提升技能是成为数据科学家的重要组成部分。刚开始时,您主要侧重于学习编程语言,正确使用第三方工具,显示可视化内容以及对统计算法的理论理解。下一步是在更困难的数据集上测试您的技能。
有时,这些数据集需要大量清理,格式不正确或很难找到。关于理解我们周围数据的重要性,这里有很多内容,但是对于如何实际获取数据却几乎找不到。
随着您成为数据科学家的成长,最初的数据调查,探索和检索是最重要的学习步骤。从多个来源中查找和清理数据集无疑会产生前期成本—但是一旦您拥有了清理,格式正确且易于理解的数据集,回答数据上多个问题的可能性就会大大提高。
在大数据分析如何跟踪迁移模式中,我们将逐步研究,检索和清理现实世界的数据集。为了纪念世界候鸟日,我们将使用候鸟数据。我们还将介绍构建您自己的数据集所涉及的成本收益和必要的工具。有了这些基础知识,您就可以深入研究并找到自己要使用的数据集。
研究可用的候鸟数据集
您应该从一个关键问题开始每次调查:我们要学习什么?有了这个问题,找到合适的数据集就容易了。对于我们的示例,我们想了解北美鸟类的迁徙方式。要了解这些模式,我们需要在几年中找到准确的迁移数据。
很难找到这样的模糊数据。可能会有业余爱好者在个人网站,论坛或其他渠道上托管自己的数据,但是业余数据集通常容易出错并且包含丢失的数据。相反,我们应该寻找在政府或大学网站上托管的更专业的数据集。
