通过深度学习的先进技术,自然语言处理取得了令人难以置信的进步。了解这些强大的模型,并发现这些方法与人类水平的理解有多近(或遥远)。

人类有很多感觉,但我们的感官体验通常以视觉为主。考虑到这一点,现代机器学习的先锋由计算机视觉任务主导可能并不奇怪。同样,当人类想要交流或接收信息时,他们使用的最普遍,最自然的途径就是语言。语言可以通过口头和书面单词,手势或某种方式的组合来传达,但是出于大数据分析深度学习在自然语言处理NLP中的应用的目的,我们将重点放在书面单词上(尽管此处的许多课程也与口头演讲重叠)。
多年来,我们已经看到了自然语言处理领域(又名NLP,不要与混淆 的是 NLP)与深层神经网络对正在进行的脚后跟紧跟 深度学习计算机视觉。随着预训练的通用语言模型的出现,我们现在有了将学习转移到具有大规模预训练模型(例如GPT-2,BERT和ELMO)的新任务的方法。这些模型和类似模型在世界范围内都在进行实际工作,无论是日常课程(翻译,转录等),还是在科学知识前沿的发现(例如,根据出版文本[pdf]预测材料科学的发展 ) 。
长期以来,外国人和母语人士对语言的掌握程度一直被认为是博学的个体的标志。一位杰出的作家或一个会说流利的多种语言的人受到高度重视,并有望在其他领域也很聪明。掌握任何语言以达到母语水平的流利程度都非常困难,甚至要赋予其高雅的风格和/或非凡的清晰度。但是,即使是典型的人类熟练程度,也表现出令人难以置信的能力,可以解析复杂的消息,同时可以在上下文,语句,方言以及语言理解的不可动摇的混杂因素(讽刺和讽刺)中破译大量的编码变化。
理解语言仍然是一个难题,尽管在许多领域得到了广泛使用,但是使用机器进行语言理解的挑战仍然存在许多未解决的问题。请考虑以下模糊和奇怪的单词或短语对。表面上,每对成员具有相同的含义,但无疑传达出细微的差别。对于我们许多人而言,唯一的细微差别可能是无视语法和语言的精确性,但是拒绝承认通用含义在大多数情况下会使语言模型看起来很愚蠢。
