SQL,发音为“ sequel”(或SQL,如果愿意的话),是数据科学家的重要工具。实际上,它可以说是获取数据工作中最重要的语言。在共享单车数据分析的SQL设计中,我们将从入门者的角度深入研究SQL基础知识,以使您入门并掌握这一关键技能。
让我们从回答一个简单的问题开始:
什么是SQL?
SQL代表结构化查询语言。查询语言是一种编程语言,旨在促进从数据库中检索特定信息,而这正是SQL所做的。简而言之,SQL是数据库的语言。
这很重要,因为大多数公司将其数据存储在数据库中。尽管数据库类型很多(例如MySQL,PostgreSQL,Microsoft SQL Server),但是大多数数据库都使用SQL,因此一旦掌握了SQL基础知识,便可以使用其中的任何一个。
即使您打算使用Python之类的另一种语言进行分析,在大多数公司中,您仍可能需要使用SQL从公司的数据库中检索所需的数据。在撰写共享单车数据分析的SQL设计时,仅在美国,Indeed上就列出了80,000多个SQL作业。
因此,让我们开始学习SQL!
(如果您希望通过浏览器进行交互学习,编写和运行SQL查询,则应查看我们的SQL基础课程,该课程免费)
为了避免广告的嫌疑,我们选择国外的一个共享单车来举例子,在共享单车数据分析的SQL设计中,我们将使用自行车共享服务Hubway的数据集,其中包括使用该服务进行的超过150万次旅行的数据。
在开始用SQL编写我们自己的一些查询之前,我们将首先看一下数据库,它们是什么以及为什么使用它们。
如果您想继续,可以在这里下载hubway.db文件(130 MB)。
SQL基础:关系数据库
关系数据库是一种数据库,该数据库存储跨多个表的相关信息,并允许您同时查询多个表中的信息。
通过思考一个例子,更容易理解它是如何工作的。假设您是一家企业,并且想要跟踪销售信息。您可以在Excel中设置一个电子表格,在其中您要跟踪的所有信息都以单独的列显示:订单号,日期,到期金额,装运跟踪号,客户名,客户地址和客户电话号码。

此设置可以很好地跟踪所需的信息,但是当您开始从同一位客户那里获得重复订单时,您会发现他们的姓名,地址和电话号码存储在电子表格的多行中。
随着业务的增长和要跟踪的订单数量的增加,这些冗余数据将占用不必要的空间,并通常会降低销售跟踪系统的效率。您可能还会遇到数据完整性问题。例如,不能保证每个字段都将填充正确的数据类型,或者每次都以完全相同的方式输入名称和地址。
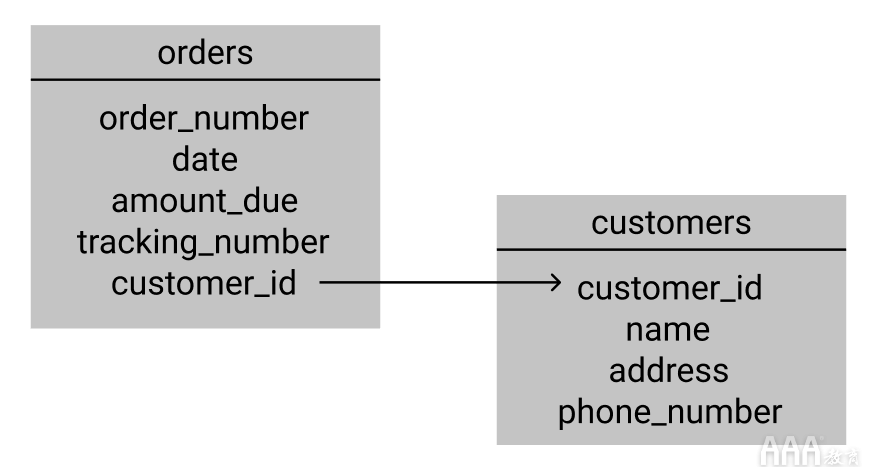
与上图中的关系数据库一样,使用关系数据库可以避免所有这些问题。您可以设置两个表,一个用于订单,一个用于客户。“客户”表将包括每个客户的唯一ID号,以及我们已经跟踪的姓名,地址和电话号码。“订单”表将包括您的订单号,日期,应付金额,跟踪号,并且在每个客户数据项中没有一个单独的字段,而是一个客户ID列。
这使我们能够提取任何给定订单的所有客户信息,但是我们只需要在数据库中存储一次即可,而不必为每个订单再次列出它。
我们的数据集
让我们开始看看我们的数据库。该数据库有两个表,trips和stations。首先,我们只看trips表。它包含以下列:
1)id —用作每次旅行的参考的唯一整数
2)duration —行程时间,以秒为单位
3)start_date —旅行开始的日期和时间
4)start_station—一个整数,与该行开始于的车站的表中的id列相对应stations
5)end_date —旅行结束的日期和时间
6)end_station —行程终点站的“ id”
7)bike_number —旅途中所用自行车的Hubway唯一标识符
8)sub_type—用户的订阅类型。"Registered"对于具有成员资格"Casual"的用户,对于没有成员资格的用户
9)zip_code —用户的邮政编码(仅适用于注册会员)
10)birth_date —用户的出生年份(仅适用于注册会员)
11)gender —用户的性别(仅适用于注册会员)
我们的分析
有了这些信息和我们将很快学习的SQL命令,以下是我们在共享单车数据分析的SQL设计中将尝试回答的一些问题:
1)最长旅行的持续时间是多少?