搜寻关键字“鸟类迁徙”,“数据库”和“美国”,我们找到了几个有关鸟类迁徙信息的网站。第一个是eBird,包含康奈尔实验室托管的鸟类迁徙数据。第二个是来自美国鱼类和野生动物服务(USFWS)网站,该网站使用合作伙伴关系和公民研究数据来创建报告。我们希望使用两种服务的数据集,以便我们可以交叉检查数据并确定不一致之处。
让我们从eBirds数据集开始。
导航到下载页面,系统将要求您在康奈尔研究实验室创建一个帐户。登录后,您可以进入下载页面。但是在访问完整的数据集之前,您需要填写一张表格,描述您打算如何使用数据。我们成功填写了表格并等待了几天,然后才能完全访问数据集。需要时间,但不太困难。
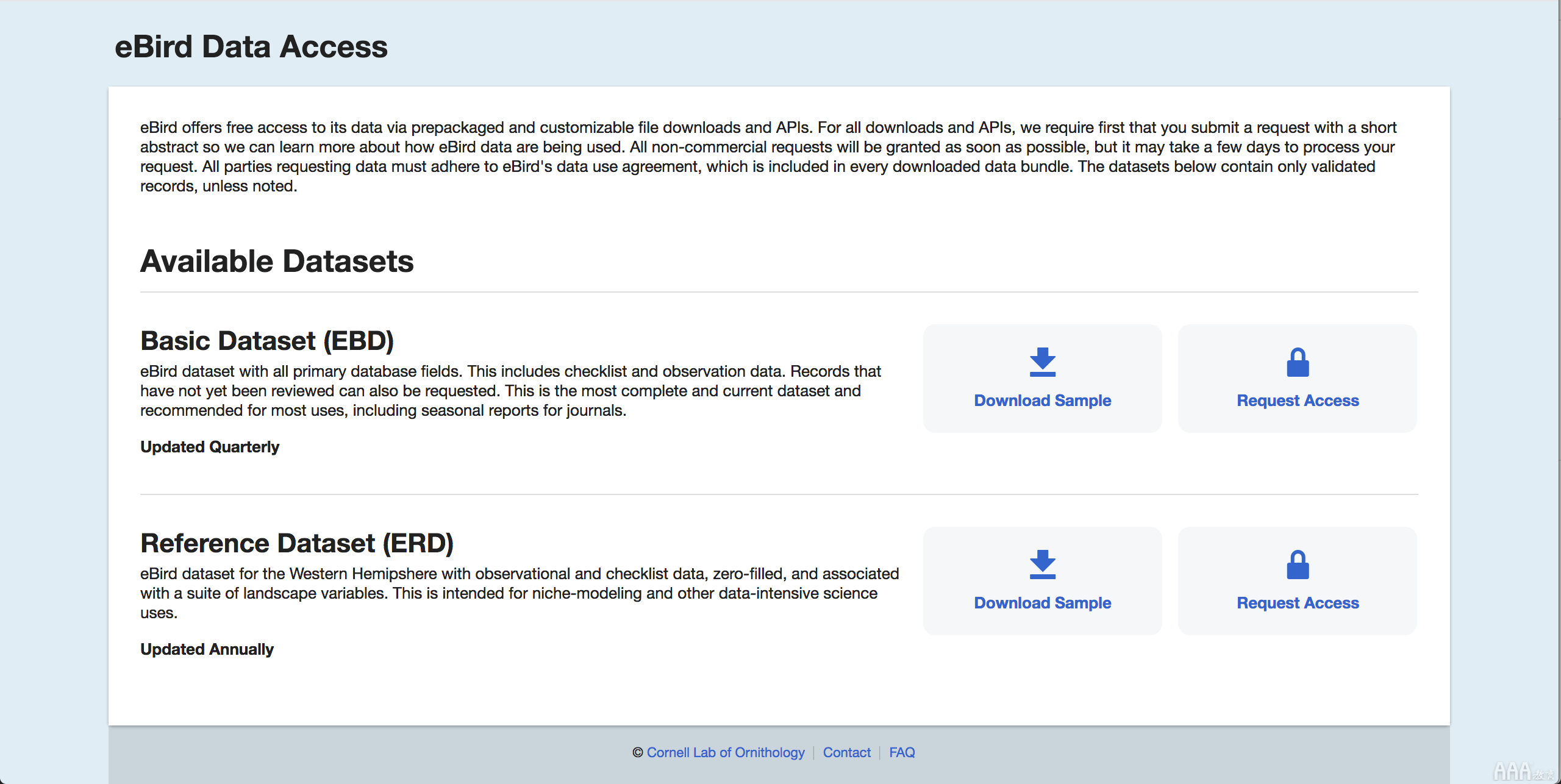
接下来,让我们看一下USFWS。乍一看,该网站似乎比eBirds门户网站容易使用得多。有一个明确的链接可以指导我们找到完整的数据库列表,其中包含不同的鸟类,地理数据点和迁徙飞行路线。如果它们具有有效的链接,则这些井井有条且经过分类的数据集将非常有帮助且易于分析。

不幸的是,从USFWS门户检索数据并不容易。有多个无效链接,格式不正确的数据集以及无法按所宣传的那样运行的HTML按钮。尽管这些问题大多是不良的界面设计,但所有HTTP端点似乎都可以正常运行,并且只需使用少量Python代码,我们就会发现我们能够获取所需的数据。
查找数据
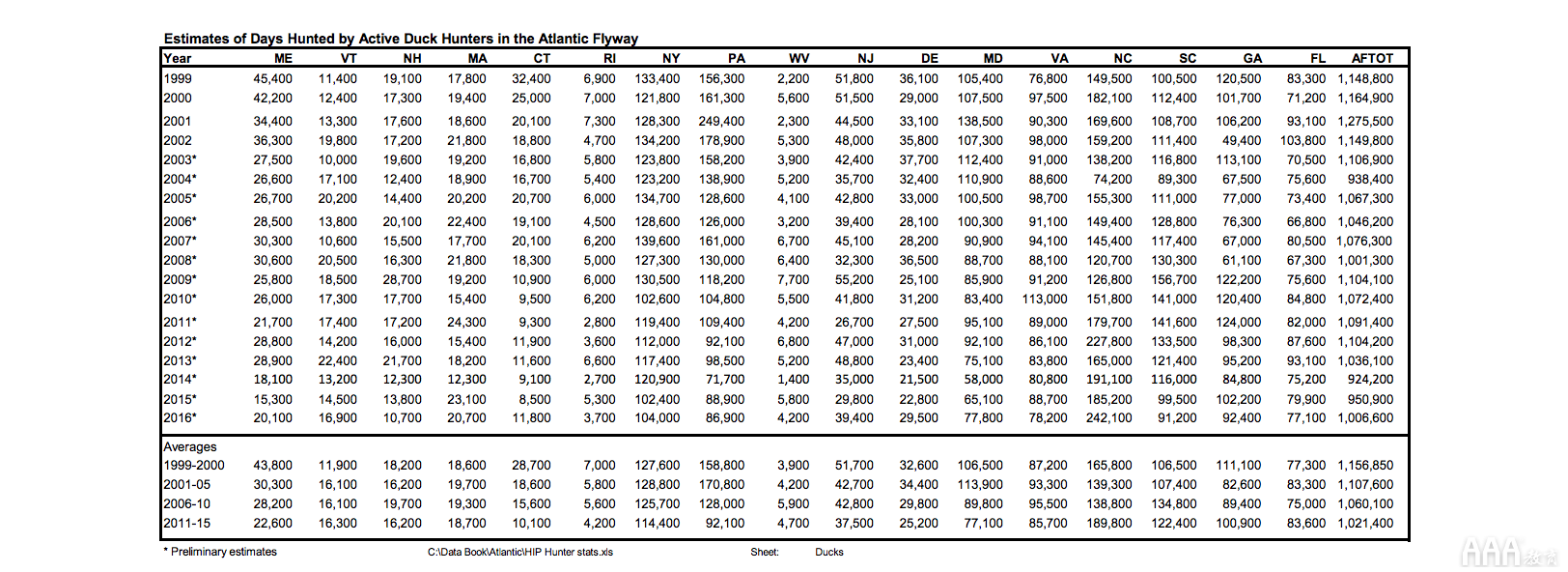
