESS已存储为“ factor”类。将因素视为类别或存储桶。
2、GROSS.SQUARE.FEET并且SALE.PRICE也存储为因素。我们不能在一个因子上执行算术运算,例如计算均值!
3、SALE.DATE不会以代表日历日期和时间的格式存储。因此,我们无法建立上面看到的直方图。(我们可以制作一个直方图,但这很麻烦,而且没有意义)。
4、在GROSS.SQUARE.FEET与SALE.PRICE列包含特殊字符,逗号(,)。
但是,如果我们与加载相同的数据集read_csv()功能,从readr包装,这是tidyverse部分,我们看到类似于我们用原来的做法结果readxl():
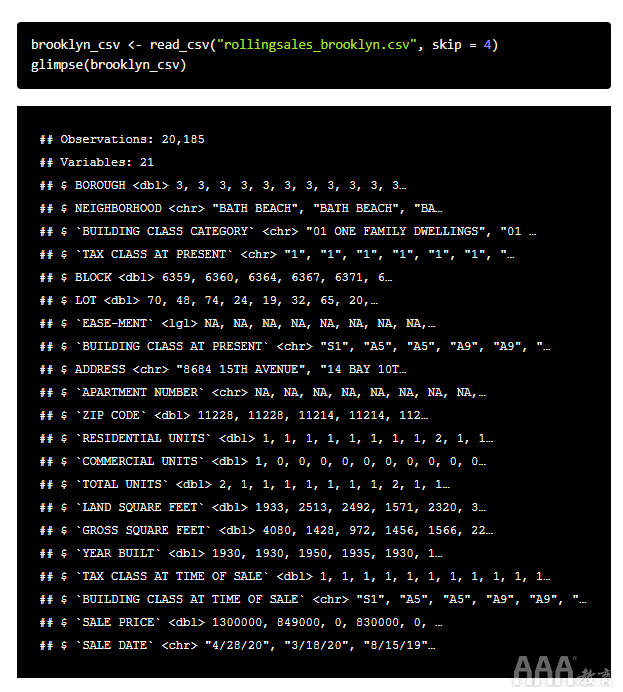
总而言之,使用readxl()或将数据加载到R中的关键区别在于read_csv(),没有任何变量被强制转换为factor数据类型。代替。许多变量被加载为字符或字符串数据类型。
另外,请注意,该Sale Price列中缺少特殊字符,并且该列已作为a double或数字数据类型加载。这意味着我们可以立即执行与销售价格有关的计算,而无需采取额外步骤即可将列转换为数字!
八、合并数据集
如果我们要对纽约市所有五个行政区进行数据分析,则将数据集组合起来将很有帮助。另外,如果数据需要任何其他清理,那么最好只在一个地方而不是五个地方清理数据!我们已经验证了五个Excel文件中的每个列名都相同。因此,我们可以将数据框与包中的bind_rows()功能dplyr(另一个tidyverse包!)结合使用:
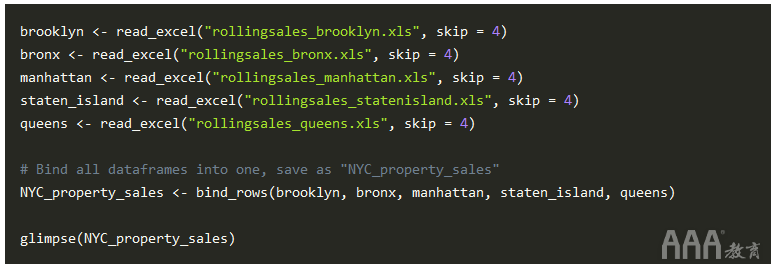
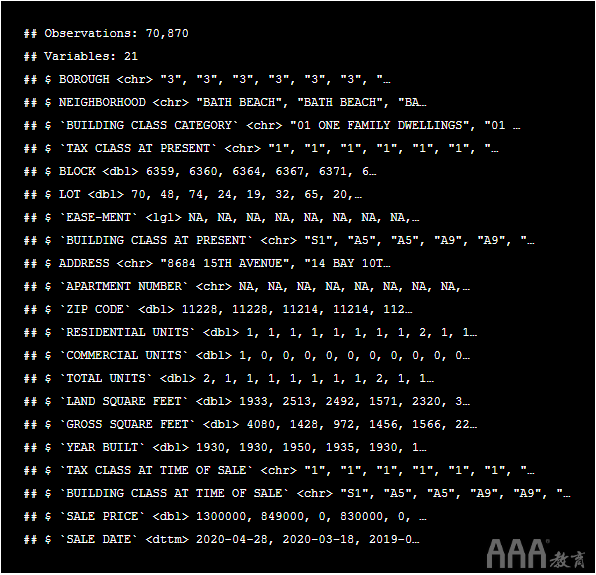
该NYC_property_sales数据框还包含21个变量,例如brooklyn数据框。这很好,因为它可以确认所有五个数据集都具有完全相同的列名,因此我们无需进行任何更正即可合并它们!该bind_rows()函数本质上是将五个数据帧彼此堆叠在一起以形成一个。
如果我们将这些数据框组合在一起并得到比该brooklyn数据框更多的列,则可能表明存在问题,例如其中一个数据集中的列名错误。但这并没有发生,因此我们可以继续清理列名。
九、用magrittr Magic清理列名!
现在是时候在AAA教育上获取我们最喜欢的数据清理技巧之一了!
列名包含空格,在tidyverse中可能很难使用。此外,列名称包含大写字母。我们不想在分析过程中担心空格或记住大写变量名!让我们使用magrittr包中的便捷方法快速清除列名。首先将程序包加载到内存中。如果需要,请安装该软件包。tidyverse中使用了“ magrittr”包,但我们需要显式加载它才能访问其内置函数之一。