不在乎=(?)可以少关心
不管=(?)而不管
从字面上看=(?)比喻地
动态的=(?)动态
入门:泛化和转移学习
深度学习在现代上的成功大部分归功于转移学习的效用。转移学习使从业人员可以利用模型先前的培训经验来更快地学习新任务。凭借原始参数计数和先进的深度网络培训状态的计算要求,转移学习对于实践中深度学习的可访问性和效率至关重要。如果您已经熟悉迁移学习的概念,请跳到下一部分,以了解随着时间的推移,深度NLP模型的继承情况。
转移学习是一个微调过程:与从头开始训练整个模型相比,仅对模型的那些特定于任务的部分进行重新训练可以节省时间和精力,同时节省计算和工程资源。这是安德烈·卡帕蒂(Andrej Karpathy),杰里米·霍华德(Jeremy Howard)以及深度学习社区中许多其他人所拥护的“不要成为英雄”的心态。
从根本上讲,转移学习包括保留模型的低级通用组件,而仅重新训练模型中那些专门的部分。在仅重新初始化一些特定于任务的层之后,训练整个预先训练的模型有时也是有利的。
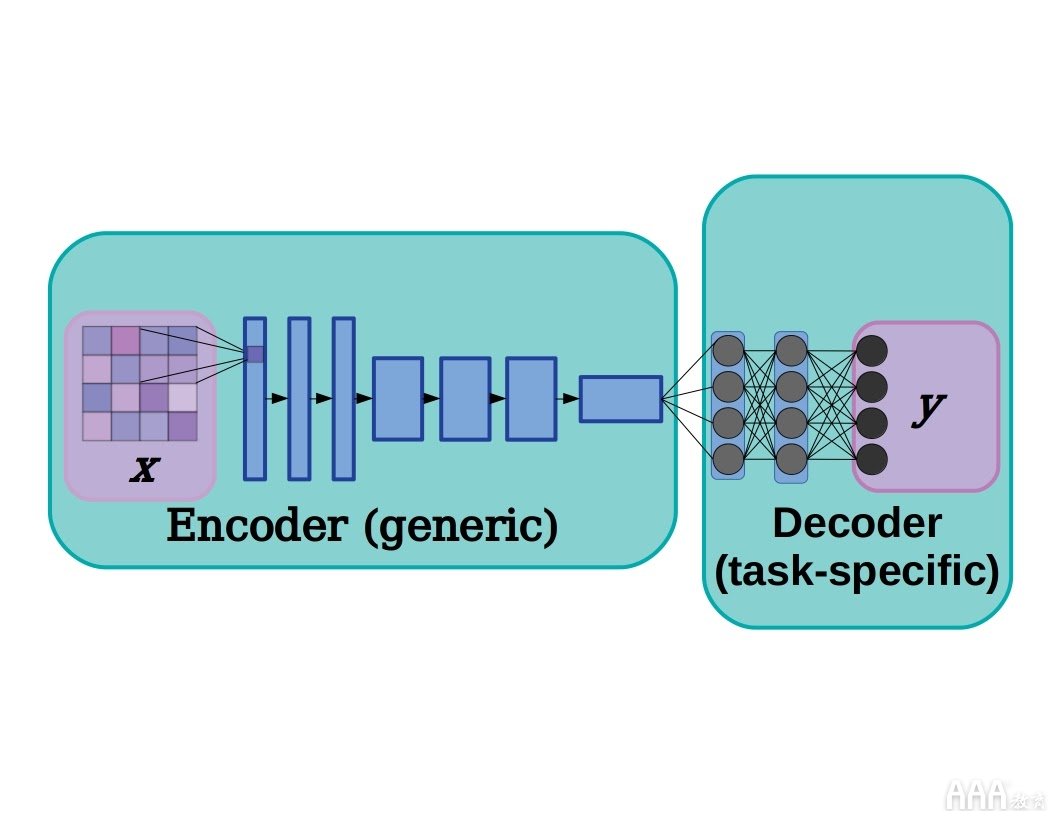
深度神经网络通常可以分为两部分:学习识别低级特征的编码器或特征提取器,以及将这些特征转换为所需输出的解码器。这个卡通示例基于一个用于处理图像的简化网络,编码器由卷积层组成,解码器由几个完全连接的层组成,但是相同的概念也可以轻松应用于自然语言处理。