2)“注册”用户进行了多少次旅行?
3)平均旅行时间是多少?
4)注册用户或临时用户旅行更长吗?
5)大多数旅行中使用哪辆自行车?
6)30岁以上的用户平均旅行时间是多少?
我们将用来回答这些问题的SQL命令是:
1)SELECT
2)WHERE
3)LIMIT
4)ORDER BY
5)GROUP BY
6)AND
7)OR
8)MIN
9)MAX
10)AVG
11)SUM
12)COUNT
安装与设定
就共享单车数据分析的SQL设计而言,我们将使用一个名为SQLite3的数据库系统。从2.5版开始,SQLite已经成为Python的一部分,因此,如果您安装了Python,则几乎肯定也会安装SQLite。如果尚未安装Python和SQLite3库,则可以使用Anaconda轻松进行安装和设置。
使用Python运行我们的SQL代码可以使我们将结果导入到Pandas数据框中,从而更易于以易于阅读的格式显示结果。这也意味着我们可以对从数据库中提取的数据进行进一步的分析和可视化,尽管这超出了共享单车数据分析的SQL设计的范围。
另外,如果我们不想使用或安装Python,则可以从命令行运行SQLite3。只需从SQLite3网页下载“预编译的二进制文件”,然后使用以下代码打开数据库:

在这里,我们只需键入要运行的查询,我们将在终端窗口中看到返回的数据。
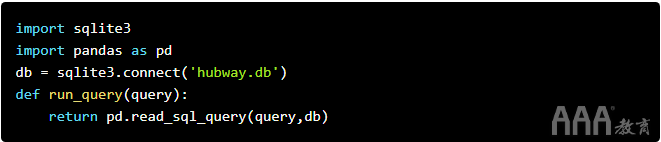
使用终端的另一种方法是通过Python连接到SQLite数据库。这将使我们能够使用Jupyter笔记本,以便我们可以在格式整齐的表中查看查询的结果。
为此,我们将定义一个函数,该函数将查询(存储为字符串)作为输入并将结果显示为格式化的数据框:
当然,我们不必在SQL中使用Python。如果您已经是R程序员,那么我们的R用户SQL基础知识课程将是一个不错的起点。
选择
我们将使用的第一个命令是SELECT。SELECT将几乎是我们编写的每个查询的基础-它告诉数据库我们要查看哪些列。我们既可以按名称指定列(用逗号分隔),也可以使用通配符*返回表中的每一列。
除了要检索的列之外,我们还必须告诉数据库从哪个表获取它们。为此,我们使用关键字,FROM后跟表名。例如,如果我们想看到的start_date,并bike_number在每行trips表中,我们可以使用下面的查询:

在此示例中,我们从SELECT命令开始,以便数据库知道我们希望它为我们找到一些数据。然后,我们告诉数据库我们对start_date和bike_number列感兴趣。最后,我们过去FROM使数据库知道我们要查看的列是trips表的一部分。
编写SQL查询时要意识到的重要一件事是,我们希望每个查询都以分号(;)结尾。并非每个SQL数据库实际上都需要这样做,但是有些确实需要,所以最好养成这种习惯。
限制
开始在Hubway数据库上运行查询之前,我们需要知道的下一个命令是LIMIT。LIMIT只是告诉数据库您希望它返回多少行。
SELECT我们在上一节中查看的查询将为表中的每一行返回所请求的信息trips,但是有时这可能意味着大量数据。我们可能不想要所有这些。相反,如果我们想看到的start_date,并bike_number在数据库中的第一个五年的旅行,我们可以添加LIMIT到我们的查询,如下所示:

我们仅添加了LIMIT命令,然后添加了一个数字,该数字表示我们要返回的行数。在本例中,我们使用5,但您可以将其替换为任何数字,以获取正在处理的项目的适当数据量。
LIMIT在共享单车数据分析的SQL设计中,我们将在Hubway数据库中的查询中使用很多–该trips表包含超过150万行数据,我们当然不需要显示所有数据!
