在大数据分析如何使用pandas进行时间序列分析中,我们将学习pandas库中功能强大的时间序列工具。
pandas最初是为金融时间序列(例如每日股票市场价格)开发的,其强大而灵活的数据结构可应用于任何领域的时间序列数据,包括商业,科学,工程,公共卫生等。使用这些工具,您可以轻松地以任何粒度级别组织,转换,分析和可视化数据-在感兴趣的特定时间段检查详细信息,并缩小以探索不同时间范围的变化,例如每月或每年的汇总模式和长期趋势。
在最广义的定义中,时间序列是在不同时间点测量值的任何数据集。许多时间序列以特定的频率均匀地间隔开,例如每小时的天气预报,每天的网站访问次数或每月的销售总额。时间序列也可以是不规则的间隔和零星的,例如,计算机系统的事件日志中的时间戳数据或911紧急呼叫的历史记录。pandas时间序列工具同样适用于两种时间序列。
大数据分析如何使用pandas进行时间序列分析将主要关注时间序列分析的数据处理和可视化方面。使用能源数据的时间序列,我们将看到基于时间的索引编制,重采样和滚动窗口之类的技术如何帮助我们探索电力需求和可再生能源供应随时间的变化。我们将涵盖以下主题:
1)数据集:开放式电源系统数据
2)时间序列数据结构
3)基于时间的索引
4)可视化时间序列数据
5)季节性
6)频率
7)重采样
8)卷帘窗
9)发展趋势
我们将使用Python 3.6,pandas,matplotlib和seaborn。为了充分利用大数据分析如何使用pandas进行时间序列分析,您需要熟悉pandas和matplotlib的基础知识。
还不在那里吗?使用我们的Python数据科学基础知识和中级课程来建立您的基础Python技能。
数据集:开放式电源系统数据
在大数据分析如何使用pandas进行时间序列分析中,我们将使用德国的开放电源系统数据(OPSD)的每日时间序列,该数据近年来已在迅速扩展其可再生能源的生产。数据集包括2006-2017年全国范围的用电量,风力发电和太阳能发电总量。您可以在此处下载数据。
电力生产和消耗报告为千兆瓦时(GWh)的每日总计。数据文件的列为:
1)Date—日期(yyyy-mm-dd格式)
2)Consumption —用电量(GWh)
3)Wind — GWh中的风力发电
4)Solar — GWh中的太阳能发电
5)Wind+Solar —风电和太阳能发电量的总和
我们将使用pandas时间序列工具来回答以下问题,以探索德国的电力消耗和生产随时间的变化:
1)通常什么时候耗电量最高和最低?
2)风力和太阳能发电量会随着季节的变化而变化吗?
3)电力消耗,太阳能和风能的长期趋势是什么?
4)风能和太阳能发电与电能消耗如何比较,该比率随时间变化如何?
时间序列数据结构
在深入研究OPSD数据之前,让我们简要介绍一下用于处理日期和时间的主要pandas数据结构。在pandas中,单个时间点表示为Timestamp。我们可以使用该to_datetime()函数从各种日期/时间格式的字符串中创建时间戳。让我们导入pandas并将一些日期和时间转换为时间戳。
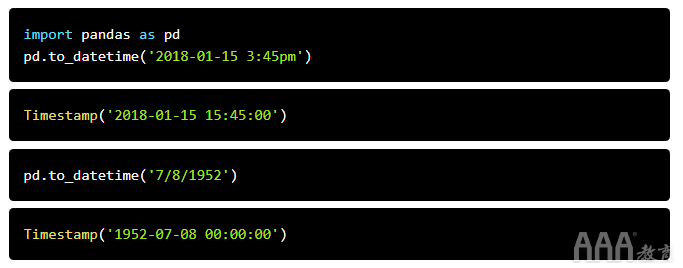
如我们所见,to_datetime()将根据输入自动推断日期/时间格式。在上面的示例中,不明确的日期'7/8/1952'假定为月/日/年,并解释为1952年7月8日。或者,我们可以使用dayfirst参数告诉pandas将日期解释为1952年8月7日。

如果我们提供字符串列表或字符串数组作为的输入to_datetime(),则它将在DatetimeIndex对象中返回日期/时间值的序列,该对象是支持大部分pandas时间序列功能的核心数据结构。

在上面的DatetimeIndex中,数据类型datetime64[ns]指示基础数据以64纳比特(ns)为单位存储为-bit整数。这种数据结构允许pandas紧凑地存储大的日期/时间值序列,并使用NumPy datetime64数组有效地执行矢量化操作。
如果我们要处理所有具有相同日期/时间格式的字符串序列,则可以使用format参数显式指定它。对于非常大的数据集,to_datetime()与默认行为相比,默认行为是针对每个单独的字符串分别推断格式,因此可以大大提高性能。任何的格式代码从strftime()和strptime()在Python的功能内置日期时间模块都可以使用。下面的示例使用格式代码%m(数字月份),%d(月份的日期)和%y(两位数字的年份)指定格式。