在深度学习模型中,编码器和解码器之间通常是有区别的,编码器是主要学习提取低级特征的一层堆栈,而解码器是模型的一部分,它将编码器输出的特征转换为分类,像素分割,下一步预测等。采用预先训练的模型并初始化和重新训练新的解码器可以在更少的训练时间内获得最新的性能。这是因为较低层趋于学习图像中最通用的特征,特征(如边缘,点和波纹)(即 图像模型中的Gabor滤波器)。实际上,选择编码器和解码器之间的截止点比科学还重要,但是请参见 Yosinki等。2014年 研究人员在其中量化了要素在不同层的可传递性。
相同的现象可以应用于NLP。可以将经过良好训练的NLP模型训练为通用语言建模任务(根据给定的文本预测下一个单词或字符),可以对许多更具体的任务进行微调。这节省了 从头训练这些模型之一的 大量能源和经济成本,这就是我们拥有杰作的杰作的原因。
这两个示例均建立在OpenAI的GPT-2之上 ,并且这些以及大多数其他生成式NLP项目比其他任何地方都更直接地进入喜剧领域。但是,使用通用的NLP变压器(如GPT-2)进行的转移学习正在迅速从愚蠢的斜坡滑落到不可思议的山谷。在这种情况发生之后,我们将处于可信度的边缘,在这种可信度下,机器学习模型生成的文本可以用作人工编写副本的替代品。有人猜测我们距离实现这些飞跃有多近,但是这可能并不像人们想象的那么重要。NLP模型不一定是莎士比亚,对于某些应用程序而言,有时可能会生成足够好的文本。操作员可以选择或编辑输出以实现所需的输出质量。
在过去十年中,自然语言处理(NLP)取得了长足的进步。一路走来,有很多不同的方法可以提高诸如情感分析和BLEU 机器翻译基准之类的任务的性能 。已经尝试了许多不同的体系结构,其中某些可能更适合给定的任务或硬件约束。在接下来的几节中,我们将研究用于语言建模的深度学习NLP模型的族谱。
递归神经网络
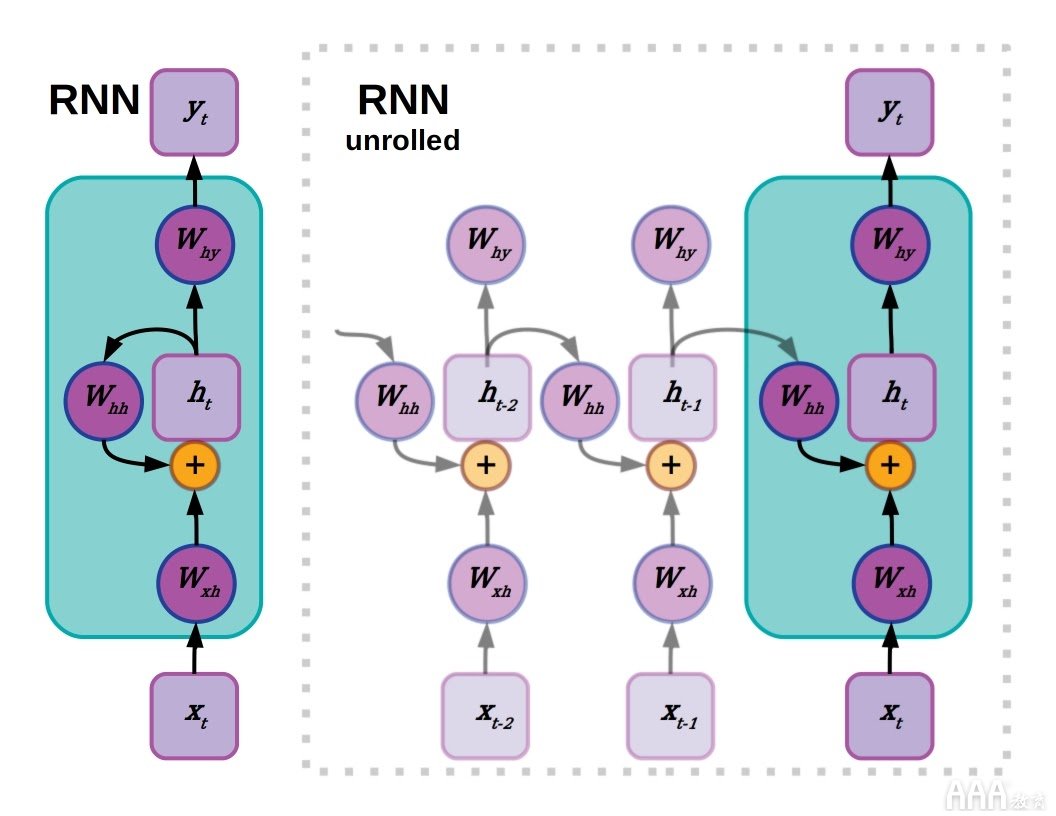