让我们在Hubway数据库上运行第一个查询。首先,我们将查询存储为字符串,然后使用我们先前定义的函数在数据库上运行它。看下面的例子:
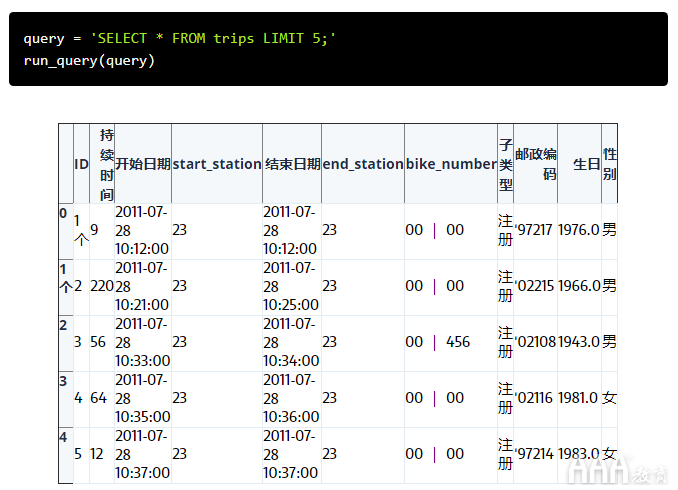
该查询*用作通配符,而不是指定要返回的列。这意味着该SELECT命令已为我们提供了trips表中的每一列。我们还使用该LIMIT函数将输出限制为表的前五行。
您会经常看到人们在查询中使用大写的逗号(这是我们在共享单车数据分析的SQL设计中将遵循的约定),但这主要是优先考虑的问题。大写字母使代码更易于阅读,但实际上丝毫不影响代码的功能。如果您希望使用小写命令编写查询,则查询仍将正确执行。
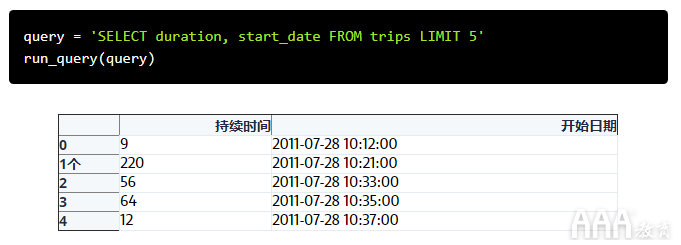
我们前面的示例返回trips表中的每一列。如果只对duration和start_date列感兴趣,则可以按如下所示用列名替换通配符:
订购
在回答第一个问题之前,我们需要知道的最终命令是ORDER BY。此命令使我们可以对给定列上的数据库进行排序。
要使用它,我们只需指定要排序的列的名称。默认情况下,ORDER BY按升序排序。如果我们想指定数据库应该排序的顺序,我们可以添加关键字ASC以升序或DESC降序。
例如,如果我们想将trips表从最短duration到最长排序,我们可以在查询中添加以下行:

有了SELECT,LIMIT和ORDER BY命令之后,我们现在可以尝试回答第一个问题:最长旅行的持续时间是多少?
要回答这个问题,将其分为几个部分并确定我们需要解决每个部分的命令会很有帮助。
首先,我们需要从表的duration列中提取信息trips。然后,要找出最长的行程,我们可以duration按降序对列进行排序。我们可能会通过以下方式提出一个查询,该查询将获取我们正在寻找的信息:
1)使用SELECT检索duration列FROM的trips表
2)使用ORDER BY排序的duration列,并使用DESC关键字来指定要在降序排序
3)用于LIMIT将输出限制为1行
以这种方式使用这些命令将返回持续时间最长的单行,这将为我们提供问题的答案。
需要注意的另一件事-随着查询添加更多命令并变得更加复杂,如果将它们分成多行,您可能会更容易阅读。就像大写一样,这是个人喜好问题。它不会影响代码的运行方式(系统只是从头开始读取代码,直到到达分号为止),但它可以使您的查询更清晰,更易于理解。在Python中,我们可以使用三引号将字符串分隔为多行。
让我们继续运行此查询,找出最长的旅程持续了多长时间。
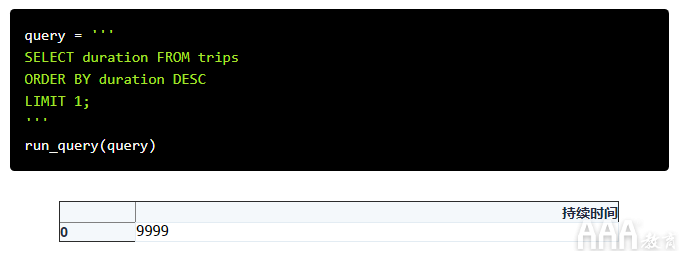
现在我们知道最长的旅程持续了9999秒,或者说是166分钟多一点。但是,最大值为9999时,我们不知道这是否真的是最长行程的长度,或者数据库是否仅设置为允许四位数的数字。
如果确实由数据库缩短了特别长的行程,那么我们可能期望在9999秒处看到很多行程,它们达到了极限。让我们尝试运行与之前相同的查询,但是将调整LIMIT为返回10个最长持续时间,以查看是否为这种情况:
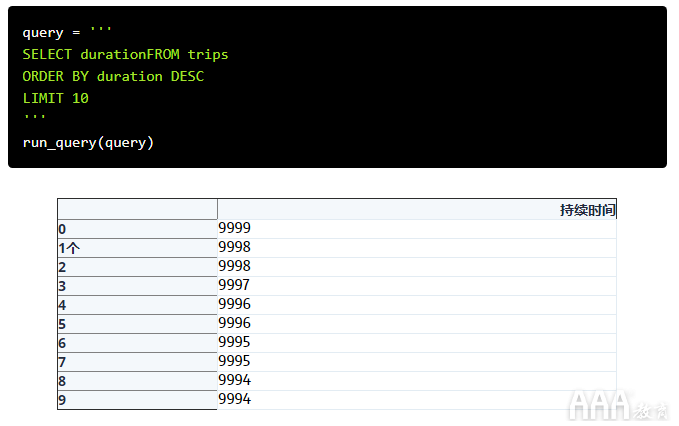
我们在这里看到的是,在9999年并没有一整趟旅行,因此看起来我们并没有切断持续时间的高端,但是仍然很难判断这是否是真正的行程跳闸或最大允许值。
Hubway会为30分钟以上的骑行收取额外费用(某人保持9999秒的自行车将不得不支付25美元的额外费用),因此他们认为4位数字足以追踪大多数骑行是合理的。
哪里
前面的命令非常适合提取特定列的排序信息,但是如果我们要查看数据的特定子集,该怎么办?就是这样WHERE。WHERE命令允许我们使用逻辑运算符指定应返回的行。例如,您可以使用以下命令返回bike的每次旅行B00400:

您还会注意到,我们在此查询中使用引号。那是因为bike_number储存为字串。如果该列包含数字数据类型,则不需要引号。
让我们编写一个查询,该查询WHERE用于返回trips表中每一行的每一列,这些查询的duration时间超过9990秒:

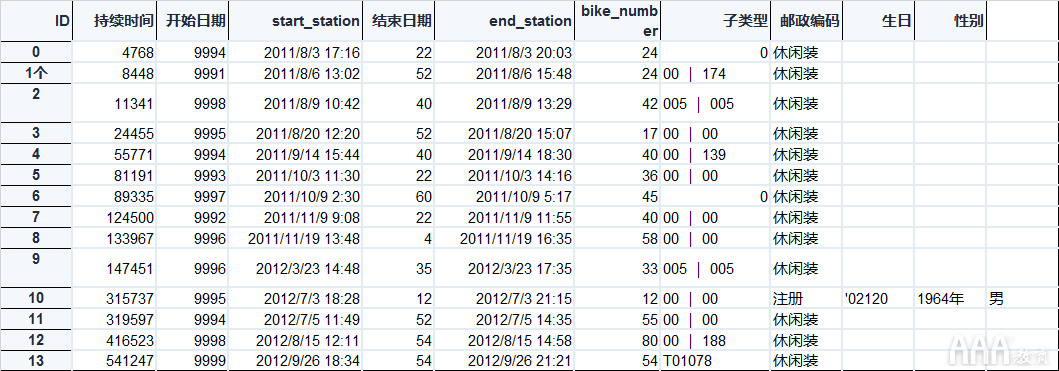
如我们所见,此查询返回了14个不同的行程,每个行程持续9990秒或更长。关于此查询的突出之处是,除一个结果外,所有结果都具有sub_type的"Casual"。也许这表明"Registered"用户更了解长途旅行的额外费用。也许Hubway可以更好地向休闲用户传达其价格结构,以帮助他们避免超额收费。
我们已经知道,即使是SQL的初学者级命令也可以如何帮助我们回答业务问题并在数据中寻找见解。
返回到WHERE,我们也可以WHERE使用AND或在子句中组合多个逻辑测试OR。例如,如果在我们之前的查询中,我们只想返回duration超过9990秒的行程,并且还具有已sub_type注册的行程,则可以AND用来指定这两个条件。
这是另一个个人喜好建议:使用括号分隔每个逻辑测试,如下面的代码块所示。这不是代码正常运行所必需的,但是括号会随着您增加复杂性而使您的查询更容易理解。
现在运行该查询。我们已经知道它只能返回一个结果,因此应该容易检查我们是否正确:
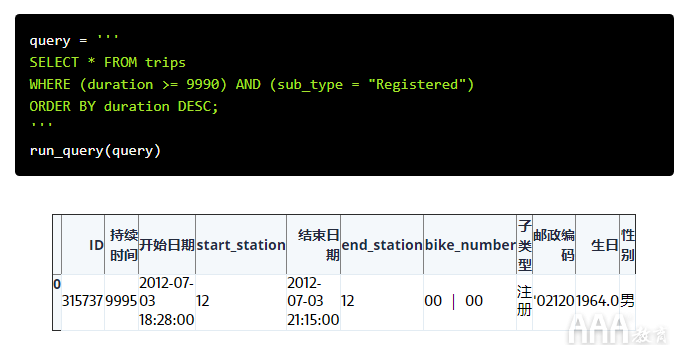
我们在帖子开头提出的下一个问题是“'注册'用户进行了多少次旅行?” 为了回答这个问题,我们可以运行与上面相同的查询,并修改WHERE表达式以返回sub_type等于的所有行,'Registered'然后对它们进行递增计数。
但是,SQL实际上有一个内置命令来为我们进行计数COUNT。
COUNT使我们可以将计算转移到数据库,从而省去了编写额外脚本来计算结果的麻烦。要使用它,我们只需要添加(COUNT(column_name)而不是添加)您想要的列即可SELECT,如下所示:

在这种情况下,我们选择对哪一列进行计数都没有关系,因为每一列都应该有查询中每一行的数据。但是有时查询可能缺少某些行的值(或“空”)。如果不确定一列是否包含空值,则可以COUNT在该id列上运行-该id列永远不会为空,因此我们可以确保计数不会遗漏任何内容。