除了代表各个时间点的Timestamp和DatetimeIndex对象外,pandas还包括代表持续时间(例如125秒)和时间段(例如2018年11月)的数据结构。有关这些数据结构的更多信息,请点击此处。在大数据分析如何使用pandas进行时间序列分析中,我们将使用DatetimeIndexes,这是pandas时间序列最常见的数据结构。
创建时间序列DataFrame
为了处理pandas中的时间序列数据,我们使用DatetimeIndex作为DataFrame(或Series)的索引。让我们看看如何使用我们的OPSD数据集执行此操作。首先,我们使用该read_csv()函数将数据读取到DataFrame中,然后显示其形状。
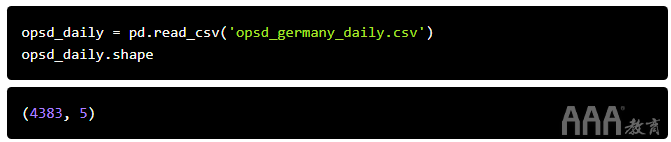
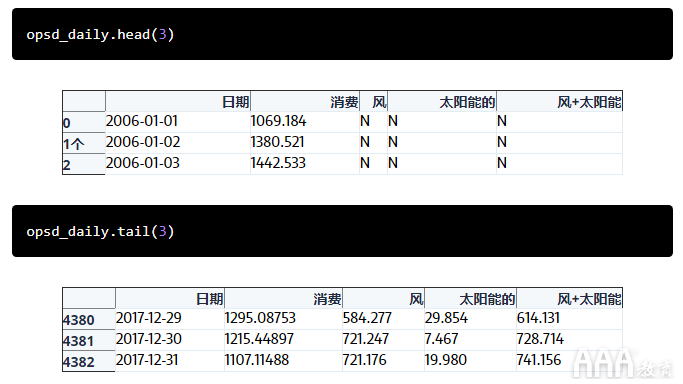
DataFrame有4383行,涵盖从2006年1月1日到2017年12月31日的时间。要查看数据的样子,我们使用head()和tail()方法显示前三行和后三行。
接下来,让我们检查每一列的数据类型。

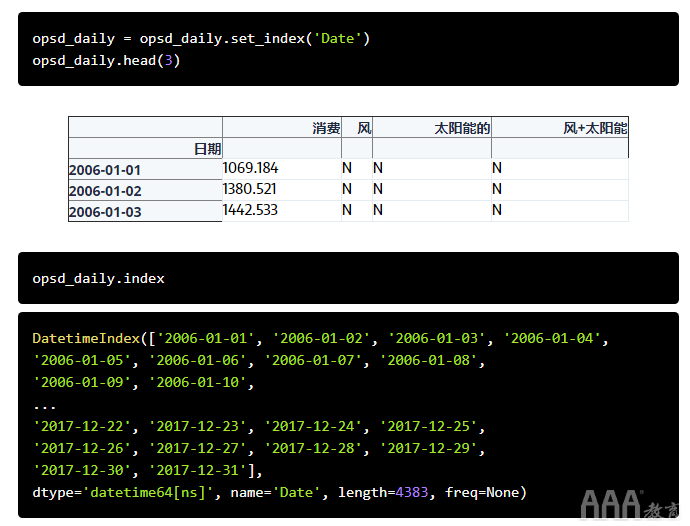
现在,该Date列是正确的数据类型,让我们将其设置为DataFrame的索引。
另外,我们可以使用函数的index_col和parse_dates参数将以上步骤合并为一行read_csv()。这通常是一个有用的快捷方式。

现在,我们的DataFrame索引是DatetimeIndex,我们可以使用所有pandas基于时间的强大索引来处理和分析我们的数据,这将在以下部分中看到。
所述DatetimeIndex的另一个有用的方面是,单独的日期/时间的部件都可用作为属性如year,month,day,等。让我们在中添加更多列opsd_daily,其中包含年,月和周日的名称。
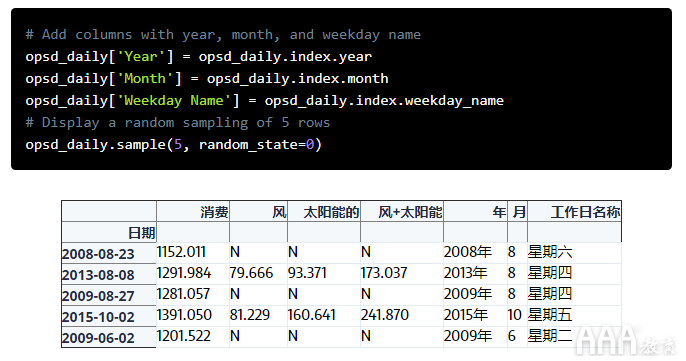
基于时间的索引
大pandas时间序列的最强大和便捷的功能之一是基于时间的索引编制-使用日期和时间直观地组织和访问我们的数据。使用基于时间的索引,我们可以使用日期/时间格式的字符串来通过loc访问器在DataFrame中选择数据。索引的工作方式类似于使用的标准基于标签的索引loc,但有一些附加功能。
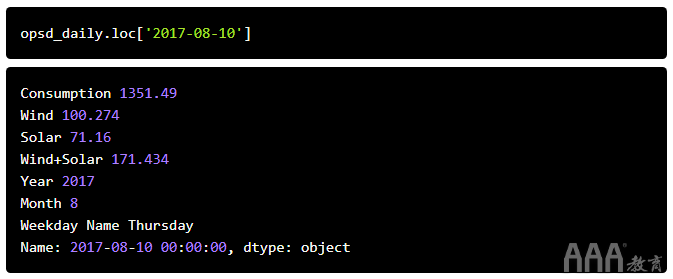
例如,我们可以使用诸如的字符串选择一天的数据'2017-08-10'。
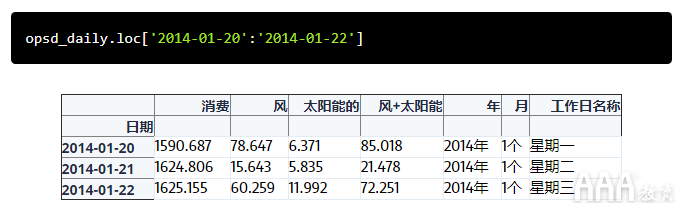
我们还可以选择一片天,例如'2014-01-20':'2014-01-22'。与使用进行基于标签的常规索引一样loc,切片包含两个端点。
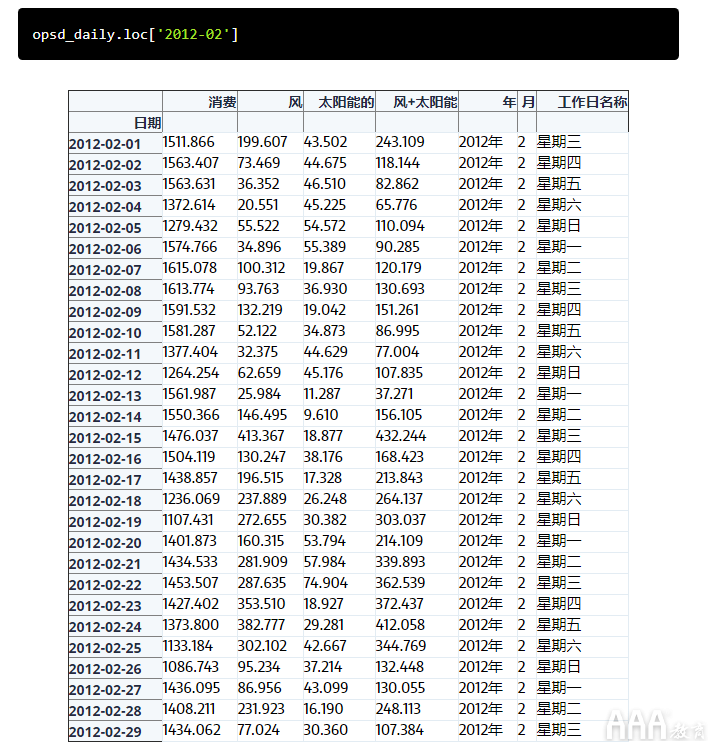
大pandas时间序列的另一个非常方便的功能是部分字符串索引,我们可以在其中选择部分匹配给定字符串的所有日期/时间。例如,我们可以使用选择2006年全年opsd_daily.loc['2006'],或2012年2月选择整个月opsd_daily.loc['2012-02']。
可视化时间序列数据
使用pandas和matplotlib,我们可以轻松地可视化时间序列数据。在本节中,我们将介绍一些示例和一些有用的自定义时序图。首先,让我们导入matplotlib。