循环神经网络中的一个或多个隐藏层与先前的隐藏层激活有联系。
下面是大数据分析深度学习在自然语言处理NLP中的应用和其他图中图形的关键:
语言是序列数据的一种。与图像不同,它按预定方向一次解析一个块。句子开头的文本可能与后面的元素有重要关系,并且可能需要记住一段文字中更早的概念,以便以后理解信息。有意义的是,语言的机器学习模型应该具有某种内存,而递归神经网络(RNN)则通过与先前状态的连接来实现内存。在给定时间状态下,隐藏层中的激活取决于之前一步的激活,这又取决于它们之前的值,依此类推,直到语言序列开始为止。
由于输入/输出数据之间的依存关系可以追溯到序列的开头,因此网络实际上非常深。这可以通过将网络“展开”到其顺序深度来可视化,从而揭示导致给定输出的操作链。这是个非常 明显的版本中的 消失梯度问题。因为在每个先前的时间步长中,用于为错误分配功劳的坡度乘以小于1.0的数字,所以训练信号会不断衰减,并且早期权重的训练信号会变得非常小。解决RNN中长期依赖关系的困难的一种解决方法是完全没有。
储层计算和回波状态网络
回波状态网络就像RNN,但具有使用固定的未经训练的权重的循环连接。网络的此固定部分通常称为存储库。
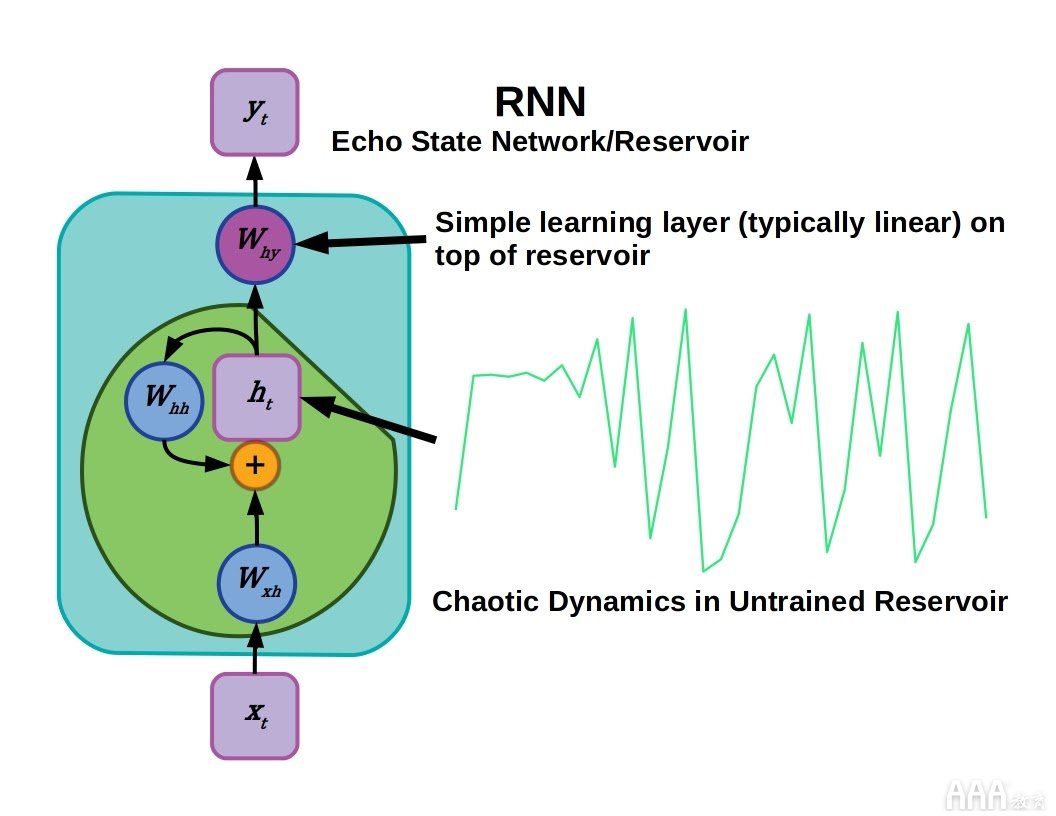
回声状态网络是具有固定循环连接的RNN的子类。使用静态递归连接避免了用逐渐消失的梯度训练它们的困难,并且在RNN的许多早期应用中, 回波状态网络的 性能优于经过反向传播训练的RNN。一个简单的学习层,通常是一个完全连接的线性层,可以分析储层的动态输出。这使得训练网络变得更加容易,并且必须初始化储层以使其具有复杂且持续但受限的输出。