由于USFWS网站提供的链接数量众多,很难仅找到可能的数据集端点。当我们潜入时,我们发现的第一个成功数据集是通过链接到USFWS发布的水禽飞行方式数据手册。该数据手册据说包含了我们进行调查所需的所有信息,但存在一个主要缺陷:它以PDF格式存储。由于PDF的结构不一致,因此很难解析它们,因此这应该是最后的选择。
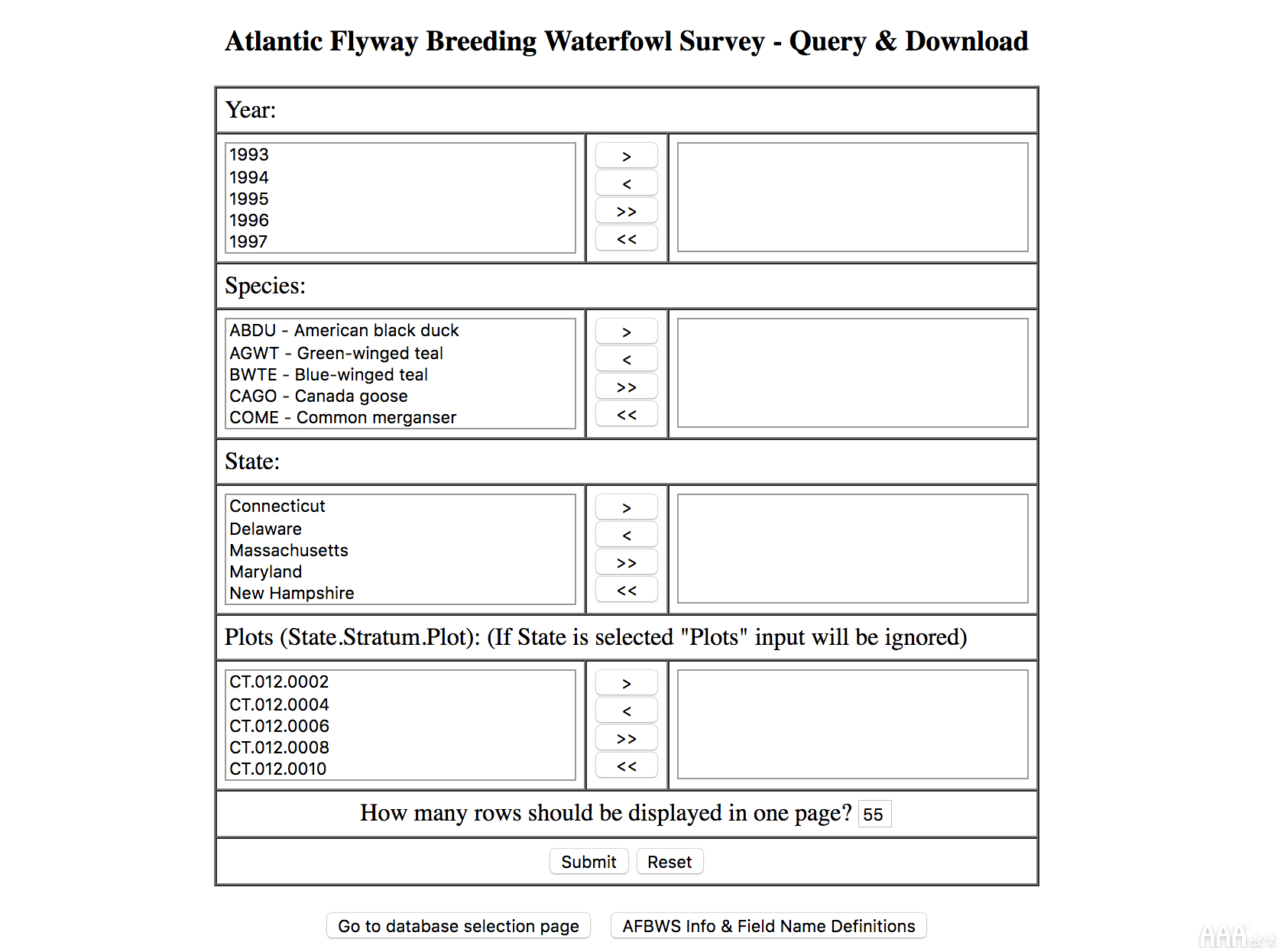
致力于水鸟飞行路线模式的数据集,我们决定遵循另一条链接到USFWS报告的路径。这些报告被描述为1995年以来有关北美水禽飞行路线模式的调查数据。正是我们想要的。单击报告的链接后,我们将看到服务条款和免责声明阻止程序。接受后,有一个报告生成表格,使研究人员能够限制有关水禽类型,状态或发现该水禽的“图”的数据。
而不是限制数据,我们选择表单中的每个值,然后按提交。最后,我们向您展示了一个分页表格,其中包含完整数据集的样本。
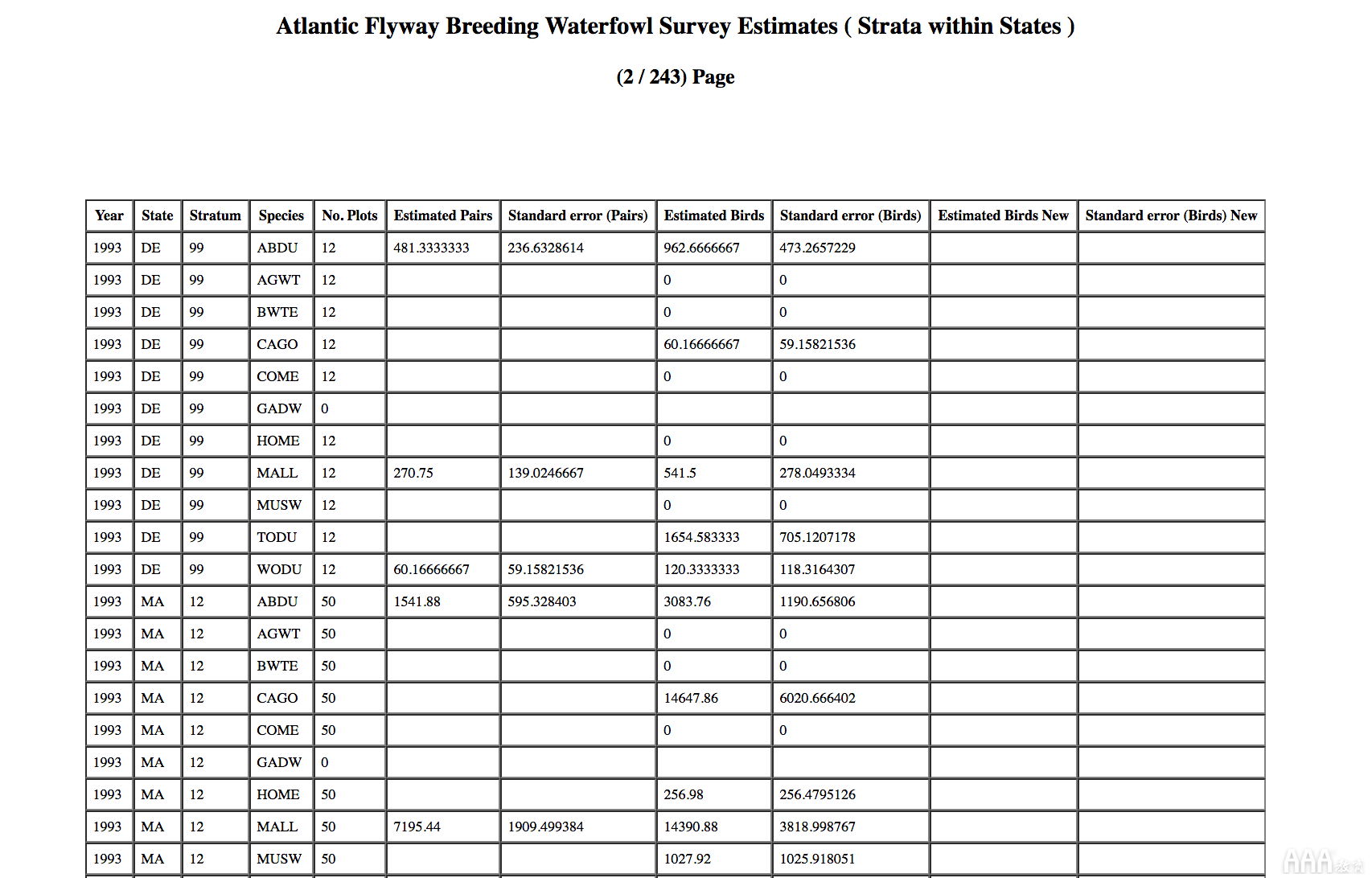
滚动到页面底部,还有整个数据集的下载按钮!不幸的是,按下按钮会将我们重定向到403 Unauthorized页面。
有点沮丧,但并非没有希望,我们正在寻找解决方案。首先,我们追溯为检索数据而采取的步骤。这些步骤是导航到下载页面,提交简单的表单提交,解析HTML格式的表并在数据的每一页上运行解析器。考虑这些步骤,我们意识到可以使用Python网络抓取脚本轻松地将它们自动化!