我们将对绘图使用seaborn样式,然后将默认图形大小调整为适合时间序列绘图的形状。

让我们使用DataFrame的plot()方法创建德国每日用电量的全时序列的线图。
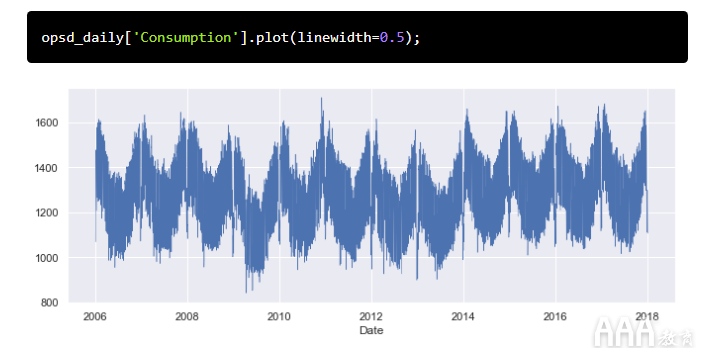
我们可以看到,该plot()方法为x轴选择了很好的刻度位置(每两年)和标签(年份),这很有用。但是,由于数据点太多,因此线图比较拥挤且难以读取。让我们将数据绘制为点,然后查看Solar和Wind时间序列。

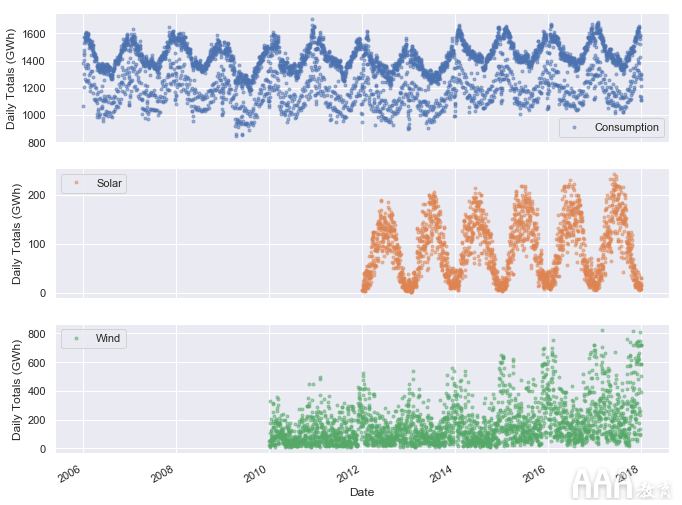
我们已经可以看到一些有趣的模式:
1)电力消耗在冬季最高,大概是由于电加热和照明使用增加,在夏季最低。
2)电力消耗似乎分为两类:一个簇的振荡中心大约在1400 GWh左右,另一个簇的数据点越来越少,而散射点大约在1150 GWh左右。我们可能会猜测这些集群与工作日和周末相对应,我们将在短期内对此进行进一步调查。
3)夏季的太阳能产量最高,而阳光最多,而冬季则最低。
4)风力发电在冬季最高,大概是由于强风和更频繁的风暴,而在夏季最低。
5)多年来,风电生产似乎呈强劲增长趋势。
这三个时间序列都清楚地显示出周期性(在时间序列分析中通常称为季节性),其中,模式会以规则的时间间隔一次又一次地重复。的Consumption,Solar和Wind高低值之间的时间序列上的振荡,每年的时间尺度,在天气在过去一年中季节的变化相对应的。但是,一般而言,季节性不必与气象季节相对应。例如,零售销售数据通常表现出每年的季节性,在11月和12月,直到假期之前,销售都有所增加。
季节性也可能在其他时间范围内发生。上图显示德国的用电量每周可能有一些季节性,与工作日和周末相对应。让我们绘制一年中的时间序列,以进行进一步调查。
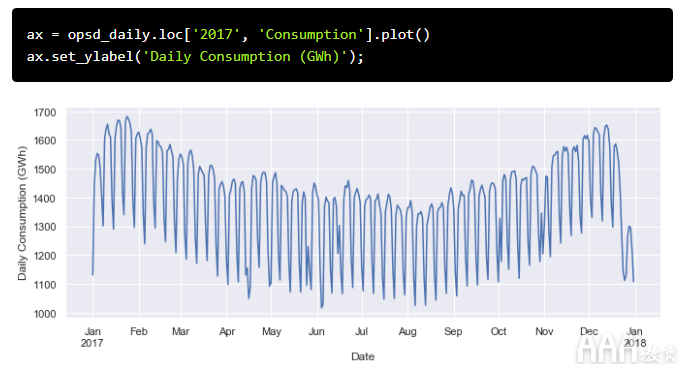
现在我们可以清楚地看到每周的波动。在这种粒度级别上变得显而易见的另一个有趣功能是1月初和12月下旬假期期间的用电量急剧下降。
让我们进一步放大,看看一月和二月。