回波状态网络具有混沌特性,因为早期输入可能对以后的储层状态产生长期影响。因此,回波状态网络的功效归因于“内核技巧”(输入被非线性转换为高维特征空间,可以在其中线性分离输入)和混乱。实际上,这可以通过定义具有随机权重的稀疏循环连接层来实现。
回声状态网络和储层计算在很大程度上已被其他方法所取代,但事实证明,它们避免消失的梯度问题在某些语言建模任务(如学习语法 或 语音识别)中很有用 。但是,在使NLP转移学习成为可能的广义语言建模中,储层计算从未产生太大影响。
LSTM和门控RNN
长期短期记忆引入了门,以选择性地将激活保持在所谓的单元状态。
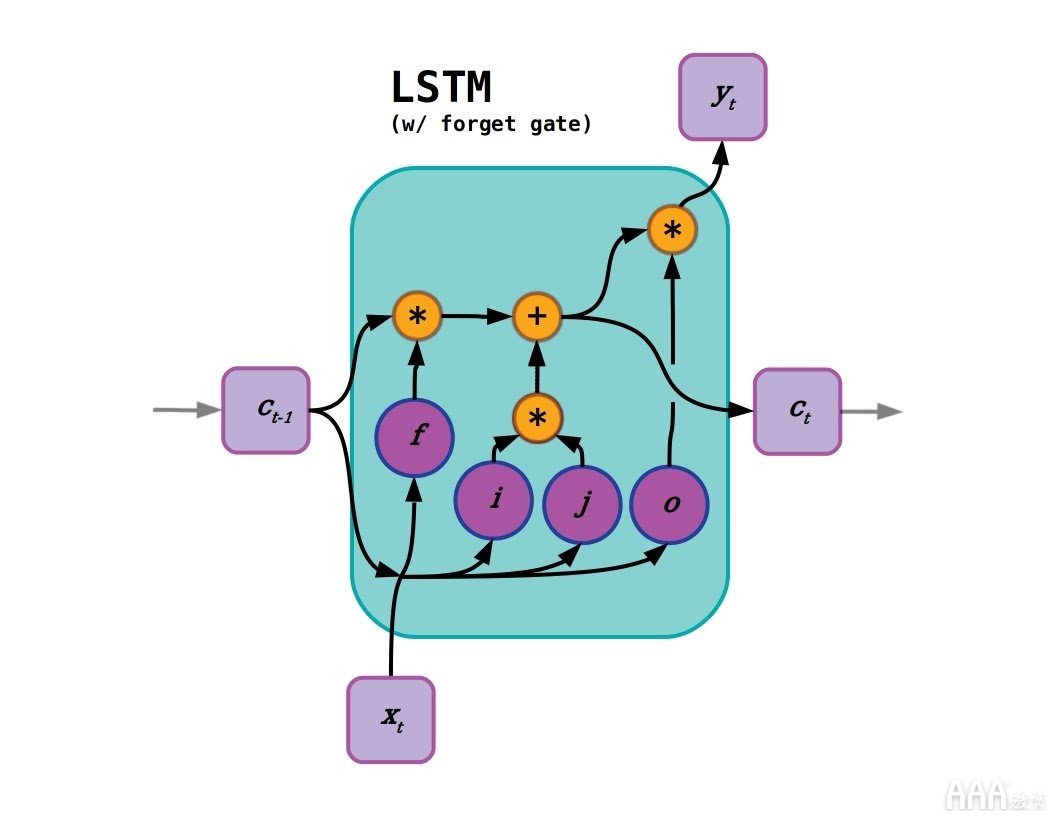
LSTM由Sepp Hochreiter和JürgenSchmidhuber [pdf]于1997年发明,旨在 使用“恒定误差轮播”或CEC解决消失的梯度问题。CEC是一个持久的门控细胞状态,周围是非线性神经层,这些神经层打开和关闭“门”(使用S形激活函数之类的值在0和1之间压缩)。这些非线性层选择应将哪些信息合并到单元状态激活中,并确定传递给输出层的内容。单元状态层本身不具有激活功能,因此,当其值以接近1.0的门值从一个时间步长传递到另一个时间步长时,渐变可以在输入序列中跨很长的距离完整地向后流动。已经有了很多的发展和 新版本适用于改进培训,简化参数计数并应用于新领域的LSTM。这些改进中最有用的方法之一是Gers等人开发的忘记门 。在2000年 (如图所示),如此之多,以至于带有遗忘门的LSTM通常被认为是“标准” LSTM。
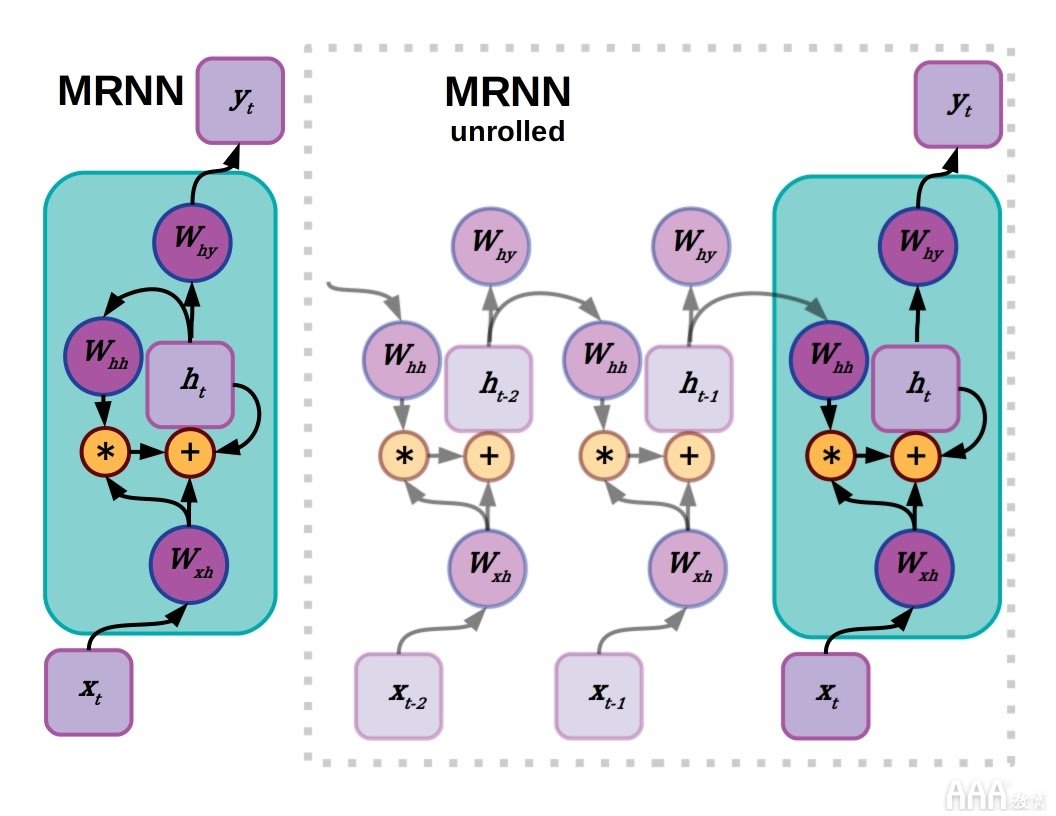
门控或乘法RNN对来自最后一个隐藏状态的输出使用逐个元素的乘法运算,以确定在当前时间步将合并到新的隐藏状态中的内容。