我们还可以使用COUNT(1)或COUNT(*)来计数查询中的每一行。值得注意的是,有时我们实际上可能想COUNT在具有空值的列上运行。例如,我们可能想知道数据库中有多少行缺少一列的值。
让我们看一个查询来回答我们的问题。我们可以SELECT COUNT(*)用来计算返回的总行数,并WHERE sub_type = "Registered"确保只计算注册用户的旅行次数。
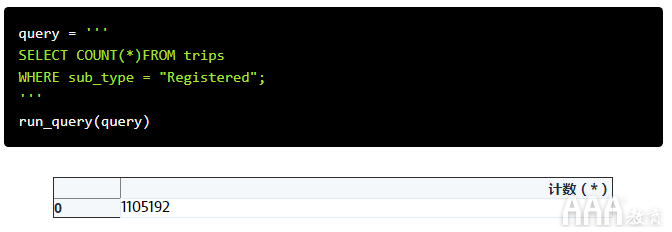
该查询有效,并且已返回我们问题的答案。但是列标题不是特别描述性的。如果其他人看这张桌子,他们将无法理解它的含义。如果我们想使结果更具可读性,可以使用AS别名(或昵称)作为输出。让我们重新运行上一个查询,但给我们的列标题加上别名Total Trips by Registered Users:
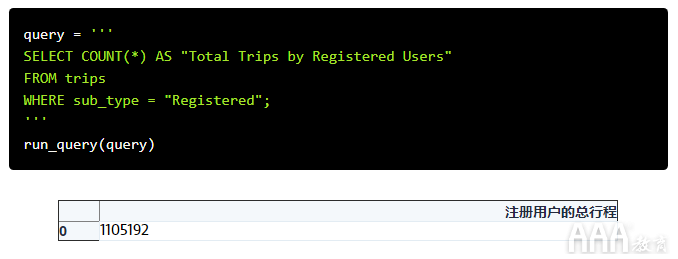
汇总功能
COUNT这不是SQL掌握的唯一数学技巧。我们也可以使用SUM,AVG,MIN和MAX分别返回列的求和,平均值,最小值和最大值。这些与COUNT一起被称为集合函数。
因此,要回答我们的第三个问题,“平均旅行持续时间是多少?” ,我们可以使用列AVG上的函数duration(再次使用AS,为输出列起一个更具描述性的名称):
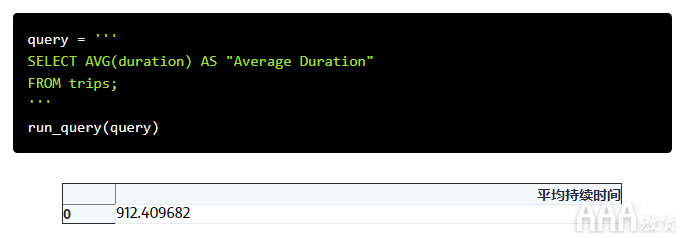
事实证明,平均旅行持续时间是912秒,大约是15分钟。这是有道理的,因为我们知道Hubway会对30分钟以上的行程收取额外费用。该服务是为骑手短途单程旅行而设计的。
接下来的问题是,注册用户或临时用户旅行更长的时间呢?我们已经知道一种解决此问题的方法-我们可以SELECT AVG(duration) FROM trips使用WHERE子句运行两个查询,这些子句将一个限制到"Registered"一个,一个限制到"Casual"用户。
不过,让我们以不同的方式来做。SQL还包括使用GROUP BY命令在单个查询中回答此问题的方法。
通过...分组
GROUP BY 根据特定列的内容将行分为几组,并允许我们在每个组上执行聚合函数。
为了更好地了解其工作原理,让我们看一下该gender专栏。每行可以有三个可能的值一个gender列,"Male","Female"或Null(丢失;我们没有gender对普通用户的数据)。
当使用时GROUP BY,数据库将根据gender列中的值将每一行分成不同的组,就像我们将一副纸牌分成不同的花色一样。我们可以想象制造两堆,所有雄性之一,所有雌性之一。
一旦我们拥有两个独立的堆,数据库将依次对它们中的每一个执行查询中的任何聚合函数。COUNT例如,如果使用,则查询将计算每个堆中的行数,并分别返回每个堆的值。
让我们详细介绍如何编写查询来回答我们的问题,即注册用户或临时用户是否需要更长的行程。
1)与到目前为止的每个查询一样,我们将从SELECT告诉数据库想要查看哪些信息开始。在这种情况下,我们需要sub_type和AVG(duration)。
2)我们还将包括GROUP BY sub_type按订阅类型分离数据,并分别计算注册用户和临时用户的平均值。