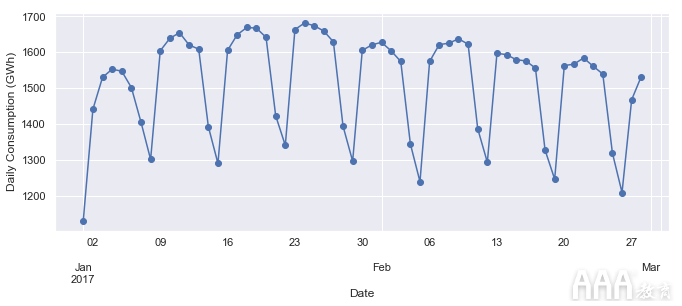
正如我们所怀疑的,平日的消费最高,而周末的最低。
自定义时间序列图
为了更好地直观显示上图中每周的每周用电量季节性变化,最好在每周的时间范围内(而不是在每个月的第一天)使用垂直网格线。我们可以使用matplotlib.dates自定义我们的情节,因此让我们导入该模块。

由于日期/时间刻度在matplotlib.dates中的处理方式与DataFrame的plot()方法相比有所不同,因此让我们直接在matplotlib中创建绘图。然后,我们使用mdates.WeekdayLocator()和mdates.MONDAY将x轴刻度设置为每周的第一个星期一。我们还使用前面看到mdates.DateFormatter()的格式代码来改进刻度标签的格式。
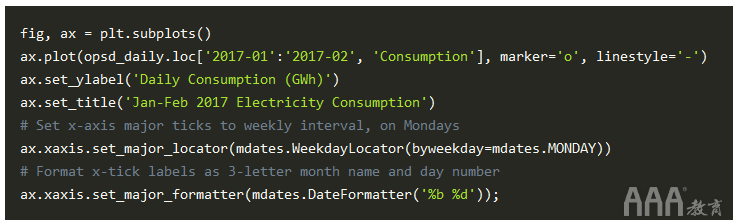
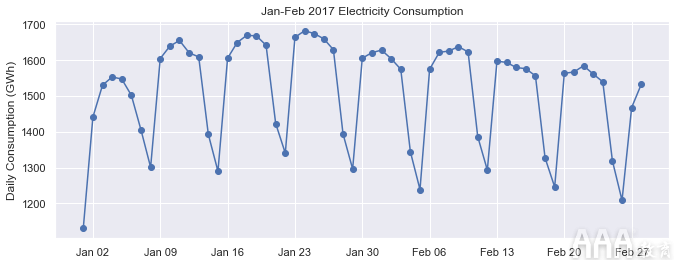
现在,我们在每个星期一都有垂直网格线和格式良好的刻度标签,因此我们可以轻松分辨出哪几天是工作日和周末。
还有许多其他方式可以使时间序列可视化,具体取决于您尝试探索的模式-散点图,热图,直方图等。在以下各节中,我们将看到其他可视化示例,包括以某种方式转换的时间序列数据的可视化,例如聚合或平滑的数据。
季节性
接下来,让我们用箱形图进一步探索数据的季节性,使用seaborn boxplot()函数将数据按不同时间段分组并显示每组的分布。我们将首先按月对数据进行分组,以可视化年度季节性。