门控或乘法RNN(MRNN)与LSTM非常相似,尽管不太复杂。像LSTM一样,MRNN使用乘法运算来控制网络的最后隐藏状态,并且门限值由接收来自输入数据的神经层确定。Sutskever 等人在2011年将MRNN用于字符级语言建模 。 [ pdf ]并扩展到Chung等人在更深的MRNN(门控反馈RNN)中跨深度选通 。 在2015年。也许因为它们更简单,所以在某些语言建模方案上,MRNN和门控反馈RNN可以胜过LSTM,具体取决于谁来处理它们。
带有遗忘门的LSTM已成为各种引人注目的自然语言处理模型的基础,其中包括OpenAI的“ 无监督情感神经元 ”(论文),以及 2016年百度神经机器翻译模型的性能大幅提升。在通过无监督情感神经元模型进行转移学习的演示之后,塞巴斯蒂安·鲁德(Sebastian Ruder)和杰里米·霍华德(Jeremy Howard)开发了无监督语言模型用于文本分类的微调 (ULM-FiT),该方法利用预训练来获得最新的性能。六个特定的文本分类数据集。
尽管ULM-FiT和Unsupervised Sentiment Neuron不存在,但百度基于LSTM的翻译网络改进的关键部分是注意力的广泛应用,不仅是工程学上的关注,还包括学习机器学习中特定部分的特定机器学习概念。输入数据。对NLP模型的关注是一个很强大的想法,它导致了下一代语言模型的发展,并且可以说是NLP中当前转移学习的功效的原因。
输入变压器
变压器模型中使用的注意机制概念的图形描述来自“注意就是您所需要的”。在序列的给定点上,对于每个数据向量,权重矩阵会生成键,查询和值张量。注意机制使用键和查询向量对值向量进行加权,该值向量将与其他所有键,查询,值集一起受到softmax激活,并求和以产生到下一层的输入。