当我们将它们放在一起时,代码如下所示:
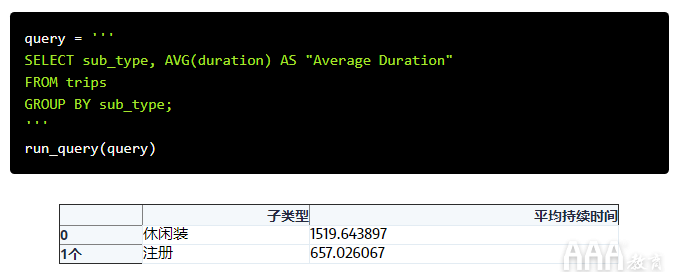
完全不同!平均而言,注册用户的出行时间约为11分钟,而休闲用户每次出行的时间则接近25分钟。注册用户可能会进行更短,更频繁的旅行,这可能是他们上下班的一部分。另一方面,休闲用户每次旅行花费的时间大约是两倍。
休闲用户可能来自人口统计学(例如旅游者),他们更倾向于长途旅行,以确保他们四处逛逛并看到所有景点。一旦我们发现了数据的差异,公司便可以通过多种方式对其进行调查,以更好地了解造成这种情况的原因。
但是,出于共享单车数据分析的SQL设计的目的,让我们继续。我们的下一个问题是旅行次数最多的是哪辆自行车?。我们可以使用非常相似的查询来回答这个问题。看下面的示例,看看是否可以弄清楚每行的内容-我们将逐步进行操作,以便检查是否正确:
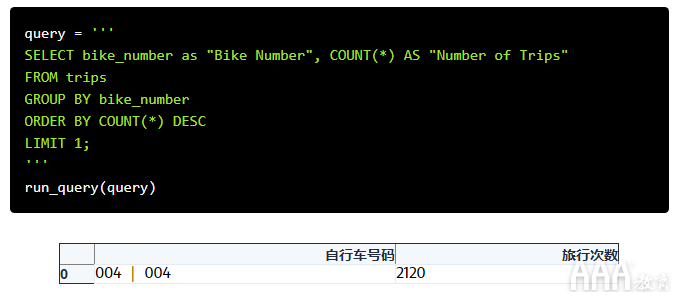
从输出中可以看到,自行车B00490出行最多。让我们来看看如何到达那里:
1)第一行是一个SELECT子句,告诉数据库我们要查看bike_number列和每行的计数。它还AS用于告诉数据库以更有用的名称显示每一列。
2)第二行用于FROM指定我们要查找的数据在trips表中。
3)第三行是开始有些棘手的地方。我们GROUP BY用来告诉第COUNT1行的函数分别计算每个值bike_number。
4)在第四行,我们有一个ORDER BY子句对表格进行降序排序,并确保最常用的自行车在顶部。
5)最后,我们LIMIT将输出限制为第一行,因为我们如何对第四行的数据进行排序,所以我们知道这将是旅行次数最多的自行车。
算术运算符
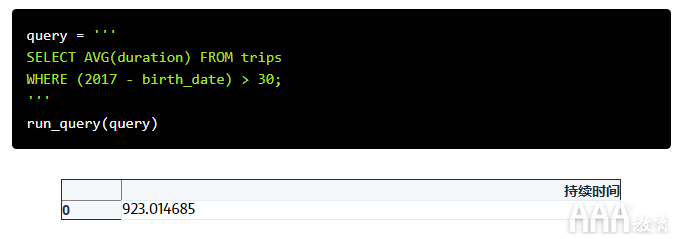
我们的最后一个问题比其他问题更加棘手。我们想知道30岁以上注册会员的平均旅行时间。
我们可以算出30岁以下的人出生的那一年,然后再插入,但是一个更优雅的解决方案是直接在查询中使用算术运算。SQL允许我们使用+,-,*和/在一次对整个列执行运算。
加入
到目前为止,我们一直在研究仅从trips表中提取数据的查询。但是,SQL之所以如此强大是因为它使我们能够从同一查询中的多个表中提取数据。
我们的自行车共享数据库包含第二个表stations。该stations表包含有关Hubway网络中每个站点的信息,并包括id该trips表引用的列。
不过,在开始研究该数据库中的一些实际示例之前,让我们回顾一下较早的假设订单跟踪数据库。在该数据库中,我们有两个表orders和customers,它们通过customer_id列连接。
假设我们要编写一个查询,该查询返回数据库中的每个订单的order_number和name。如果它们都存储在同一个表中,则可以使用以下查询:

不幸的是,order_number列和name列存储在两个不同的表中,因此我们必须添加一些额外的步骤。让我们花一点时间考虑一下数据库在返回所需信息之前需要了解的其他事项:
1)该order_number列在哪个表中?