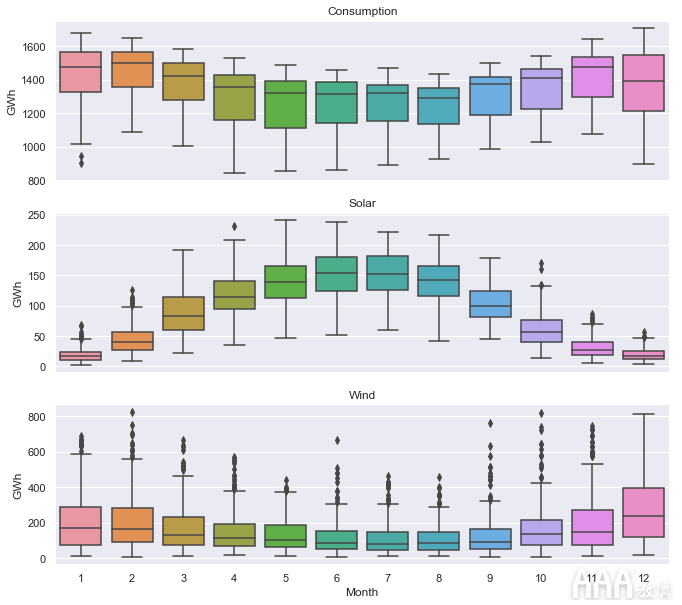
这些箱形图确认了我们在较早的图中看到的年度季节性,并提供了其他一些见解:
1)尽管冬季的用电量通常较高,夏季较低,但是与11月和2月相比,12月和1月的四分位数中位数和下四分位数较低,这可能是由于商家在节假日关闭。我们在2017年的时间序列中看到了这一点,箱形图证实了这是多年来一致的模式。
2)虽然太阳能和风能生产均显示每年的季节性,但风能分布却有更多异常值,反映了暴风雨和其他瞬态天气条件下偶尔出现的极端风速的影响。
接下来,让我们按星期几分组用电时间序列,以探讨每周的季节性。
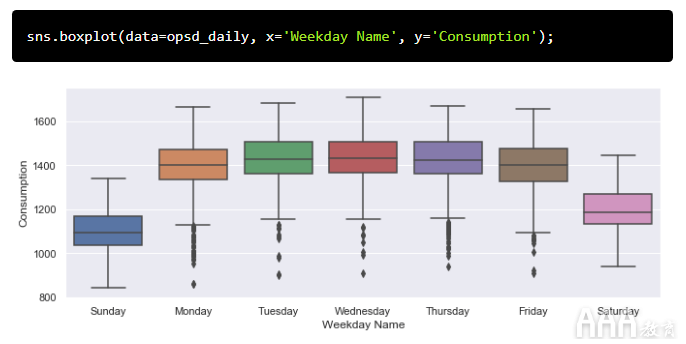
不出所料,工作日的用电量明显高于周末。工作日的异常值较低可能是在假日期间。
本节简要介绍了时间序列的季节性。稍后我们将看到,对数据应用滚动窗口还可以帮助可视化不同时间范围内的季节性。其他用于分析季节性的技术包括自相关图,该图绘制了时间序列与自身在不同时间滞后的相关系数。
具有较强季节性的时间序列通常可以用将信号分解为季节性和长期趋势的模型很好地表示,并且这些模型可用于预测时间序列的未来值。如大数据分析如何使用pandas进行时间序列分析所示,经典的季节性分解就是这种模型的一个简单示例。一个更复杂的示例是Facebook的Prophet模型,该模型使用曲线拟合来分解时间序列,并考虑了多个时间尺度上的季节性,假日影响,突然的变化点和长期趋势,如大数据分析如何使用pandas进行时间序列分析所示。
频率
当时间序列的数据点在时间上均匀间隔(例如,每小时,每天,每月等)时,该时间序列可以与pandas的频率相关联。例如,让我们使用date_range()函数来从创建均匀间隔的日期序列1998-03-10通过1998-03-15在每日频率。
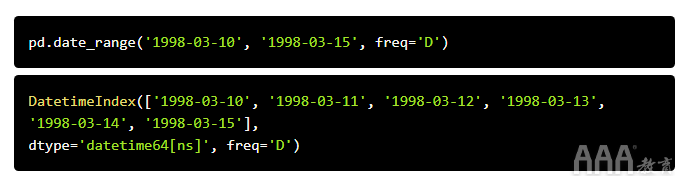
所得的DatetimeIndex具有freq值为的属性'D',指示每日频率。大pandas的可用频率包括每小时('H'),每天('D'),每天('B'),每周('W'),每月('M'),每季度('Q'),每年('A')等。也可以将频率指定为任何基本频率的倍数,例如'5D'每五天一次。
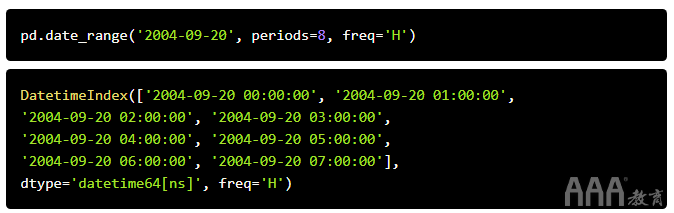
再举一个例子,让我们以每小时的频率创建一个日期范围,指定开始日期和期间数,而不是开始日期和结束日期。
现在,让我们再来看一下opsd_daily时间序列的DatetimeIndex 。
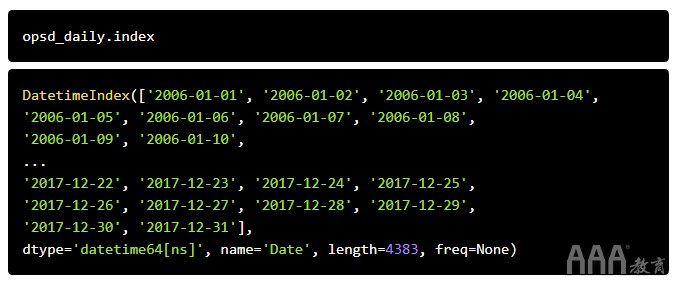
我们可以看到它没有频率(freq=None)。这是有道理的,因为该索引是从CSV文件中的日期序列创建的,而没有为时间序列明确指定任何频率。
如果我们知道我们的数据应处于特定频率,则可以使用DataFrame的asfreq()方法来分配频率。如果数据中缺少任何日期/时间,则将为这些日期/时间添加新行,这些行可以为空(NaN),也可以根据指定的数据填充方法(如正向填充或插值)进行填充。
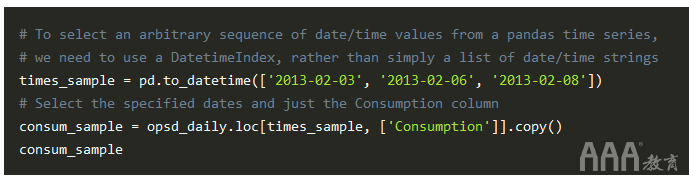
为了了解其工作原理,让我们创建一个新的DataFrame,其中仅包含Consumption2013年2月3日,6日和8日的数据。