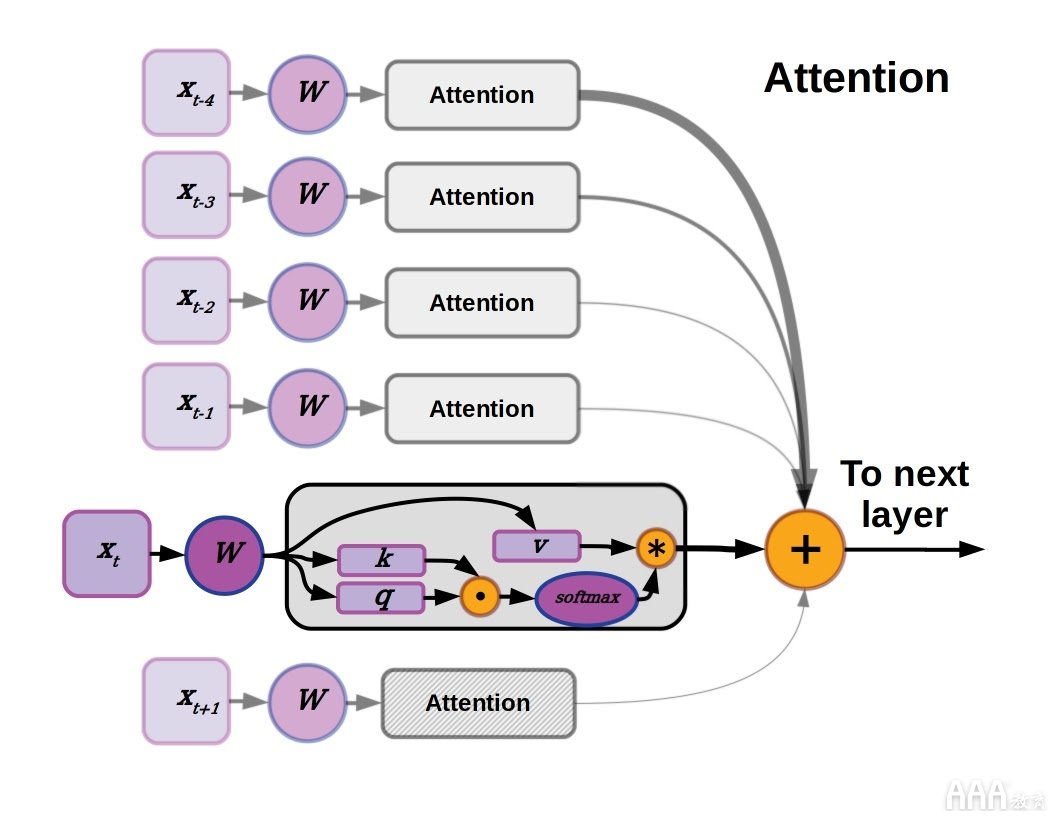
诸如百度的2016 NMT 网络之类的语言模型中使用的注意力机制运行得很好,而在机器学习硬件加速器变得足够强大的时候,导致开发人员提出了一个问题:“如果我们仅使用注意力一个人呢?” 众所周知,答案是关注是实现最新的NLP模型所需的全部(这是 介绍仅关注模型体系结构的论文的名称)。
这些模型称为转换器,与LSTM和其他RNN不同,转换器同时考虑整个序列。他们学会使用注意力来加权输入文本序列中每个点的影响。上图显示了原始Transformer模型使用的注意力机制的简单解释,但是可以从 Jay Alammar 的论文或此博客文章中获得更深入的解释 。
与同时连接的模型不同,同时考虑整个序列似乎将模型限制为只能解析固定长度的序列。但是,转换器使用位置编码(在原始的Transformer中,它基于正弦嵌入矢量),可以方便地以可变的输入序列长度进行正向传递。变压器架构的一次性方法确实带来了严格的内存需求,但是在高端现代硬件上进行培训并简化内存是高效的,并且变压器的计算需求处于当前和该领域最新发展的最前沿。
NLP中深层神经网络的结论和警告
在过去的两到三年中,Deep NLP确实已经成为自己的一员,并且它已经开始有效地扩展到应用程序之外的机器翻译和愚蠢的文本生成领域。NLP的发展继续追随计算机视觉的象征性脚步,不幸的是,其中包括许多我们以前所见过的相同的失误,旅行和绊脚石。
其中一个最紧迫的挑战 是“聪明汉斯效应”,20世纪初的著名表演的马而得名。简而言之, 汉斯 是一匹德国马,作为算术天赋的马在公众面前展出,能够回答有关日期和计数的问题。实际上,他反而是他的教练威廉·冯·奥斯汀(Wilhelm von Osten)解释潜意识线索的专家。在机器学习中,“聪明汉斯”效应是指通过学习训练数据集中的虚假相关性来获得令人印象深刻但最终无用的性能的模型。