下载数据
我们将使用两个主要包来抓取数据。
1)请求(用于发出HTTP请求)
2)beautifulsoup(用于解析HTML)
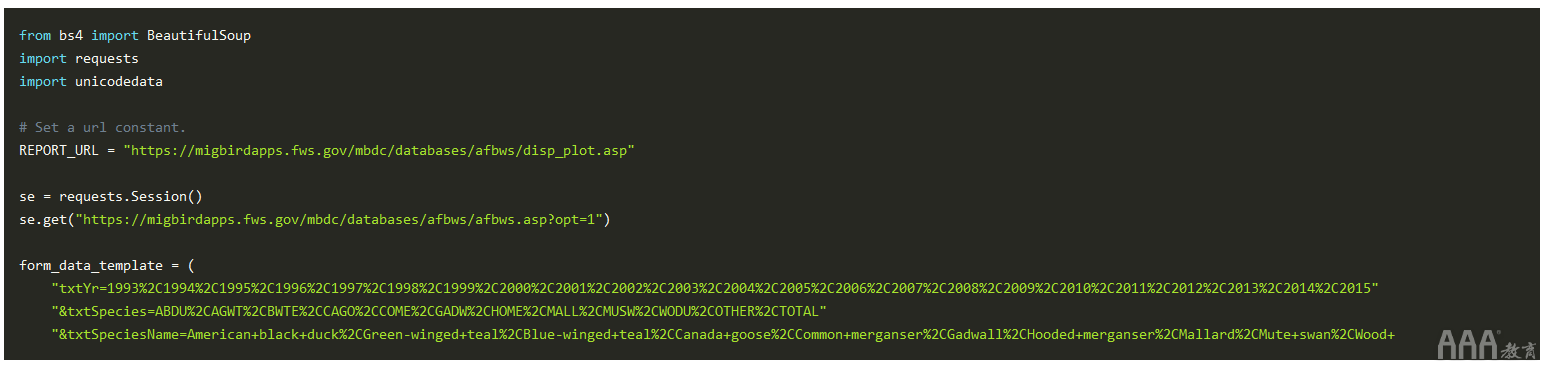
首先,requests执行HTTP请求,表单提交和下载HTML表文件。使用Chrome Dev Tools,我们将导航到调查表单页面,并填写表单中的所有值,然后按下Submit按钮,然后检查请求的标题。
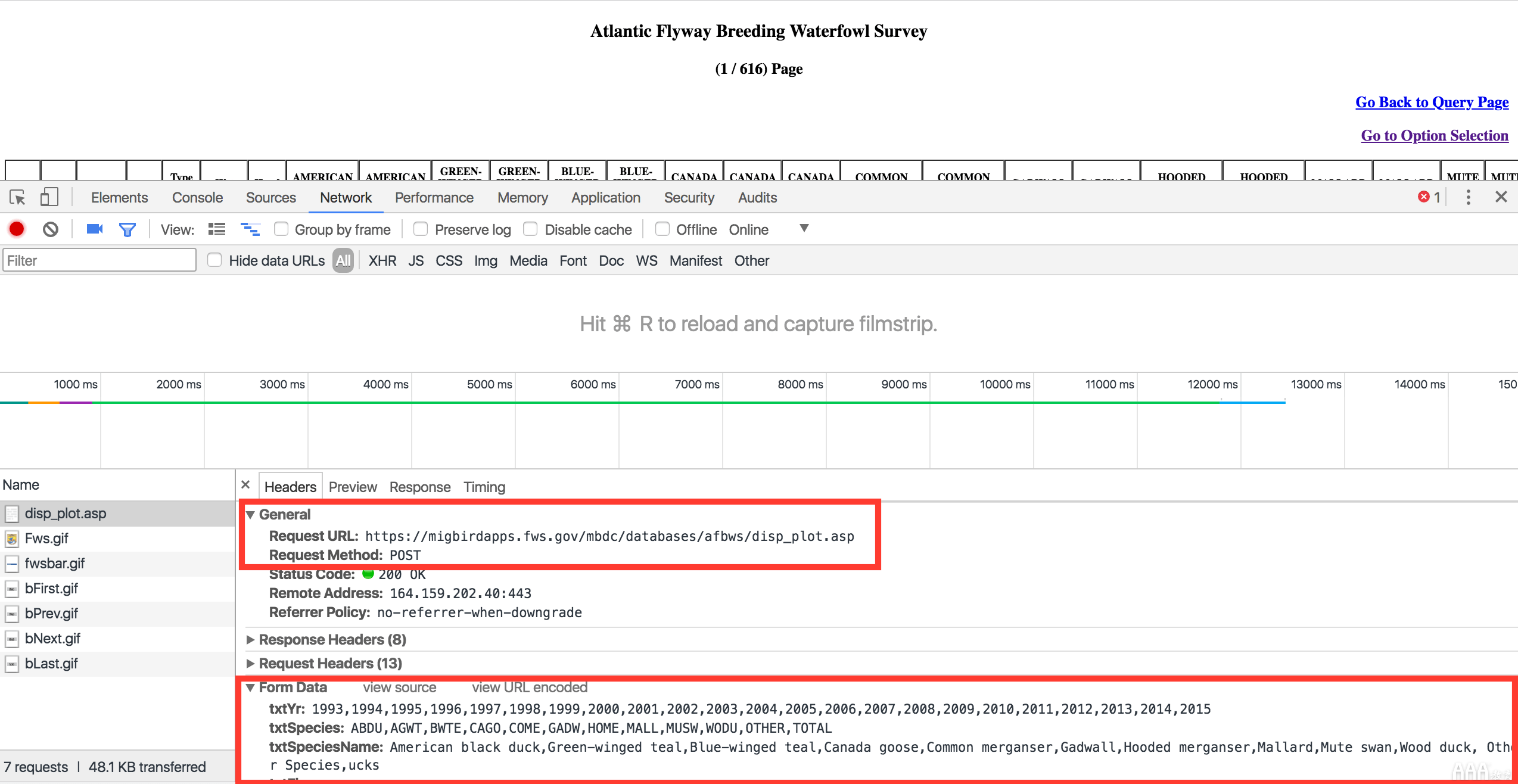
我们分别突出显示了请求类型,URL和表单数据的字段。从屏幕截图中,要生成报告,我们需要使用给定的表单数据将POST请求发送到URL。为了使事情变得简单,我们将使用URL编码的表单数据源代码。然后,我们将使用以下代码段使用和内容类型标头来发出POST请求。requests.post()x-www-form-urlencoded
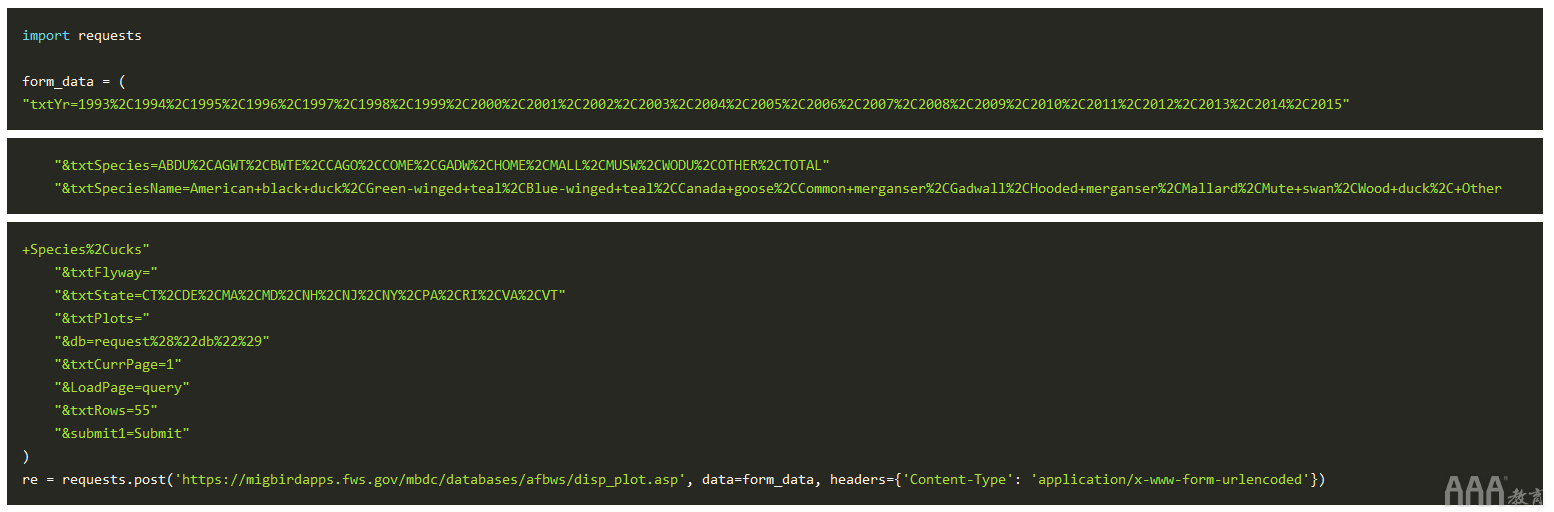
这种感觉是正确的,但是我们缺少的重要组成部分,我们才能发出请求。如果要运行该代码段,那么我们的请求将被所需的条款和条件页面阻止,而不是返回报告。回想一下,USFWS要求您在使用数据之前接受其免责声明。