现在,我们使用该asfreq()方法将DataFrame转换为每日频率,其中一列用于未填充的数据,一列用于向前填充的数据。
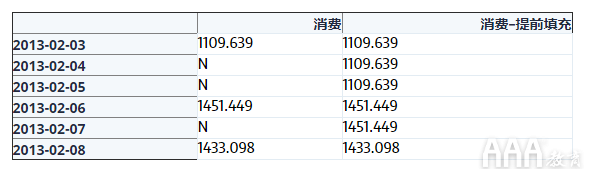
在该Consumption列中,我们有原始数据,NaN对于consum_sampleDataFrame 中缺少的任何日期,其值为。在该Consumption - Forward Fill列中,缺失项已向前填充,这意味着最后一个值将在缺失行中重复,直到出现下一个非缺失值。
如果您要进行任何需要均匀间隔的数据且没有任何遗漏的时间序列分析,则需要使用asfreq()该方法将时间序列转换为指定的频率,并使用适当的方法填充所有遗漏。
重采样
将我们的时间序列数据重新采样到较低或较高的频率通常很有用。重采样到较低的频率(降采样)通常涉及聚合操作-例如,根据每日数据计算每月的销售总额。我们在大数据分析如何使用pandas进行时间序列分析中使用的每日OPSD数据是从原始的每小时时间序列中缩减采样的。重采样到较高频率(上采样)的情况比较少见,并且通常涉及插值或其他数据填充方法,例如,将每小时天气数据插值到10分钟间隔以输入科学模型。
我们将在这里着重于下采样,探索它如何帮助我们在各种时间尺度上分析我们的OPSD数据。我们使用DataFrame的resample()方法,该方法将DatetimeIndex拆分为多个时间段,并按时间段对数据进行分组。该resample()方法返回一个Resampler对象,类似于pandas GroupBy对象。然后,我们可以应用的聚合方法,例如mean(),median(),sum()等,以数据组为每个时间段。
例如,让我们将数据重新采样为每周平均时间序列。
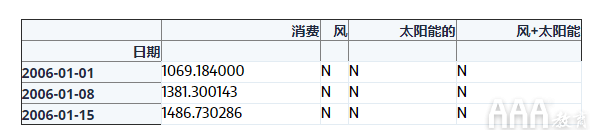
第一行上面,标注2006-01-01,包含了平均中包含的所有的时间块中的数据2006-01-01通过2006-01-07。第二行标记为2006-01-08,包含2006-01-08通过2006-01-14时间仓的平均数据,依此类推。默认情况下,向下采样的时间序列的每一行都标有时间仓的右边缘。
根据构造,我们的每周时间序列的数据点是每日时间序列的1/7。我们可以通过比较两个DataFrame的行数来确认这一点。

让我们Solar一起绘制一个六个月内的每日和每周时间序列,以进行比较。
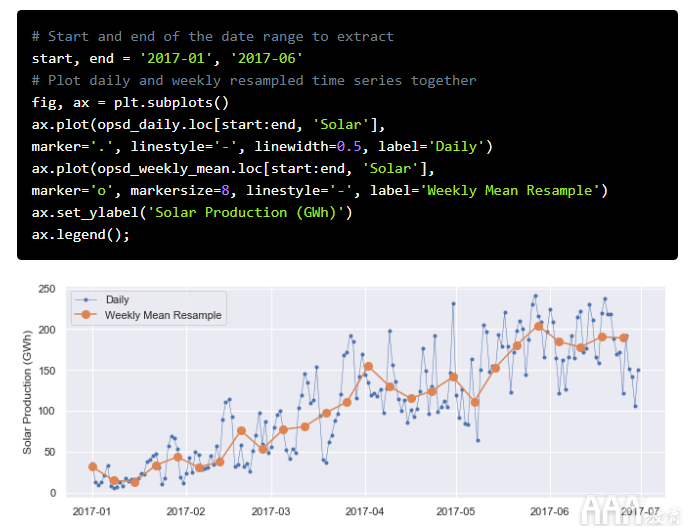
我们可以看到,每周平均时间序列比每日时间序列平滑,这是因为在重采样中平均了较高的频率变异性。
现在,让我们将数据重新采样到每月一次,汇总总和而不是均值。与使用进行聚合mean()(将设置为将NaN所有丢失数据的任何时间段的输出)不同,的默认行为是sum()将输出输出0作为丢失数据的总和。我们使用min_count参数来更改此行为。
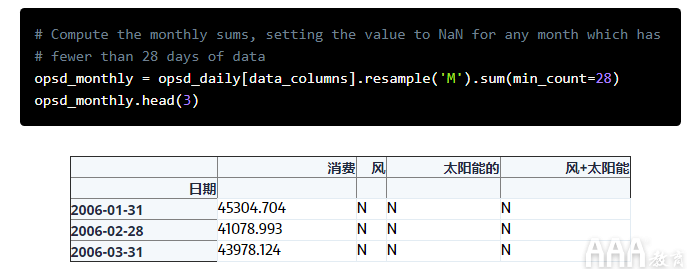
您可能会注意到,每月重新采样的数据标有每个月的月底(右边的条边),而每周重新采样的数据标有左边的条边。默认情况下,对于每月,每季度和每年的频率,重新采样的数据都标记有右侧bin边缘,对于所有其他频率,则标记有左侧bin边缘。可以使用resample()文档中列出的参数来调整此行为和其他各种选项。
现在,通过将用电量绘制为线图,将风能和太阳能发电绘制为堆叠区域图,来探索每月的时间序列。
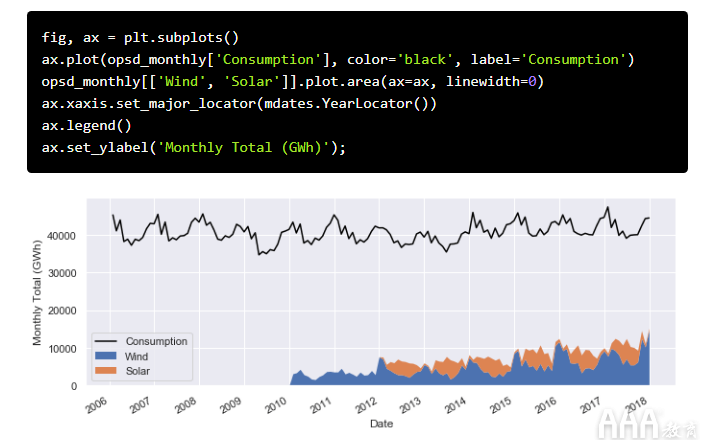
在这个月度时间尺度上,我们可以清楚地看到每个时间序列中的年度季节性,并且很明显,用电量随着时间的推移一直相当稳定,而风电产量一直在稳定增长,其中风能+太阳能发电量不断增加消耗的电力份额。
让我们通过对年度频率重新采样并计算每年的比率Wind+Solar来进一步探索Consumption。
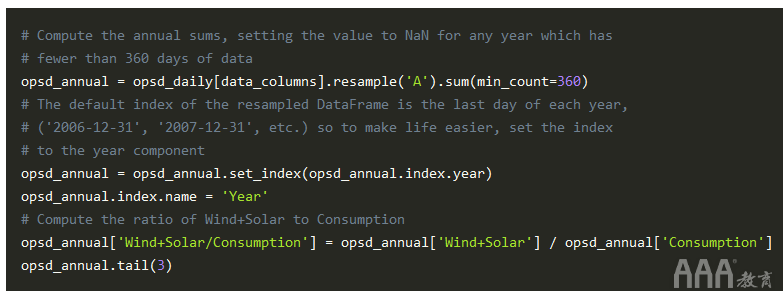
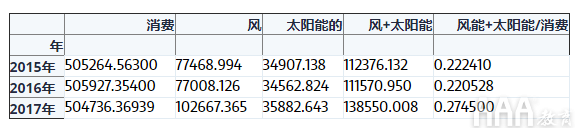
最后,让我们用条形图绘制风电与太阳能在年度用电量中所占的比例。