例子包括根据识别出 病情较重的医院所使用的机器的类型在X射线中对肺炎进行分类,通过重复最后提到的名字来回答有关文本中描述的人的问题 以及 现代 颅相学。尽管大多数NLP项目在无法正常工作时只会产生错误的喜剧(例如,上述配方和地牢生成器),但缺乏对NLP和其他机器学习模型如何分解的理解,为现代伪科学的论证铺平了道路。以及相应的不良政策。这对业务也不利。想象一下,花费数千或数百万美元来开发支持NLP的服装店,该服装店将返回对无条纹衬衫结果的搜索查询,例如无条纹 Github回购衬衫中的结果。
显然,尽管最近的进步使深层自然语言处理更加有效和易于使用,但在展示任何与人类理解或综合相近的东西之前,该领域还有很长的路要走。尽管存在缺陷(没有Cortana,没有人希望您将所有话语都路由到Edge浏览器上的Internet搜索中),但是NLP是当今广泛使用的许多产品和工具的基础。直接符合NLP的缺点,对系统严格评估语言模型的需求从未如此清晰。显然,不仅要改进模型和数据集,而且还要以有益的方式打破这些模型,这是重要的工作。
填写下面表单即可预约申请免费试听!怕钱不够?可先就业挣钱后再付学费! 怕学不会?助教全程陪读,随时解惑!担心就业?一地学习,可推荐就业!
©2007-2022/ www.aaa-cg.com.cn 北京漫动者数字科技有限公司 备案号: 京ICP备12034770号 监督电话:010-53672995 邮箱:bjaaa@aaaedu.cc

 热门推荐
热门推荐
 UI设计
UI设计
 产品经理
产品经理
 大数据分析
大数据分析
 原画设计
原画设计
 平面设计
平面设计
 新媒体运营
新媒体运营 