我们将使用magrittr软件包中的“分配管道”功能来有效地更新所有变量名称。管道是功能强大的工具,可让R用户一次将多个操作链接在一起。管道还使R代码更具可读性,更易于理解。使用tidyverse工具时,管道被广泛使用。
让我们将赋值管道运算符与str_replace_all()tidyverse stringr包中的函数结合起来,用下划线替换所有空格。NYC_property_sales数据框的代码如下所示:

那么这是怎么回事?想到的%<>%意思是“然后更新”。让我们将其放在上下文中。上面的代码行实质上意味着:
从NYC_property_sales数据框中获取列名,然后更新所有列名以用下划线替换所有空格,然后将所有列名更新为小写。
这句话很长!但这证明了管道运算符将多个命令链接在一起的价值。让我们看一下更新的列名称:
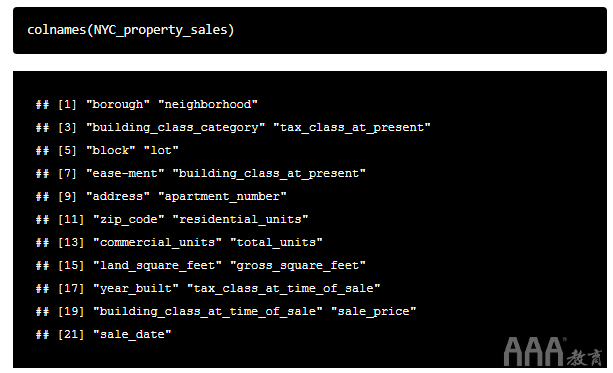
看起来更好!
十、管道操作
通常,在使用tidyverse工具时,我们将使用中的单管道(%>%)magrittr。管道是将多个命令链接在一起的一种方式。回想一下我们如何将其%<>%视为“然后更新”?好吧,单个管道可以简单地认为是“然后”。这是一个使用我们到目前为止学习的命令的示例:

这大致可转换为:
让我们抓住NYC_property_sales数据框,然后瞥一眼数据。
回顾
哇,看看我们在这大数据分析R语言tidyverse数据清洗工具教程文章中介绍的所有内容:
1、read_excel()使用readxl包中的功能将Microsoft Excel平面文件加载到R中
2、使用软件包中的read_csv()功能导入CSV文件readr
3、使用包中的glimpse()功能查看数据帧特征tibble
4、使用包中的qplot()函数生成直方图ggplot2
5、将数据框与包中的bind_rows()功能组合在一起dplyr
6、使用magrittr包和stringr包中的函数清理列名
7、将命令与单管道(%>%)链接在一起magrittr
如您所见,tidyverse软件包是用于加载,清理和检查数据的功能非常强大的工具,因此您可以立即开始分析数据!请记住,您可以使用一次加载所有这些软件包library(tidyverse)。
其他资源
如果您是R和tidyverse的新手,我们建议从R课程中的AAA教育数据分析入门开始。这是AAA教育 Data Analyst中R路径中的第一门课程。
哈德利·威克汉姆(Hadley Wickham)和加勒特·格罗勒蒙德(Garrett Grolemund)所著的《R for Data Science》一书涵盖了我们在这里介绍的很多内容(还有更多!)。我们为所有学习R的人推荐这本书。
奖励:备忘单
RStudio已发布了大量使用R和tidyverse工具的备忘单。与该职位相关的备忘单包括:
1、数据导入备忘单
2、数据转换指南
3、使用字符串备忘单
4、数据可视化备忘单
可以从RStudio中选择来选择备忘单Help > Cheatsheets。
填写下面表单即可预约申请免费试听!怕钱不够?可先就业挣钱后再付学费! 怕学不会?助教全程陪读,随时解惑!担心就业?一地学习,可推荐就业!
©2007-2022/ www.aaa-cg.com.cn 北京漫动者数字科技有限公司 备案号: 京ICP备12034770号 监督电话:010-53672995 邮箱:bjaaa@aaaedu.cc

 热门推荐
热门推荐
 UI设计
UI设计
 产品经理
产品经理
 大数据分析
大数据分析
 原画设计
原画设计
 平面设计
平面设计
 新媒体运营
新媒体运营 