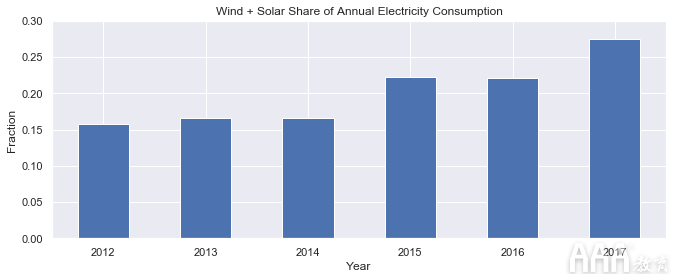
我们可以看到,风能+太阳能生产占年度用电量的比例已从2012年的约15%增长到2017年的约27%。
卷帘窗
滚动窗口操作是时间序列数据的另一个重要转换。类似于下采样,滚动窗口中的数据分成时间窗口和并且在每个窗口中的数据被聚集以如函数mean(),median(),sum()等。然而,不同于下采样,其中,所述时间仓不重叠,并且所述输出是在一个较低的频率与输入频率相比,滚动窗口重叠,并且以与数据相同的频率“滚动”,因此变换后的时间序列与原始时间序列的频率相同。
默认情况下,窗口中的所有数据点在聚合中的权重均相等,但是可以通过指定窗口类型(例如高斯,三角形和其他)来更改此值。我们将在此处继续使用标准的等权重窗口。
让我们使用该rolling()方法来计算每日数据的7天滚动平均值。我们使用center=True参数在每个窗口的中点标记标签,因此滚动窗口为:
1)2006-01-01至2006-01-07-标为2006-01-04
2)2006-01-02至2006-01-08-标为2006-01-05
3)2006-01-03至2006-01-09-标为2006-01-06
4)等等…
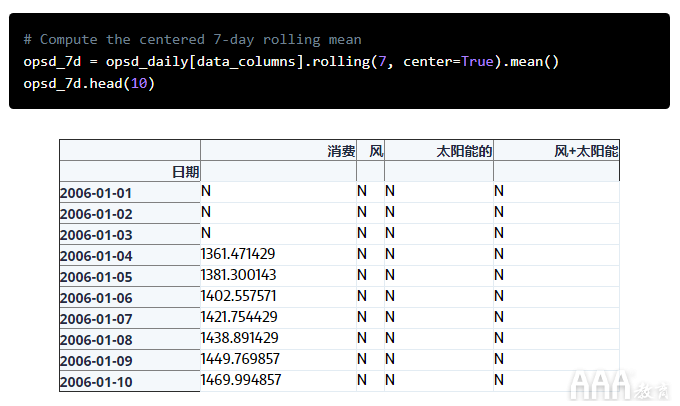
我们可以看到第一个非缺失滚动平均值为on 2006-01-04,因为这是第一个滚动窗口的中点。
为了可视化滚动平均值和重采样之间的差异,让我们更新我们较早的2017年1月至6月太阳能发电量图,以包括7天滚动平均值以及每周平均重采样时间序列和原始每日数据。
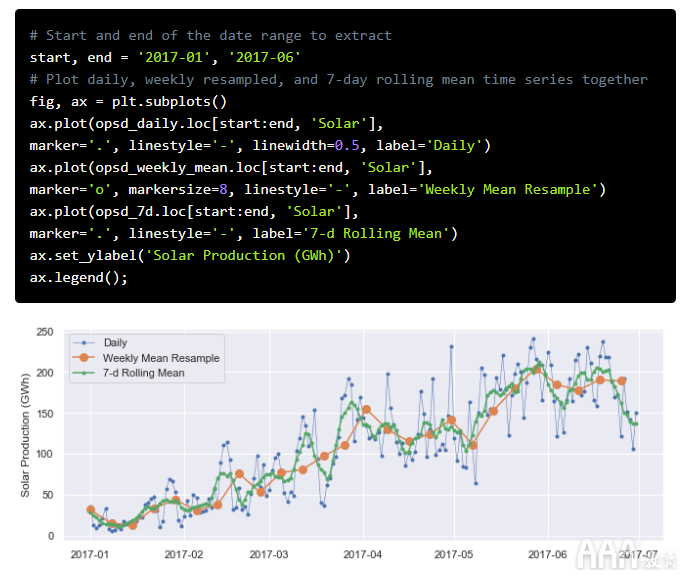
我们可以看到,滚动平均时间序列中的数据点与每日数据具有相同的间隔,但是由于平均了较高的频率可变性,因此曲线更加平滑。在滚动平均时间序列中,高峰和低谷往往与每日时间序列的高峰和低谷紧密对齐。相反,由于重新采样的时间序列具有较粗的粒度,因此每周重新采样的时间序列中的高峰和低谷与每日时间序列的排列不太紧密。
发展趋势
除了较高的频率可变性(例如季节性和噪声)以外,时间序列数据通常还表现出一些缓慢的渐进可变性。可视化这些趋势的一种简单方法是在不同的时间范围内使用滚动方式。
滚动平均值趋向于通过平均远高于窗口大小的频率上的变化并在等于窗口大小的时间尺度上平均任何季节性来平滑时间序列。这允许探索数据中的低频变化。由于我们的用电时间序列具有每周和每年的季节性,因此让我们来看一下这两个时间尺度上的滚动平均值。
我们已经计算了7天的滚动平均值,所以现在让我们计算OPSD数据的365天的滚动平均值。