要解决此问题,请注意,在接受条款和条件时,您的浏览会话拥有对其余报告的完全访问权限。要在Python脚本中重新创建此行为,我们需要实例化一个持久requests.Session对象。使用该requests.Session对象,我们将导航到“接受”页面来接受免责声明,并且在经过身份验证的会话中,我们将提交表单数据。
总之,它看起来像:
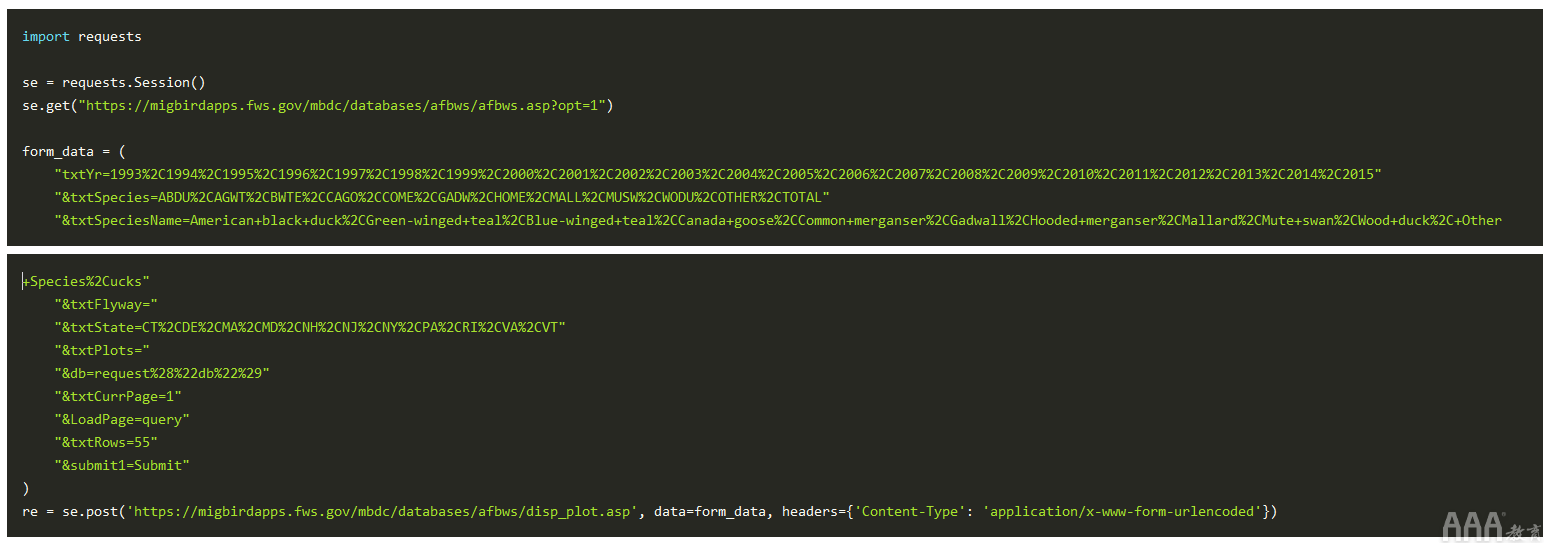
成功!我们根据需要获得了报告表,但是请注意,有616页的数据要解析。我们可以减少数量的一种方法是选择更多数量的textRows表单值。让我们将其更改为每个表99行的最大值。
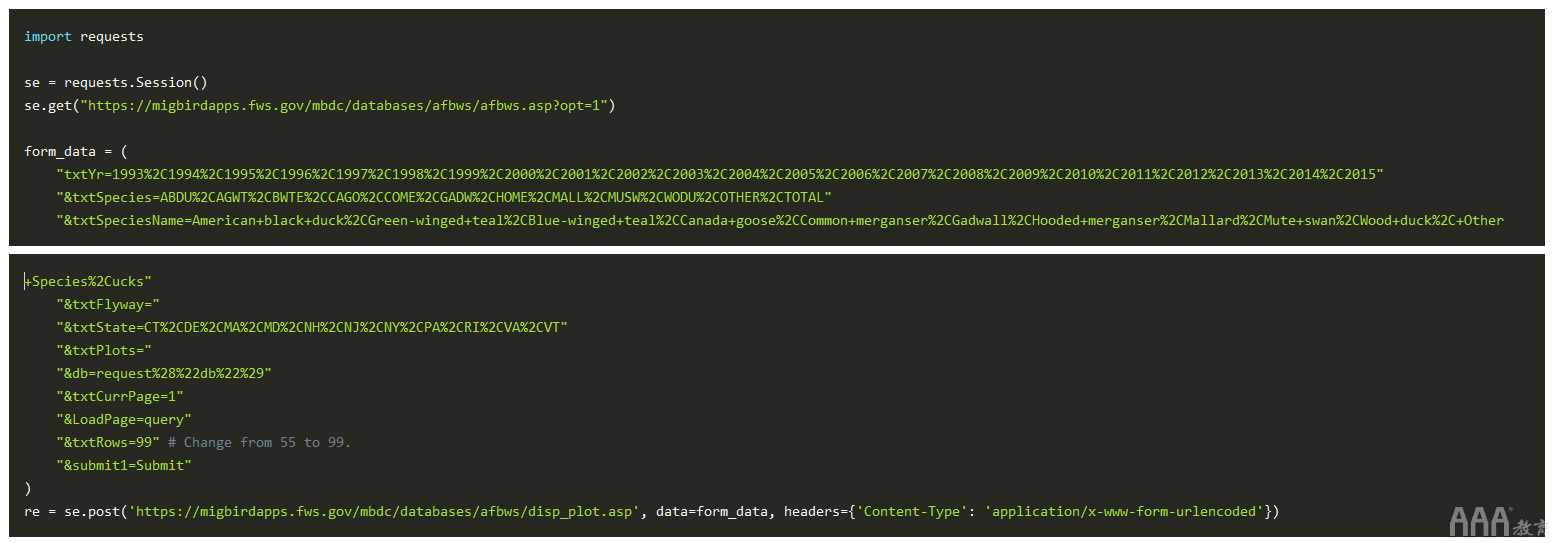
现在我们已拥有每页的最大行数,我们可以转到HTML解析步骤。
解析数据
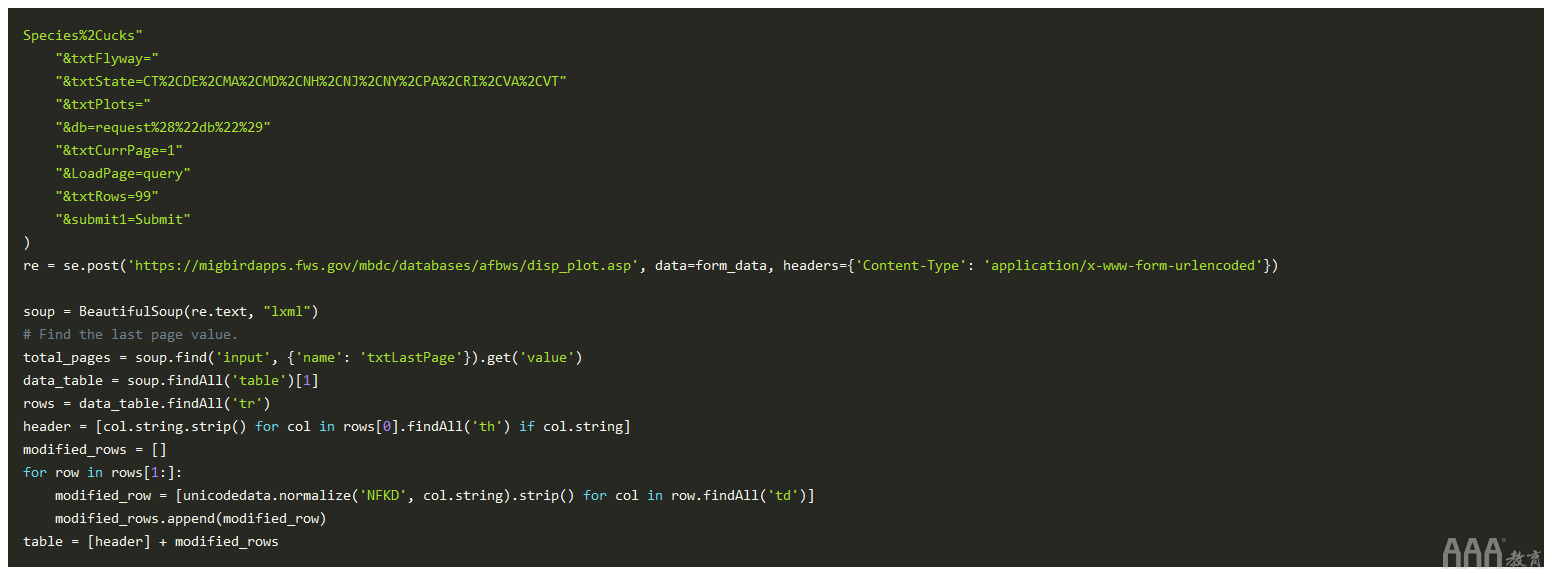
要解析数据,我们需要BeautifulSoup使用报告响应HTML字符串创建一个对象。在后台,该BeautifulSoup对象将HTML字符串转换为树状数据结构。这样可以轻松查询诸如包含报告数据的标签之类的标签。
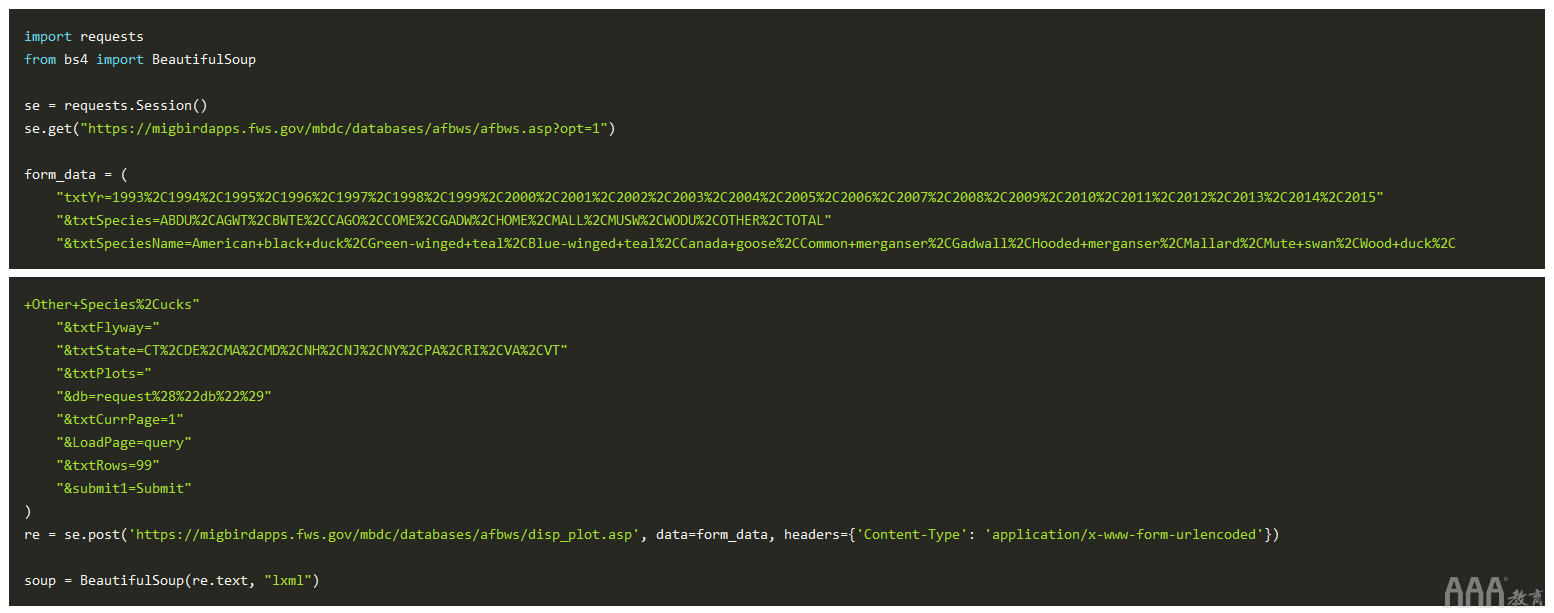