2)该name列在哪个表中?
3)orders表中的信息如何与表中的信息连接customers?
要回答这些问题中的前两个,我们可以在SELECT命令中包括每列的表名。我们这样做的方法就是简单地写一个表名和列名,用.。分隔。例如,代替SELECT order_number, name我们会写SELECT orders.order_number, customers.name。在此处添加表名称可以通过告诉数据库要查找的表来帮助数据库查找我们要查找的列。
为了告诉数据库orders和customers表如何连接,我们使用JOIN和ON。JOIN指定应该连接的表,并ON指定每个表中的哪些列相关。
我们将使用内部联接,这意味着将仅在中指定的列匹配的地方返回行ON。在此示例中,我们将要JOIN在FROM命令中未包含的任何表上使用。因此,我们可以使用FROM orders INNER JOIN customers或FROM customers INNER JOIN orders。
如前所述,这些表连接customer_id在每个表的列上。因此,我们将要用来ON告诉数据库,这两列引用的是这样的东西:

我们再次使用.来确保数据库知道这些列中的每一个都在哪个表中。因此,当我们将所有这些放在一起时,我们得到的查询如下所示:

该查询将返回数据库中每个订单的订单号以及与每个订单相关联的客户名称。
回到我们的Hubway数据库,我们现在可以编写一些查询以JOIN进行实际操作。
在开始之前,我们应该看一下表中的其余列stations。这是一个查询,向我们显示了前5行,因此我们可以看到stations表的外观:
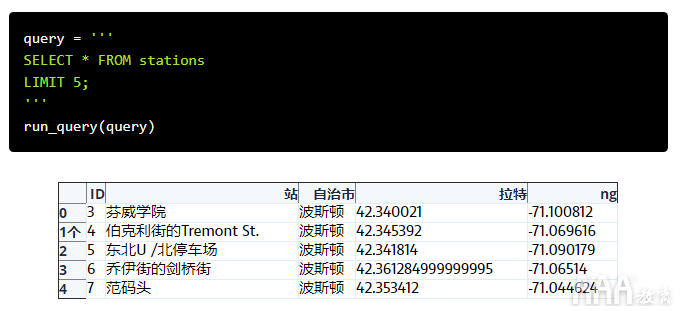
1)id—每个工作站的唯一标识符(对应于表中的start_station和end_station列trips)
2)station —站名
3)municipality —车站所在的城市(波士顿,布鲁克林,剑桥或萨默维尔)
4)lat —车站的纬度
5)lng —车站的经度
6)哪些车站最经常往返?
7)在不同的城市中有多少次旅行开始和结束?
与以前一样,我们将尝试回答数据中的一些问题,从哪个站是最频繁的起点开始?让我们逐步进行操作:
1)首先,我们要使用SELECT返回表中的station列stations和COUNT行数。
2)接下来,我们指定我们想要的表JOIN并告诉数据库连接它们ON的start_station列trips表和id列stations的表。
3)然后我们进入查询的内容-我们在表格中GROUP BY的station列,stations以便我们COUNT将分别计算每个车站的行程次数
4)最后,我们可以ORDER BY我们COUNT并LIMIT输出到结果的管理的数量
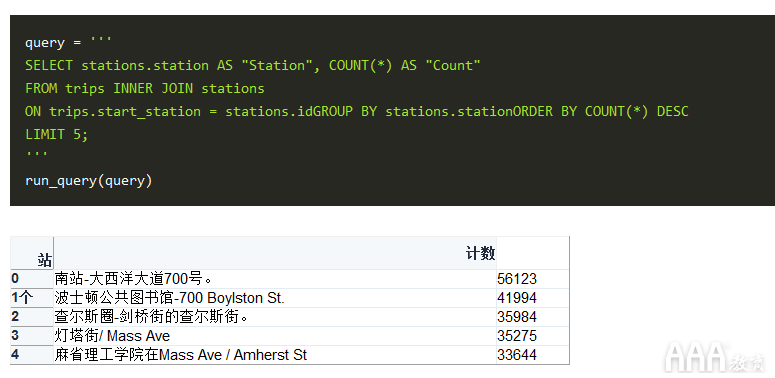
如果您熟悉波士顿,您将了解为什么这些是最受欢迎的电台。南站是该市主要的通勤火车站之一,查尔斯街沿河延伸,靠近一些风景优美的路线,博伊尔斯顿和信标街就在市中心,靠近许多办公大楼。
我们要看的下一个问题是往返最常用的车站是?我们可以使用与以前几乎相同的查询。我们将以相同的方式SELECT使用相同的输出列和JOIN表,但是这次我们将添加一个WHERE子句以限制我们COUNT的行程start_station与相同end_station。