让我们绘制7天和365天的滚动平均用电量以及每日时间序列。
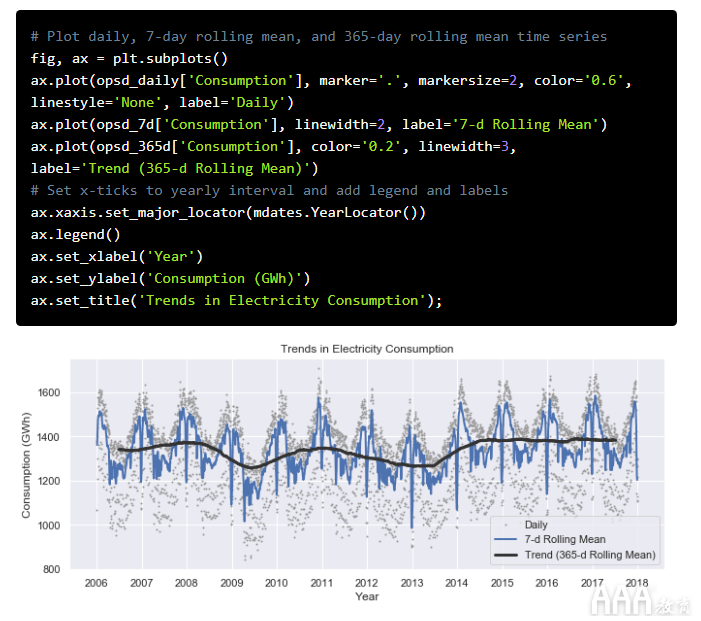
我们可以看到,为期7天的滚动平均值已使所有的每周季节性都变得平滑,同时保留了年度季节性。7天的滚动平均值显示,虽然冬季的用电量通常较高,而夏季则较低,但是每个冬季在12月底和1月初的节假日期间,其用电量会急剧下降数周。
纵观365天的滚动平均时间序列,我们可以看到电力消耗的长期趋势相当平稳,在2009年和2012-2013年之间有几个异常的低电量消耗时期。
现在让我们看一下风能和太阳能生产的趋势。

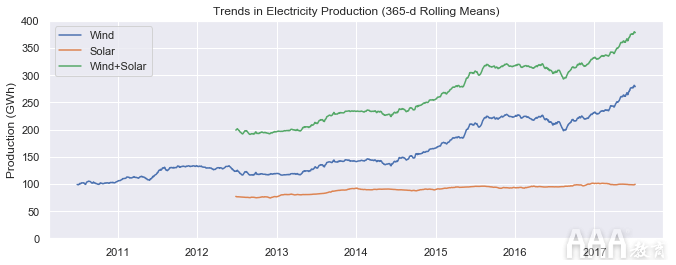
随着德国继续扩大在这些领域的能力,我们可以看到太阳能发电的增长趋势很小,而风力发电的增长趋势很大。
总结和进一步阅读
我们已经学习了如何使用诸如基于时间的索引,重采样和滚动窗口之类的技术来处理,分析和可视化pandas中的时间序列数据。将这些技术应用于我们的OPSD数据集,我们获得了有关德国电力消耗和生产的季节性,趋势和其他有趣特征的见解。
我们尚未涉及的其他潜在有用主题包括时区处理和时移。如果您想了解更多有关在pandas中使用时间序列数据的信息。如果您对使用时间序列数据进行预测和机器学习感兴趣,我们将在以后的文章中介绍这些主题,请继续关注!
填写下面表单即可预约申请免费试听!怕钱不够?可先就业挣钱后再付学费! 怕学不会?助教全程陪读,随时解惑!担心就业?一地学习,可推荐就业!
©2007-2022/ www.aaa-cg.com.cn 北京漫动者数字科技有限公司 备案号: 京ICP备12034770号 监督电话:010-53672995 邮箱:bjaaa@aaaedu.cc

 热门推荐
热门推荐
 UI设计
UI设计
 产品经理
产品经理
 大数据分析
大数据分析
 原画设计
原画设计
 平面设计
平面设计
 新媒体运营
新媒体运营 