使用我们的可分析对象,我们现在可以在HTML文档中搜索该标记。在文档中,报告数据在第二个中,因此我们将使用该.findAll()方法并在列表中选择第二个项目。然后,我们将过滤表的所有行,并将它们设置为rows变量。

接下来,我们要提取标题行并清理值。作为参考,HTML表格的标题行使用标记格式化,数据行使用格式化。要获取标签值,我们需要调用标签的.string属性BeautifulSoup。我们将从表的第一行中获取标头值。
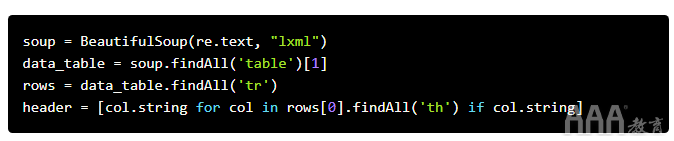
提取标题后,就该从行中获取数据了。我们将遍历该表的各行,找到所有标签,并将其分配给新行。此外,我们将合并标题和行,然后清理一些空白值,以使其更易于解析。
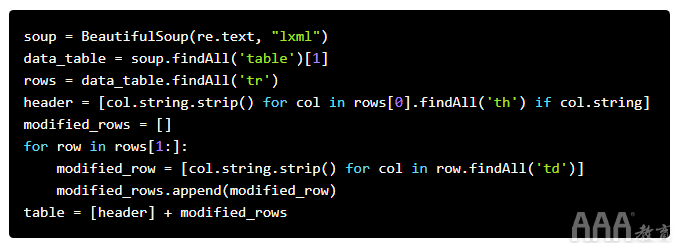
使用进行更多的unicode清理后unicodedata.normalize(),我们应该获得以下输出:

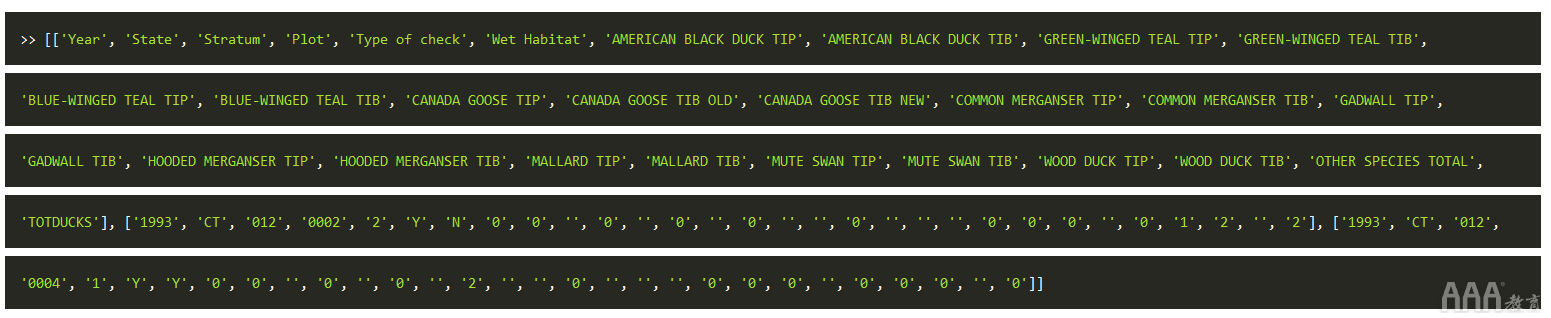
解析表之后,我们可以遍历数据集的每一页并将值组合在一起。
放在一起
在构建完整的数据集之前,尚需实现三个部分:
1)查找要分页的数据总页数。
2)创建一个form_data模板以动态修改表单数据。
3)循环浏览页面并合并所有行。
我们将从第一点开始。窥视报告页面的HTML,我们看到总页数在标题中。我们可以从标题中提取总数的一种方法是从标题中分离数字,然后将其转换为整数。这是可行的,但是依靠标题字符串的解决方案太脆弱了。
相反,如果我们仔细查看表单数据,则会有一个隐藏的输入字段为我们完成工作。在标记的底部,带有的输入值name=txtLastPage。使用BeautifulSoup,我们只需搜索输入标签和匹配名称,然后将值转换为整数。这是一个潜在的实现。

现在,我们要一起添加模板和分页。首先,我们将创建一个字符串模板,该模板form_data使用字符串格式提交动态表单数据。在我们的情况下,我们要动态修改当前页面值。接下来,我们将找到使用页面总数的值并保持循环,直到我们学会了数据集。经过一点清理,我们得到以下最终实现:
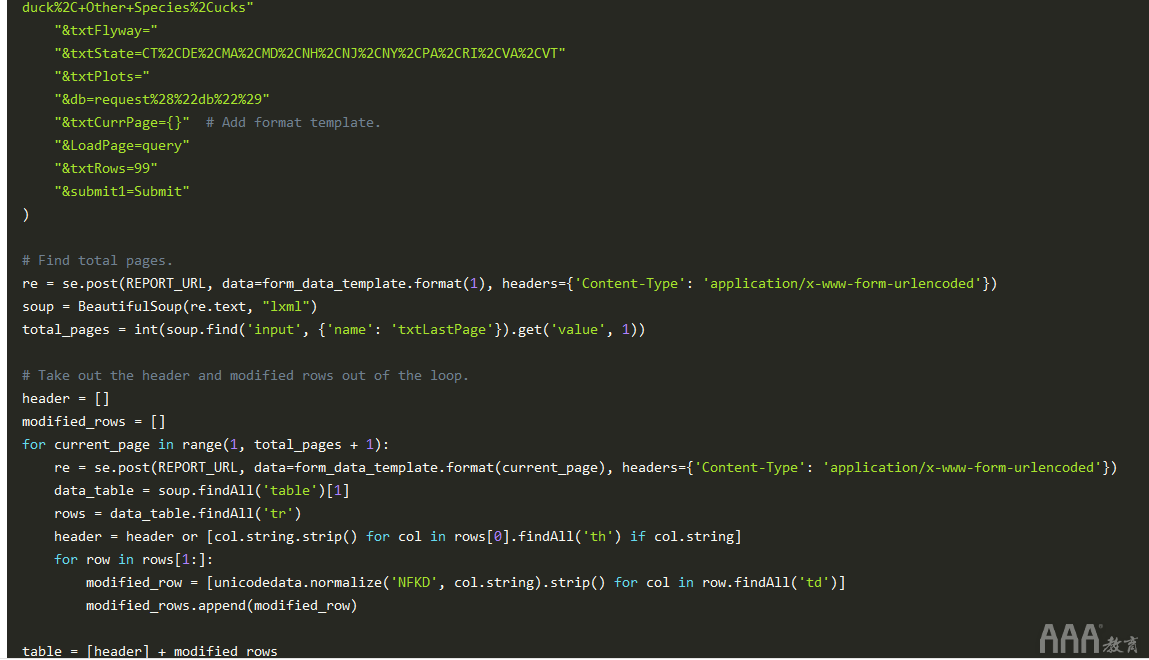
太棒了!我们已经提取了完整的数据集,并且它也处于Python可读状态。从这里,我们可以添加更多数据清理功能,将表保存到文件中,并对数据进行一些分析。
结论
使用一些基本的Python Web抓取,我们能够:
1)使用会话访问仅经过身份验证的内容。
2)解析HTML表格数据并将其映射到Python列表列表。
3)跨多个HTML页面自动抓取数据集。
从这个例子中,我们能够证明Python的Web抓取能力,用于数据调查,清理和检索。如文章开头所述,在询问数据科学中更困难的问题时,您需要查找自己的数据集。网络上有大量可用数据。一旦您拥有查找和收集此数据的工具和经验,您将在分析中获得很高的回报。
如果您想更新示例,请添加以下内容:
1)使用表数据创建一个CSV文件。
2)使用协程或线程加快网络呼叫的阻塞。
3)循环浏览页面,而不必两次请求第一页。
4)添加错误处理以提高代码的健壮性。
填写下面表单即可预约申请免费试听!怕钱不够?可先就业挣钱后再付学费! 怕学不会?助教全程陪读,随时解惑!担心就业?一地学习,可推荐就业!
©2007-2022/ www.aaa-cg.com.cn 北京漫动者数字科技有限公司 备案号: 京ICP备12034770号 监督电话:010-53672995 邮箱:bjaaa@aaaedu.cc

 热门推荐
热门推荐
 UI设计
UI设计
 产品经理
产品经理
 大数据分析
大数据分析
 原画设计
原画设计
 平面设计
平面设计
 新媒体运营
新媒体运营 