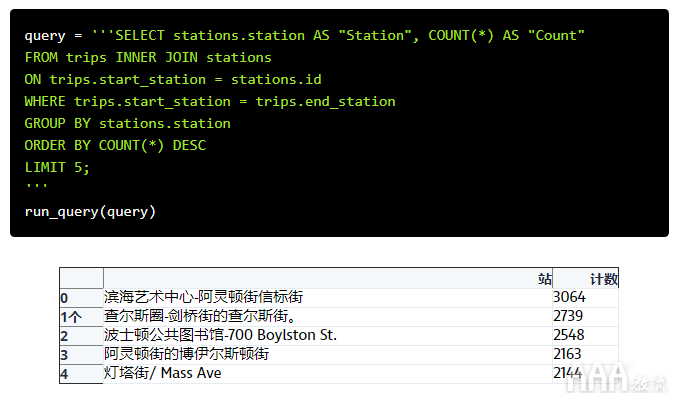
我们可以看到,这些站点的数量与上一个问题相同,但数量要低得多。最繁忙的站点仍然是最繁忙的站点,但是总体而言,较低的站点表明人们通常在使用Hubway自行车从A点到达B点,而不是在返回起点之前先骑自行车一会儿。
这里有一个明显的不同-Esplande并不是我们第一个查询中总体上最繁忙的车站之一,它似乎是往返行程中最繁忙的车站。为什么?好吧,一张图片值一千个字。当然,这看起来像是骑自行车的好地方:
接下来的问题是:在不同的城市开始和结束多少次旅行?这个问题使事情更进一步。我们想知道在不同的地方开始和结束了多少次旅行municipality。为了实现这一目标,我们需要JOIN的trips表到stations表的两倍。一旦ON该start_station列,然后ON在end_station列。

为此,我们必须为该stations表创建一个别名,以便能够区分与关联的start_station数据和与关联的数据end_station。我们可以使用与为各个列创建别名以使其更直观地显示名称的方式完全相同AS。
例如,我们可以使用下面的代码JOIN的stations表到trips使用的“开始”别名表。然后,我们可以将“开始”与我们的列名称结合使用,.以引用来自此特定对象的数据JOIN(而不是第二个,JOIN我们将处理ON该end_station列):
这是我们运行最终查询时的样子。请注意,我们曾经<>表示“不等于”,但!=也可以使用。
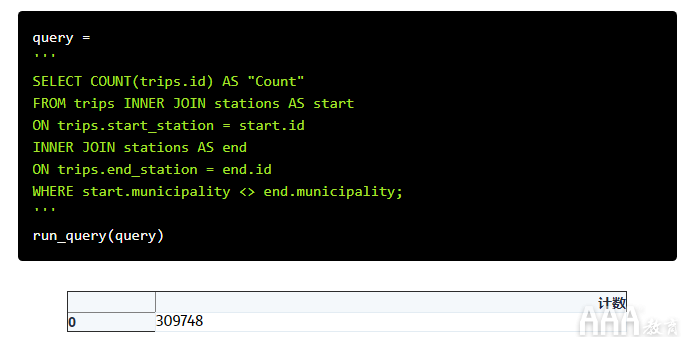
这表明,在150万次旅行中,大约有300,000次(或20%)在与开始的城市不同的地方结束–进一步的证据表明,人们大多使用Hubway自行车进行相对较短的旅行,而不是在城镇之间进行较长的旅行。
如果您已经做到了,那么恭喜!您已经开始掌握SQL的基础知识。我们已经讨论了许多重要的命令,SELECT,LIMIT,WHERE,ORDER BY,GROUP BY和JOIN,以及骨料和算术功能。这些将为您继续SQL之旅提供坚实的基础。
下一步
在完成本入门SQL教程之后,您现在应该能够找到自己感兴趣的数据库并编写查询以提取信息。好的第一步可能是继续使用Hubway数据库,以了解您还能找到什么。以下是您可能想尝试回答的其他一些问题:
1)有多少趟旅程产生了额外的费用(持续时间超过30分钟)?
2)哪辆自行车使用的时间最长?
3)注册用户或临时用户是否往返更多?
4)哪个城市的平均停留时间最长?
如果您想更进一步,请查看我们的交互式SQL课程,该课程涵盖了您从入门到高级SQL所需的一切知识,适用于数据分析师和数据科学家的工作。在数据科学课程页面上的SQL菜单下查找所有交互式SQL课程产品的完整列表。
填写下面表单即可预约申请免费试听!怕钱不够?可先就业挣钱后再付学费! 怕学不会?助教全程陪读,随时解惑!担心就业?一地学习,可推荐就业!
©2007-2022/ www.aaa-cg.com.cn 北京漫动者数字科技有限公司 备案号: 京ICP备12034770号 监督电话:010-53672995 邮箱:bjaaa@aaaedu.cc

 热门推荐
热门推荐
 UI设计
UI设计
 产品经理
产品经理
 大数据分析
大数据分析
 原画设计
原画设计
 平面设计
平面设计
 新媒体运营
新媒体运营 






